Редакция 1
smb.conf Fileproc File SystemDHCP, BIND, Apache HTTP Server, Postfix, Sendmail и других серверов и программ корпоративного класса
kdump
/etc/sysconfig/network-scripts/ directory. Read this chapter for information how to use these files to configure network interfaces.
systemctl utility.
sshd service, as well as a basic usage of the ssh, scp, sftp client utilities. Read this chapter if you need a remote access to a machine.
rsyslog daemon, and explains how to locate, view, and monitor log files. Read this chapter to learn how to work with log files.
cron, at, and batch utilities. Read this chapter to learn how to use these utilities to perform automated tasks.
rpm command instead of yum. Read this chapter if you cannot update a kernel package with the Yum package manager.
kdump service in Fedora, and provides a brief overview of how to analyze the resulting core dump using the crash debugging utility. Read this chapter to learn how to enable kdump on your system.
rpm utility. Read this appendix if you need to use rpm instead of yum.
/etc/sysconfig/ directory. Read this appendix if you want to learn more about these files and directories, their function, and their contents.
proc file system (that is, the /proc/ directory). Read this appendix if you want to learn more about this file system.
Моноширинный жирный шрифт
Чтобы просмотреть содержимое файлаmy_next_bestselling_novelв текущем каталоге, в строке приглашения оболочки введитеcat my_next_bestselling_novelи нажмите Enter для выполнения этой команды.
Нажмите Enter для исполнения команды.Нажмите Ctrl+Alt+F2 для перехода в первый виртуальный терминал. Нажмите Ctrl+Alt+F1 , чтобы вернуться в сессию X-Windows.
Классы файлов включаютfilesystemдля файловых систем,fileдля файлов,dirдля каталогов. Каждому классу соответствует набор разрешений.
В главном меню выберите → → для запуска утилиты Настройки мыши. На вкладке Кнопки установите флажок Настроить мышь под левую руку и нажмите кнопку , чтобы настроить мышь для левши.Чтобы вставить специальный символ в файл gedit, выберите → → . Затем в меню выберите → , введите имя символа и нажмите кнопку . Найденный символ будет выделен в таблице символов. Дважды щелкните на этом символе, чтобы вставить его в поле Текст для копирования и нажмите кнопку . Теперь вернитесь к вашему документу и в меню выберите → .
Моноширинный жирный курсивпропорциональный жирный курсив
Для подключения к удаленной машине с помощью SSH в строке приглашения выполнитеssh. Скажем, имя удаленной машины –имя_пользователя@имя_доменаexample.com, а ваше имя пользователя – john, тогда команда будет выглядеть так:ssh john@example.com.Командаmount -o remountповторно подключит заданную файловую систему. Например, дляфайловая_система/homeкоманда будет выглядеть так:mount -o remount /home.Чтобы просмотреть версию установленного пакета, выполните командуrpm -q. Результат команды будет представлен в форматепакет.пакет-версия-выпуск
Publican — система публикации DocBook.
моноширинный шрифт:
books Desktop documentation drafts mss photos stuff svn books_tests Desktop1 downloads images notes scripts svgs
моноширинный шрифт:
package org.jboss.book.jca.ex1; import javax.naming.InitialContext; public class ExClient { public static void main(String args[]) throws Exception { InitialContext iniCtx = new InitialContext(); Object ref = iniCtx.lookup("EchoBean"); EchoHome home = (EchoHome) ref; Echo echo = home.create(); System.out.println("Created Echo"); System.out.println("Echo.echo('Hello') = " + echo.echo("Hello")); } }
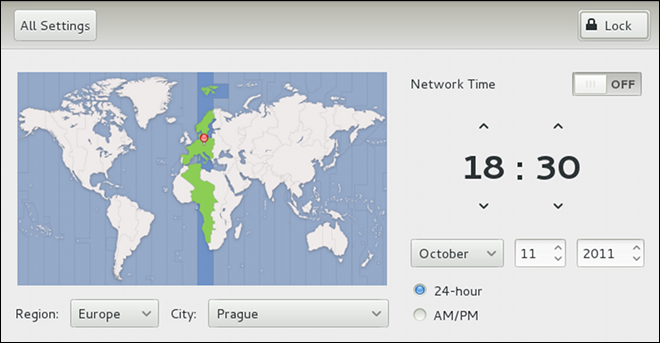
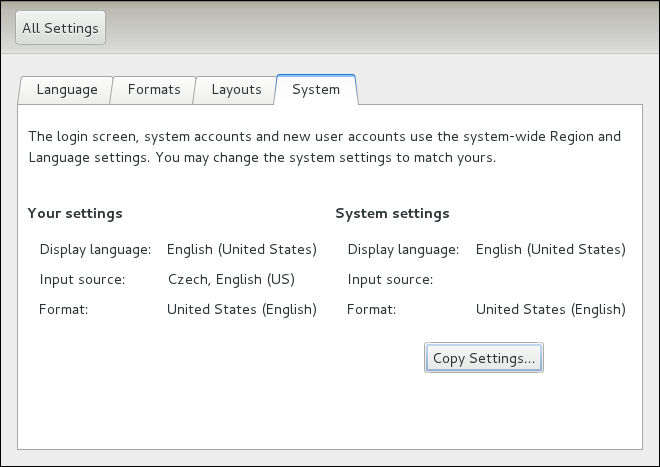
root is allowed to set the system date and time. To unlock the configuration tool for changes, click the button in the top-right corner of the window, and provide the correct password when prompted.
root:
date +%D -s YYYY-MM-DDYYYY is a four-digit year, MM is a two-digit month, and DD is a two-digit day of the month. For example, to change the date to 2 June 2010, type:
~]# date +%D -s 2010-06-02date without any additional argument.
root:
date +%T -s HH:MM:SSHH stands for an hour, MM is a minute, and SS is a second, all typed in a two-digit form. If your system clock is set to use UTC (Coordinated Universal Time), also add the following option:
date +%T -s HH:MM:SS -u~]# date +%T -s 23:26:00 -udate without any additional argument.
ntpdate command in the following form:
ntpdate -q server_address0.fedora.pool.ntp.org, type:
~]$ ntpdate -q 0.fedora.pool.ntp.org
server 204.15.208.61, stratum 2, offset -39.275438, delay 0.16083
server 69.65.40.29, stratum 2, offset -39.269122, delay 0.17191
server 148.167.132.201, stratum 2, offset -39.270239, delay 0.20482
17 Oct 17:41:09 ntpdate[10619]: step time server 204.15.208.61 offset -39.275438 secroot, run the ntpdate command followed with one or more server addresses:
ntpdate server_address…~]# ntpdate 0.fedora.pool.ntp.org 1.fedora.pool.ntp.org
17 Oct 17:42:13 ntpdate[10669]: step time server 204.15.208.61 offset -39.275436 secdate command with no additional arguments.
root:
systemctl enable ntpdate.service/var/log/boot.log system log, try to add the following line to /etc/sysconfig/network:
NETWORKWAIT=1
ntpd daemon to synchronize the time at boot time automatically:
root, open the NTP configuration file /etc/ntp.conf in a text editor, creating a new one if it does not already exist.
server 0.fedora.pool.ntp.org iburst server 1.fedora.pool.ntp.org iburst server 2.fedora.pool.ntp.org iburst
iburst directive is added at the end of each server line.
restrict default kod nomodify notrap nopeer noquery restrict -6 default kod nomodify notrap nopeer noquery restrict 127.0.0.1 restrict -6 ::1
systemctl restart ntpd.servicentpd daemon is started at boot time:
systemctl enable ntpd.servicedate(1) — The manual page for the date utility.
ntpdate(8) — The manual page for the ntpdate utility.
ntpd(8) — The manual page for the ntpd service.
root, and access permissions can be changed by both the root user and file owner.
/etc/bashrc file. Traditionally on UNIX systems, the umask is set to 022, which allows only the user who created the file or directory to make modifications. Under this scheme, all other users, including members of the creator's group, are not allowed to make any modifications. However, under the UPG scheme, this «group protection» is not necessary since every user has their own private group.
/etc/passwd file to /etc/shadow, which is readable only by the root user.
/etc/login.defs file to enforce security policies.
/etc/shadow file, any commands which create or modify password aging information do not work. The following is a list of utilities and commands that do not work without first enabling shadow passwords:
chage utility.
gpasswd utility.
usermod command with the -e or -f option.
useradd command with the -e or -f option.
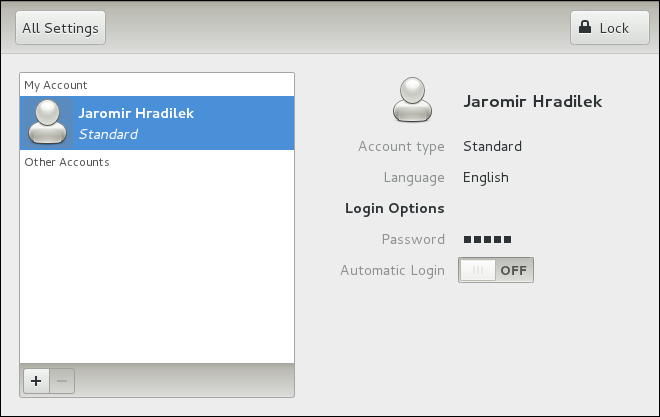
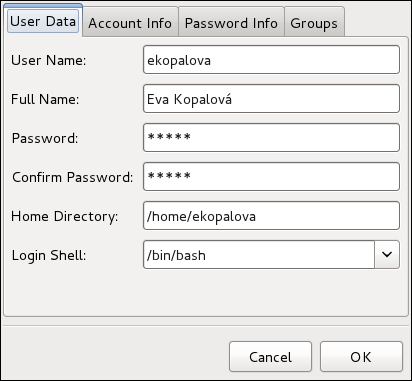
root user is allowed to configure users and groups. To unlock the configuration tool for all kinds of changes, click the button in the top-right corner of the window, and provide the correct password when prompted.
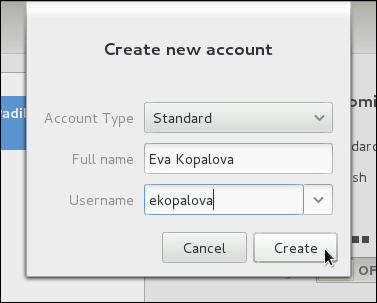
Administrator and Standard (the default option).
/etc/skel/ directory into the new home directory.
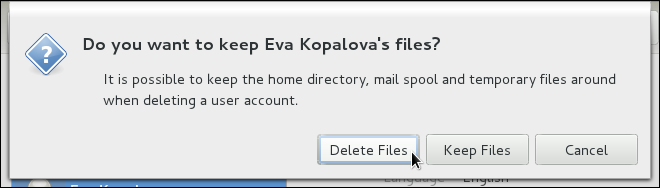
system-config-users at a shell prompt. Note that unless you have superuser privileges, the application will prompt you to authenticate as root.
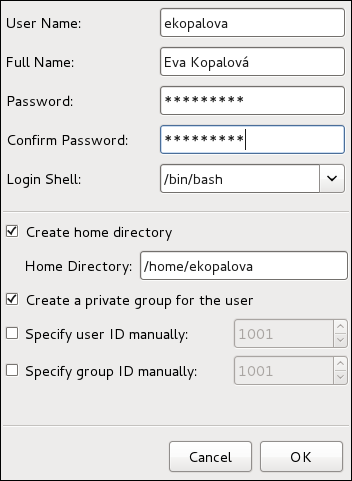
/home/username/. You can choose not to create the home directory by clearing the Create home directory check box, or change this directory by editing the content of the Home Directory text box. Note that when the home directory is created, default configuration files are copied into it from the /etc/skel/ directory.
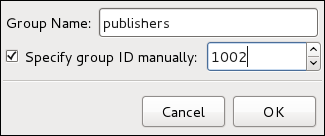
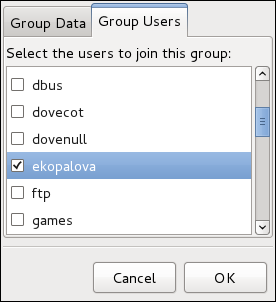
| Utilities | Description |
|---|---|
useradd, usermod, userdel
| Standard utilities for adding, modifying, and deleting user accounts. |
groupadd, groupmod, groupdel
| Standard utilities for adding, modifying, and deleting groups. |
gpasswd
|
Standard utility for administering the /etc/group configuration file.
|
pwck, grpck
| Utilities that can be used for verification of the password, group, and associated shadow files. |
pwconv, pwunconv
| Utilities that can be used for the conversion of passwords to shadow passwords, or back from shadow passwords to standard passwords. |
root:
useradd[options]username
options are command line options as described in Таблица 3.2, «useradd command line options».
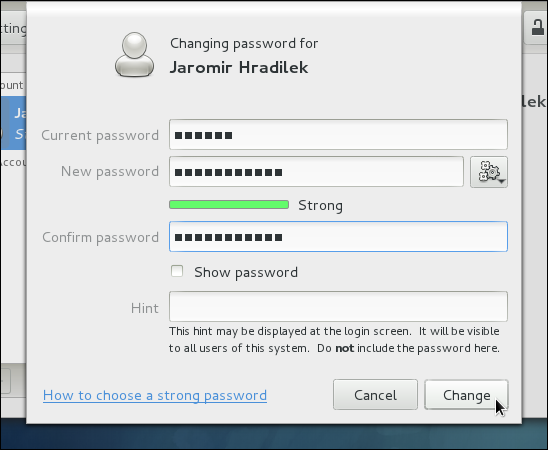
useradd command creates a locked user account. To unlock the account, run the following command as root to assign a password:
passwdusername
| Option | Description |
|---|---|
-c 'comment'
|
comment can be replaced with any string. This option is generally used to specify the full name of a user.
|
-d home_directory
|
Home directory to be used instead of default /home/.
|
-e date
| Date for the account to be disabled in the format YYYY-MM-DD. |
-f days
|
Number of days after the password expires until the account is disabled. If 0 is specified, the account is disabled immediately after the password expires. If -1 is specified, the account is not be disabled after the password expires.
|
-g group_name
| Group name or group number for the user's default group. The group must exist prior to being specified here. |
-G group_list
| List of additional (other than default) group names or group numbers, separated by commas, of which the user is a member. The groups must exist prior to being specified here. |
-m
| Create the home directory if it does not exist. |
-M
| Do not create the home directory. |
-N
| Do not create a user private group for the user. |
-p password
|
The password encrypted with crypt.
|
-r
| Create a system account with a UID less than 1000 and without a home directory. |
-s
|
User's login shell, which defaults to /bin/bash.
|
-u uid
| User ID for the user, which must be unique and greater than 999. |
useradd juan is issued on a system that has shadow passwords enabled:
juan is created in /etc/passwd:
juan:x:501:501::/home/juan:/bin/bash
juan.
x for the password field indicating that the system is using shadow passwords.
juan is set to /home/juan/.
/bin/bash.
juan is created in /etc/shadow:
juan:!!:14798:0:99999:7:::
juan.
!!) appear in the password field of the /etc/shadow file, which locks the account.
-p flag, it is placed in the /etc/shadow file on the new line for the user.
juan is created in /etc/group:
juan:x:501:
/etc/group has the following characteristics:
juan.
x appears in the password field indicating that the system is using shadow group passwords.
juan in /etc/passwd.
juan is created in /etc/gshadow:
juan:!::
juan.
!) appears in the password field of the /etc/gshadow file, which locks the group.
juan is created in the /home/ directory:
~]# ls -l /home
total 4
drwx------. 4 juan juan 4096 Mar 3 18:23 juanjuan and group juan. It has read, write, and execute privileges only for the user juan. All other permissions are denied.
/etc/skel/ directory (which contain default user settings) are copied into the new /home/juan/ directory:
~]# ls -la /home/juan
total 28
drwx------. 4 juan juan 4096 Mar 3 18:23 .
drwxr-xr-x. 5 root root 4096 Mar 3 18:23 ..
-rw-r--r--. 1 juan juan 18 Jun 22 2010 .bash_logout
-rw-r--r--. 1 juan juan 176 Jun 22 2010 .bash_profile
-rw-r--r--. 1 juan juan 124 Jun 22 2010 .bashrc
drwxr-xr-x. 2 juan juan 4096 Jul 14 2010 .gnome2
drwxr-xr-x. 4 juan juan 4096 Nov 23 15:09 .mozillajuan exists on the system. To activate it, the administrator must next assign a password to the account using the passwd command and, optionally, set password aging guidelines.
root:
groupadd[options]group_name
options are command line options as described in Таблица 3.3, «groupadd command line options».
| Option | Description |
|---|---|
-f, --force
|
When used with -g gid and gid already exists, groupadd will choose another unique gid for the group.
|
-g gid
| Group ID for the group, which must be unique and greater than 999. |
-K, --key key=value
|
Override /etc/login.defs defaults.
|
-o, --non-unique
| Allow to create groups with duplicate. |
-p, --password password
| Use this encrypted password for the new group. |
-r
| Create a system group with a GID less than 1000. |
chage command.
chage command. For more information, see Раздел 3.1.2, «Shadow Passwords».
root:
chage[options]username
options are command line options as described in Таблица 3.4, «chage command line options». When the chage command is followed directly by a username (that is, when no command line options are specified), it displays the current password aging values and allows you to change them interactively.
| Option | Description |
|---|---|
-d days
| Specifies the number of days since January 1, 1970 the password was changed. |
-E date
| Specifies the date on which the account is locked, in the format YYYY-MM-DD. Instead of the date, the number of days since January 1, 1970 can also be used. |
-I days
|
Specifies the number of inactive days after the password expiration before locking the account. If the value is 0, the account is not locked after the password expires.
|
-l
| Lists current account aging settings. |
-m days
|
Specify the minimum number of days after which the user must change passwords. If the value is 0, the password does not expire.
|
-M days
|
Specify the maximum number of days for which the password is valid. When the number of days specified by this option plus the number of days specified with the -d option is less than the current day, the user must change passwords before using the account.
|
-W days
| Specifies the number of days before the password expiration date to warn the user. |
root:
passwdusername
passwd-dusername
root:
chage-d0username
root, an unattended login session may pose a significant security risk. To reduce this risk, you can configure the system to automatically log out idle users after a fixed period of time:
root:
yuminstallscreen
root, add the following line at the beginning of the /etc/profile file to make sure the processing of this file cannot be interrupted:
trap "" 1 2 3 15
/etc/profile file to start a screen session each time a user logs in to a virtual console or remotely:
SCREENEXEC="screen" if [ -w $(tty) ]; then trap "exec $SCREENEXEC" 1 2 3 15 echo -n 'Starting session in 10 seconds' sleep 10 exec $SCREENEXEC fi
sleep command.
/etc/screenrc configuration file to close the screen session after a given period of inactivity:
idle 120 quit autodetach off
idle directive.
idle 120 lockscreen autodetach off
/opt/myproject/ directory. Some people are trusted to modify the contents of this directory, but not everyone.
root, create the /opt/myproject/ directory by typing the following at a shell prompt:
mkdir /opt/myprojectmyproject group to the system:
groupadd myproject/opt/myproject/ directory with the myproject group:
chown root:myproject /opt/myprojectchmod 2775 /opt/myprojectmyproject group can create and edit files in the /opt/myproject/ directory without the administrator having to change file permissions every time users write new files. To verify that the permissions have been set correctly, run the following command:
~]# ls -l /opt
total 4
drwxrwsr-x. 3 root myproject 4096 Mar 3 18:31 myproject/etc/group file.
/etc/group file.
/etc/passwd and /etc/shadow files.
Содержание
yum для установки, обновления или удаления пакетов в системе, вам потребуются права суперпользователя. Все примеры этого раздела предполагают, что вы уже получили необходимые привилегии с помощью команд su или sudo.
yumcheck-update
~]# yum check-update
Loaded plugins: langpacks, presto, refresh-packagekit
PackageKit.x86_64 0.6.14-2.fc15 fedora
PackageKit-command-not-found.x86_64 0.6.14-2.fc15 fedora
PackageKit-device-rebind.x86_64 0.6.14-2.fc15 fedora
PackageKit-glib.x86_64 0.6.14-2.fc15 fedora
PackageKit-gstreamer-plugin.x86_64 0.6.14-2.fc15 fedora
PackageKit-gtk-module.x86_64 0.6.14-2.fc15 fedora
PackageKit-gtk3-module.x86_64 0.6.14-2.fc15 fedora
PackageKit-yum.x86_64 0.6.14-2.fc15 fedora
PackageKit-yum-plugin.x86_64 0.6.14-2.fc15 fedora
gdb.x86_64 7.2.90.20110429-36.fc15 fedora
kernel.x86_64 2.6.38.6-26.fc15 fedora
rpm.x86_64 4.9.0-6.fc15 fedora
rpm-libs.x86_64 4.9.0-6.fc15 fedora
rpm-python.x86_64 4.9.0-6.fc15 fedora
yum.noarch 3.2.29-5.fc15 fedoraPackageKit — название пакета
x86_64 — архитектура процессора, для которой этот пакет был собран
0.6.14 — the version of the updated package to be installed
fedora — репозиторий, в котором находится обновляемый пакет
yum and rpm packages), as well as their dependencies (such as the kernel-firmware, rpm-libs, and rpm-python packages), all using yum.
root:
yumupdatepackage_name
~]# yum update udev
Loaded plugins: langpacks, presto, refresh-packagekit
Updating Red Hat repositories.
INFO:rhsm-app.repolib:repos updated: 0
Setting up Update Process
Resolving Dependencies
--> Running transaction check
---> Package gdb.x86_64 0:7.2.90.20110411-34.fc15 will be updated
---> Package gdb.x86_64 0:7.2.90.20110429-36.fc15 will be an update
--> Finished Dependency Resolution
Dependencies Resolved
================================================================================
Package Arch Version Repository Size
================================================================================
Updating:
gdb x86_64 7.2.90.20110429-36.fc15 fedora 1.9 M
Transaction Summary
================================================================================
Upgrade 1 Package(s)
Total download size: 1.9 M
Is this ok [y/N]:Loaded plugins: — yum always informs you which Yum plug-ins are installed and enabled. Here, yum is using the langpacks, presto, and refresh-packagekit plug-ins. Refer to Раздел 4.4, «Yum Plug-ins» for general information on Yum plug-ins, or to Раздел 4.4.3, «Plug-in Descriptions» for descriptions of specific plug-ins.
gdb.x86_64 — you can download and install new gdb package.
yum выводит информацию об обновлении и запрашивает подтверждение: хотите ли вы выполнить данное обновление; по умолчанию yum работает в интерактивном режиме. Если вы уже знаете, какие именно транзакции yum планирует выполнить, вы можете воспользоваться опцией -y, которая автоматически отвечает yes(да) на любой вопрос, который yum может задать (в этом случае yum работает полностью неинтерактивно). Однако, следует всегда проверять, какие изменения yum собирается выполнить в системе. Так вы легко диагностируете любые возможные проблемы.
yum history command as described in Раздел 4.2.6, «Working with Transaction History».
yum always installs a new kernel in the same sense that RPM installs a new kernel when you use the command rpm -i kernel. Therefore, you do not need to worry about the distinction between installing and upgrading a kernel package when you use yum: it will do the right thing, regardless of whether you are using the yum update or yum install command.
rpm -i kernel (которая устанавливает новое ядро) вместо команды rpm -u kernel (которая заменяет текущее ядро). Более подробно об установке/обновлении ядер с помощью RPM можно прочитать по ссылке Раздел B.2.2, «Installing and Upgrading».
yum update (without any arguments):
yum updateyum command with a set of highly-useful security-centric commands, subcommands and options. Refer to Раздел 4.4.3, «Plug-in Descriptions» for specific information.
yumsearchterm…
~]# yum search meld kompare
Loaded plugins: langpacks, presto, refresh-packagekit
============================== N/S Matched: meld ===============================
meld.noarch : Visual diff and merge tool
python-meld3.x86_64 : HTML/XML templating system for Python
============================= N/S Matched: kompare =============================
komparator.x86_64 : Kompare and merge two folders
Name and summary matches only, use "search all" for everything.yum search command is useful for searching for packages you do not know the name of, but for which you know a related term.
yum list and related commands provide information about packages, package groups, and repositories.
* (which expands to match any character multiple times) and ? (which expands to match any one character).
yum command, otherwise the Bash shell will interpret these expressions as pathname expansions, and potentially pass all files in the current directory that match the globs to yum. To make sure the glob expressions are passed to yum as intended, either:
yum list glob_expression… ~]# yum list abrt-addon\* abrt-plugin\*
Loaded plugins: langpacks, presto, refresh-packagekit
Installed Packages
abrt-addon-ccpp.x86_64 2.0.2-5.fc15 @fedora
abrt-addon-kerneloops.x86_64 2.0.2-5.fc15 @fedora
abrt-addon-python.x86_64 2.0.2-5.fc15 @fedora
abrt-plugin-bugzilla.x86_64 2.0.2-5.fc15 @fedora
abrt-plugin-logger.x86_64 2.0.2-5.fc15 @fedora
Available Packages
abrt-plugin-mailx.x86_64 2.0.2-5.fc15 updates
abrt-plugin-reportuploader.x86_64 2.0.2-5.fc15 updates
abrt-plugin-rhtsupport.x86_64 2.0.2-5.fc15 updatesyum list all ~]# yum list all
Loaded plugins: langpacks, presto, refresh-packagekit
Installed Packages
ConsoleKit.x86_64 0.4.4-1.fc15 @fedora
ConsoleKit-libs.x86_64 0.4.4-1.fc15 @fedora
ConsoleKit-x11.x86_64 0.4.4-1.fc15 @fedora
GConf2.x86_64 2.32.3-1.fc15 @fedora
GConf2-gtk.x86_64 2.32.3-1.fc15 @fedora
ModemManager.x86_64 0.4-7.git20110201.fc15 @fedora
NetworkManager.x86_64 1:0.8.998-4.git20110427.fc15 @fedora
NetworkManager-glib.x86_64 1:0.8.998-4.git20110427.fc15 @fedora
NetworkManager-gnome.x86_64 1:0.8.998-4.git20110427.fc15 @fedora
NetworkManager-openconnect.x86_64 0.8.1-9.git20110419.fc15 @fedora
[output truncated]yum list installed ~]# yum list installed "krb?-*"
Loaded plugins: langpacks, presto, refresh-packagekit
Installed Packages
krb5-libs.x86_64 1.9-7.fc15 @fedorayum list available ~]# yum list available gstreamer\*plugin\*
Loaded plugins: langpacks, presto, refresh-packagekit
Available Packages
gstreamer-plugin-crystalhd.x86_64 3.5.1-1.fc14 fedora
gstreamer-plugins-bad-free.x86_64 0.10.22-1.fc15 updates
gstreamer-plugins-bad-free-devel.x86_64 0.10.22-1.fc15 updates
gstreamer-plugins-bad-free-devel-docs.x86_64 0.10.22-1.fc15 updates
gstreamer-plugins-bad-free-extras.x86_64 0.10.22-1.fc15 updates
gstreamer-plugins-base.x86_64 0.10.33-1.fc15 updates
gstreamer-plugins-base-devel.x86_64 0.10.33-1.fc15 updates
gstreamer-plugins-base-devel-docs.noarch 0.10.33-1.fc15 updates
gstreamer-plugins-base-tools.x86_64 0.10.33-1.fc15 updates
gstreamer-plugins-espeak.x86_64 0.3.3-3.fc15 fedora
gstreamer-plugins-fc.x86_64 0.2-2.fc15 fedora
gstreamer-plugins-good.x86_64 0.10.29-1.fc15 updates
gstreamer-plugins-good-devel-docs.noarch 0.10.29-1.fc15 updatesyum grouplist ~]# yum grouplist
Loaded plugins: langpacks, presto, refresh-packagekit
Setting up Group Process
Installed Groups:
Administration Tools
Design Suite
Dial-up Networking Support
Fonts
GNOME Desktop Environment
[output truncated]yum repolist ~]# yum repolist
Loaded plugins: langpacks, presto, refresh-packagekit
repo id repo name status
fedora Fedora 15 - i386 19,365
updates Fedora 15 - i386 - Updates 3,848
repolist: 23,213yuminfopackage_name…
~]# yum info abrt
Loaded plugins: langpacks, presto, refresh-packagekit
Installed Packages
Name : abrt
Arch : x86_64
Version : 2.0.1
Release : 2.fc15
Size : 806 k
Repo : installed
From repo : fedora
Summary : Automatic bug detection and reporting tool
URL : https://fedorahosted.org/abrt/
License : GPLv2+
Description : abrt is a tool to help users to detect defects in applications and
: to create a bug report with all informations needed by maintainer
: to fix it. It uses plugin system to extend its functionality.yum info package_name command is similar to the rpm -q --info package_name command, but provides as additional information the ID of the Yum repository the RPM package is found in (look for the From repo: line in the output).
yumdbinfopackage_name
user indicates it was installed by the user, and dep means it was brought in as a dependency). For example, to display additional information about the yum package, type:
~]# yumdb info yum
Loaded plugins: langpacks, presto, refresh-packagekit
yum-3.2.29-4.fc15.noarch
checksum_data = 249f21fb43c41381c8c9b0cd98d2ea5fa0aa165e81ed2009cfda74c05af67246
checksum_type = sha256
from_repo = fedora
from_repo_revision = 1304429533
from_repo_timestamp = 1304442346
installed_by = 0
reason = user
releasever = $releaseveryumdb command, refer to the yumdb(8) manual page.
yuminstallpackage_name
yuminstallpackage_namepackage_name…
.arch to the package name. For example, to install the sqlite2 package for i586, type:
~]# yum install sqlite2.i586~]# yum install audacious-plugins-\*yum install также может работать с именами файлов. Если вы знаете имя бинарного файла, который бы хотели установить, но не знаете название соответствующего пакета, задайте команде yum install полный путь до файла:
~]# yum install /usr/sbin/namedyum then searches through its package lists, finds the package which provides /usr/sbin/named, if any, and prompts you as to whether you want to install it.
named binary, but you do not know in which bin or sbin directory is the file installed, use the yum provides command with a glob expression:
~]# yum provides "*bin/named"
Loaded plugins: langpacks, presto, refresh-packagekit
32:bind-9.8.0-3.P1.fc15.i686 : The Berkeley Internet Name Domain (BIND) DNS
: (Domain Name System) server
Repo : fedora
Matched from:
Filename : /usr/sbin/namedyum provides "*/file_name" is a common and useful trick to find the packages that contain file_name.
yum grouplist -v command lists the names of all package groups, and, next to each of them, their groupid in parentheses. The groupid is always the term in the last pair of parentheses, such as kde-desktop in the following example:
~]# yum -v grouplist kde\*
Not loading "blacklist" plugin, as it is disabled
Loading "langpacks" plugin
Loading "presto" plugin
Loading "refresh-packagekit" plugin
Not loading "whiteout" plugin, as it is disabled
Adding en_US to language list
Config time: 0.900
Yum Version: 3.2.29
Setting up Group Process
rpmdb time: 0.002
group time: 0.995
Available Groups:
KDE Software Compilation (kde-desktop)
KDE Software Development (kde-software-development)
Donegroupinstall:
yumgroupinstallgroup_name
yumgroupinstallgroupid
install command if you prepend it with an @-symbol (which tells yum that you want to perform a groupinstall):
yuminstall@group
KDE Desktop group:
~]#yum groupinstall "KDE Desktop"~]#yum groupinstall kde-desktop~]#yum install @kde-desktop
root:
yumremovepackage_name…
~]# yum remove totem rhythmbox sound-juicerinstall, remove can take these arguments:
install syntax:
yumgroupremovegroup
yumremove@group
KDE Desktop group:
~]#yum groupremove "KDE Desktop"~]#yum groupremove kde-desktop~]#yum remove @kde-desktop
yum to remove only those packages which are not required by any other packages or groups by adding the groupremove_leaf_only=1 directive to the [main] section of the /etc/yum.conf configuration file. For more information on this directive, refer to Раздел 4.3.1, «Setting [main] Options».
yum history command allows users to review information about a timeline of Yum transactions, the dates and times on when they occurred, the number of packages affected, whether transactions succeeded or were aborted, and if the RPM database was changed between transactions. Additionally, this command can be used to undo or redo certain transactions.
root, either run yum history with no additional arguments, or type the following at a shell prompt:
yumhistorylist
all keyword:
yumhistorylistall
yumhistoryliststart_id..end_id
yumhistorylistglob_expression…
~]# yum history list 1..5
Loaded plugins: langpacks, presto, refresh-packagekit
ID | Login user | Date and time | Action(s) | Altered
-------------------------------------------------------------------------------
5 | Jaromir ... <jhradilek> | 2011-07-29 15:33 | Install | 1
4 | Jaromir ... <jhradilek> | 2011-07-21 15:10 | Install | 1
3 | Jaromir ... <jhradilek> | 2011-07-16 15:27 | I, U | 73
2 | System <unset> | 2011-07-16 15:19 | Update | 1
1 | System <unset> | 2011-07-16 14:38 | Install | 1106
history listyum history list command produce tabular output with each row consisting of the following columns:
ID — an integer value that identifies a particular transaction.
Login user — the name of the user whose login session was used to initiate a transaction. This information is typically presented in the Full Name <username>System <unset> is used instead.
Date and time — the date and time when a transaction was issued.
Action(s) — a list of actions that were performed during a transaction as described in Таблица 4.1, «Possible values of the Action(s) field».
Altered — the number of packages that were affected by a transaction, possibly followed by additional information as described in Таблица 4.2, «Possible values of the Altered field».
| Action | Abbreviation | Description |
|---|---|---|
Downgrade
|
D
| At least one package has been downgraded to an older version. |
Erase
|
E
| At least one package has been removed. |
Install
|
I
| At least one new package has been installed. |
Obsoleting
|
O
| At least one package has been marked as obsolete. |
Reinstall
|
R
| At least one package has been reinstalled. |
Update
|
U
| At least one package has been updated to a newer version. |
| Symbol | Description |
|---|---|
<
|
Before the transaction finished, the rpmdb database was changed outside Yum.
|
>
|
After the transaction finished, the rpmdb database was changed outside Yum.
|
*
| The transaction failed to finish. |
#
|
The transaction finished successfully, but yum returned a non-zero exit code.
|
E
| The transaction finished successfully, but an error or a warning was displayed. |
P
|
The transaction finished successfully, but problems already existed in the rpmdb database.
|
s
|
The transaction finished successfully, but the --skip-broken command line option was used and certain packages were skipped.
|
root:
yumhistorysummary
yumhistorysummarystart_id..end_id
yum history list command, you can also display a summary of transactions regarding a certain package or packages by supplying a package name or a glob expression:
yumhistorysummaryglob_expression…
~]# yum history summary 1..5
Loaded plugins: langpacks, presto, refresh-packagekit
Login user | Time | Action(s) | Altered
-------------------------------------------------------------------------------
Jaromir ... <jhradilek> | Last day | Install | 1
Jaromir ... <jhradilek> | Last week | Install | 1
Jaromir ... <jhradilek> | Last 2 weeks | I, U | 73
System <unset> | Last 2 weeks | I, U | 1107
history summaryyum history summary command produce simplified tabular output similar to the output of yum history list.
yum history list and yum history summary are oriented towards transactions, and although they allow you to display only transactions related to a given package or packages, they lack important details, such as package versions. To list transactions from the perspective of a package, run the following command as root:
yumhistorypackage-listglob_expression…
~]# yum history package-list subscription-manager\*
Loaded plugins: langpacks, presto, refresh-packagekit
ID | Action(s) | Package
-------------------------------------------------------------------------------
3 | Updated | subscription-manager-0.95.11-1.el6.x86_64
3 | Update | 0.95.17-1.el6_1.x86_64
3 | Updated | subscription-manager-firstboot-0.95.11-1.el6.x86_64
3 | Update | 0.95.17-1.el6_1.x86_64
3 | Updated | subscription-manager-gnome-0.95.11-1.el6.x86_64
3 | Update | 0.95.17-1.el6_1.x86_64
1 | Install | subscription-manager-0.95.11-1.el6.x86_64
1 | Install | subscription-manager-firstboot-0.95.11-1.el6.x86_64
1 | Install | subscription-manager-gnome-0.95.11-1.el6.x86_64
history package-listroot, use the yum history summary command in the following form:
yumhistorysummaryid
root:
yumhistoryinfoid…
id argument is optional and when you omit it, yum automatically uses the last transaction. Note that when specifying more than one transaction, you can also use a range:
yumhistoryinfostart_id..end_id
~]# yum history info 4..5
Loaded plugins: langpacks, presto, refresh-packagekit
Transaction ID : 4..5
Begin time : Thu Jul 21 15:10:46 2011
Begin rpmdb : 1107:0c67c32219c199f92ed8da7572b4c6df64eacd3a
End time : 15:33:15 2011 (22 minutes)
End rpmdb : 1109:1171025bd9b6b5f8db30d063598f590f1c1f3242
User : Jaromir Hradilek <jhradilek>
Return-Code : Success
Command Line : install screen
Command Line : install yum-plugin-fs-snapshot
Transaction performed with:
Installed rpm-4.8.0-16.el6.x86_64
Installed yum-3.2.29-17.el6.noarch
Installed yum-metadata-parser-1.1.2-16.el6.x86_64
Packages Altered:
Install screen-4.0.3-16.el6.x86_64
Install yum-plugin-fs-snapshot-1.1.30-6.el6.noarch
history inforoot:
yumhistoryaddon-infoid
yum history info, when no id is provided, yum automatically uses the latest transaction. Another way to refer to the latest transaction is to use the last keyword:
yumhistoryaddon-infolast
yum history addon-info command would provide the following output:
~]# yum history addon-info 4
Loaded plugins: langpacks, presto, refresh-packagekit
Transaction ID: 4
Available additional history information:
config-main
config-repos
saved_tx
history addon-infoconfig-main — global Yum options that were in use during the transaction. Refer to Раздел 4.3.1, «Setting [main] Options» for information on how to change global options.
config-repos — options for individual Yum repositories. Refer to Раздел 4.3.2, «Setting [repository] Options» for information on how to change options for individual repositories.
saved_tx — the data that can be used by the yum load-transaction command in order to repeat the transaction on another machine (see below).
root:
yumhistoryaddon-infoidinformation
yum history command provides means to revert or repeat a selected transaction. To revert a transaction, type the following at a shell prompt as root:
yumhistoryundoid
root, run the following command:
yumhistoryredoid
last keyword to undo or repeat the latest transaction.
yum history undo and yum history redo commands merely revert or repeat the steps that were performed during a transaction: if the transaction installed a new package, the yum history undo command will uninstall it, and vice versa. If possible, this command will also attempt to downgrade all updated packages to their previous version, but these older packages may no longer be available. If you need to be able to restore the system to the state before an update, consider using the fs-snapshot plug-in described in Раздел 4.4.3, «Plug-in Descriptions».
root:
yum-qhistoryaddon-infoidsaved_tx>file_name
root:
yumload-transactionfile_name
rpmdb version stored in the file must by identical to the version on the target system. You can verify the rpmdb version by using the yum version nogroups command.
root:
yumhistorynew
/var/lib/yum/history/ directory. The old transaction history will be kept, but will not be accessible as long as a newer database file is present in the directory.
yum and related utilities is located at /etc/yum.conf. This file contains one mandatory [main] section, which allows you to set Yum options that have global effect, and may also contain one or more [repository] sections, which allow you to set repository-specific options. However, best practice is to define individual repositories in new or existing .repo files in the /etc/yum.repos.d/directory. The values you define in the [main] section of the /etc/yum.conf file may override values set in individual [repository] sections.
[main] section of the /etc/yum.conf configuration file;
[repository] sections in /etc/yum.conf and .repo files in the /etc/yum.repos.d/ directory;
/etc/yum.conf and files in the /etc/yum.repos.d/ directory so that dynamic version and architecture values are handled correctly;
/etc/yum.conf configuration file contains exactly one [main] section, and while some of the key-value pairs in this section affect how yum operates, others affect how Yum treats repositories. You can add many additional options under the [main] section heading in /etc/yum.conf.
/etc/yum.conf configuration file can look like this:
[main]
cachedir=/var/cache/yum/$basearch/$releasever
keepcache=0
debuglevel=2
logfile=/var/log/yum.log
exactarch=1
obsoletes=1
gpgcheck=1
plugins=1
installonly_limit=3
[comments abridged]
# PUT YOUR REPOS HERE OR IN separate files named file.repo
# in /etc/yum.repos.d[main] section:
assumeyes=valuevalue is one of:
0 — yum should prompt for confirmation of critical actions it performs. This is the default.
1 — Do not prompt for confirmation of critical yum actions. If assumeyes=1 is set, yum behaves in the same way that the command line option -y does.
cachedir=directorydirectory is an absolute path to the directory where Yum should store its cache and database files. By default, Yum's cache directory is /var/cache/yum/$basearch/$releasever.
$basearch and $releasever Yum variables.
debuglevel=valuevalue is an integer between 1 and 10. Setting a higher debuglevel value causes yum to display more detailed debugging output. debuglevel=0 disables debugging output, while debuglevel=2 is the default.
exactarch=valuevalue is one of:
0 — Do not take into account the exact architecture when updating packages.
1 — Consider the exact architecture when updating packages. With this setting, yum will not install an i686 package to update an i386 package already installed on the system. This is the default.
exclude=package_name [more_package_names]* and ?) are allowed.
gpgcheck=valuevalue is one of:
0 — Disable GPG signature-checking on packages in all repositories, including local package installation.
1 — Enable GPG signature-checking on all packages in all repositories, including local package installation. gpgcheck=1 is the default, and thus all packages' signatures are checked.
[main] section of the /etc/yum.conf file, it sets the GPG-checking rule for all repositories. However, you can also set gpgcheck=value for individual repositories instead; that is, you can enable GPG-checking on one repository while disabling it on another. Setting gpgcheck=value for an individual repository in its corresponding .repo file overrides the default if it is present in /etc/yum.conf.
groupremove_leaf_only=valuevalue is one of:
0 — yum should not check the dependencies of each package when removing a package group. With this setting, yum removes all packages in a package group, regardless of whether those packages are required by other packages or groups. groupremove_leaf_only=0 is the default.
1 — yum should check the dependencies of each package when removing a package group, and remove only those packages which are not not required by any other package or group.
installonlypkgs=space separated list of packagesyum can install, but will never update. Refer to the yum.conf(5) manual page for the list of packages which are install-only by default.
installonlypkgs directive to /etc/yum.conf, you should ensure that you list all of the packages that should be install-only, including any of those listed under the installonlypkgs section of yum.conf(5). In particular, kernel packages should always be listed in installonlypkgs (as they are by default), and installonly_limit should always be set to a value greater than 2 so that a backup kernel is always available in case the default one fails to boot.
installonly_limit=valuevalue is an integer representing the maximum number of versions that can be installed simultaneously for any single package listed in the installonlypkgs directive.
installonlypkgs directive include several different kernel packages, so be aware that changing the value of installonly_limit will also affect the maximum number of installed versions of any single kernel package. The default value listed in /etc/yum.conf is installonly_limit=3, and it is not recommended to decrease this value, particularly below 2.
keepcache=valuevalue is one of:
0 — Do not retain the cache of headers and packages after a successful installation. This is the default.
1 — Retain the cache after a successful installation.
logfile=file_namefile_name is an absolute path to the file in which yum should write its logging output. By default, yum logs to /var/log/yum.log.
multilib_policy=valuevalue is one of:
best — install the best-choice architecture for this system. For example, setting multilib_policy=best on an AMD64 system causes yum to install 64-bit versions of all packages.
all — always install every possible architecture for every package. For example, with multilib_policy set to all on an AMD64 system, yum would install both the i586 and AMD64 versions of a package, if both were available.
obsoletes=valuevalue is one of:
0 — Disable yum's obsoletes processing logic when performing updates.
1 — Enable yum's obsoletes processing logic when performing updates. When one package declares in its spec file that it obsoletes another package, the latter package will be replaced by the former package when the former package is installed. Obsoletes are declared, for example, when a package is renamed. obsoletes=1 the default.
plugins=valuevalue is one of:
0 — Disable all Yum plug-ins globally.
Yum services. Disabling plug-ins globally is provided as a convenience option, and is generally only recommended when diagnosing a potential problem with Yum.
1 — Enable all Yum plug-ins globally. With plugins=1, you can still disable a specific Yum plug-in by setting enabled=0 in that plug-in's configuration file.
reposdir=directorydirectory is an absolute path to the directory where .repo files are located. All .repo files contain repository information (similar to the [repository] sections of /etc/yum.conf). yum collects all repository information from .repo files and the [repository] section of the /etc/yum.conf file to create a master list of repositories to use for transactions. If reposdir is not set, yum uses the default directory /etc/yum.repos.d/.
retries=valuevalue is an integer 0 or greater. This value sets the number of times yum should attempt to retrieve a file before returning an error. Setting this to 0 makes yum retry forever. The default value is 10.
[main] options, refer to the [main] OPTIONS section of the yum.conf(5) manual page.
[repository] sections, where repository is a unique repository ID such as my_personal_repo (spaces are not permitted), allow you to define individual Yum repositories.
[repository] section takes:
[repository] name=repository_namebaseurl=repository_url
[repository] section must contain the following directives:
name=repository_namerepository_name is a human-readable string describing the repository.
baseurl=repository_urlrepository_url is a URL to the directory where the repodata directory of a repository is located:
http://path/to/repo
ftp://path/to/repo
file:///path/to/local/repo
username:password@linkbaseurl link could be specified as http://user:password@www.example.com/repo/.
baseurl=http://path/to/repo/releases/$releasever/server/$basearch/os/
$releasever, $arch, and $basearch variables in URLs. For more information about Yum variables, refer to Раздел 4.3.3, «Using Yum Variables».
[repository] directive is the following:
enabled=valuevalue is one of:
0 — Do not include this repository as a package source when performing updates and installs. This is an easy way of quickly turning repositories on and off, which is useful when you desire a single package from a repository that you do not want to enable for updates or installs.
1 — Include this repository as a package source.
--enablerepo=repo_name or --disablerepo=repo_name option to yum, or through the Add/Remove Software window of the PackageKit utility.
[repository] options exist. For a complete list, refer to the [repository] OPTIONS section of the yum.conf(5) manual page.
yum commands and in all Yum configuration files (that is, /etc/yum.conf and all .repo files in the /etc/yum.repos.d/ directory):
$releasever$releasever from the distroverpkg=value line in the /etc/yum.conf configuration file. If there is no such line in /etc/yum.conf, then yum infers the correct value by deriving the version number from the redhat-release package.
$archos.uname() function. Valid values for $arch include: i586, i686 and x86_64.
$basearch$basearch to reference the base architecture of the system. For example, i686 and i586 machines both have a base architecture of i386, and AMD64 and Intel64 machines have a base architecture of x86_64.
$YUM0-9/etc/yum.conf for example) and a shell environment variable with the same name does not exist, then the configuration file variable is not replaced.
$» sign) in the /etc/yum/vars/ directory, and add the desired value on its first line.
$osname, create a new file with «Fedora» on the first line and save it as /etc/yum/vars/osname:
~]# echo "Fedora" > /etc/yum/vars/osname.repo files:
name=$osname $releasever
[main] section of the /etc/yum.conf file), run the yum-config-manager with no command line options:
yum-config-manageryum-config-managersection…
yum-config-managerglob_expression…
~]$ yum-config-manager main \*
Loaded plugins: langpacks, presto, refresh-packagekit
================================== main ===================================
[main]
alwaysprompt = True
assumeyes = False
bandwith = 0
bugtracker_url = https://bugzilla.redhat.com/enter_bug.cgi?product=Red%20Hat%20Enterprise%20Linux%206&component=yum
cache = 0
[output truncated]yum-config-manager command.
[repository] section to the /etc/yum.conf file, or to a .repo file in the /etc/yum.repos.d/ directory. All files with the .repo file extension in this directory are read by yum, and best practice is to define your repositories here instead of in /etc/yum.conf.
.repo file. To add such a repository to your system and enable it, run the following command as root:
yum-config-manager--add-reporepository_url
repository_url is a link to the .repo file. For example, to add a repository located at http://www.example.com/example.repo, type the following at a shell prompt:
~]# yum-config-manager --add-repo http://www.example.com/example.repo
Loaded plugins: langpacks, presto, refresh-packagekit
adding repo from: http://www.example.com/example.repo
grabbing file http://www.example.com/example.repo to /etc/yum.repos.d/example.repo
example.repo | 413 B 00:00
repo saved to /etc/yum.repos.d/example.reporoot:
yum-config-manager--enablerepository…
repository is the unique repository ID (use yum repolist all to list available repository IDs). Alternatively, you can use a glob expression to enable all matching repositories:
yum-config-manager--enableglob_expression…
[example], [example-debuginfo], and [example-source]sections, type:
~]# yum-config-manager --enable example\*
Loaded plugins: langpacks, presto, refresh-packagekit
============================== repo: example ==============================
[example]
bandwidth = 0
base_persistdir = /var/lib/yum/repos/x86_64/6Server
baseurl = http://www.example.com/repo/6Server/x86_64/
cache = 0
cachedir = /var/cache/yum/x86_64/6Server/example
[output truncated]yum-config-manager --enable command displays the current repository configuration.
root:
yum-config-manager--disablerepository…
repository is the unique repository ID (use yum repolist all to list available repository IDs). Similarly to yum-config-manager --enable, you can use a glob expression to disable all matching repositories at the same time:
yum-config-manager--disableglob_expression…
yum-config-manager --disable command displays the current configuration.
~]# yum install createrepo/mnt/local_repo/.
createrepo --database command on that directory:
~]# createrepo --database /mnt/local_repoyum operations.
yum command. For example:
~]# yum info yum
Loaded plugins: langpacks, presto, refresh-packagekit
[output truncated]Loaded plugins are the names you can provide to the --disableplugins=plugin_name option.
plugins= is present in the [main] section of /etc/yum.conf, and that its value is set to 1:
plugins=1
plugins=0.
Yum services. Disabling plug-ins globally is provided as a convenience option, and is generally only recommended when diagnosing a potential problem with Yum.
/etc/yum/pluginconf.d/ directory. You can set plug-in specific options in these files. For example, here is the refresh-packagekit plug-in's refresh-packagekit.conf configuration file:
[main] enabled=1
[main] section (similar to Yum's /etc/yum.conf file) in which there is (or you can place if it is missing) an enabled= option that controls whether the plug-in is enabled when you run yum commands.
enabled=0 in /etc/yum.conf, then all plug-ins are disabled regardless of whether they are enabled in their individual configuration files.
yum command, use the --noplugins option.
yum command, add the --disableplugin=plugin_name option to the command. For example, to disable the presto plug-in while updating a system, type:
~]# yum update --disableplugin=presto--disableplugin= option are the same names listed after the Loaded plugins line in the output of any yum command. You can disable multiple plug-ins by separating their names with commas. In addition, you can match multiple plug-in names or shorten long ones by using glob expressions:
~]# yum update --disableplugin=presto,refresh-pack*yum-plugin-plugin_name package-naming convention, but not always: the package which provides the presto plug-in is named yum-presto, for example. You can install a Yum plug-in in the same way you install other packages. For instance, to install the security plug-in, type the following at a shell prompt:
~]# yum install yum-plugin-security/) must be on an LVM (Logical Volume Manager) or Btrfs volume. To use the fs-snapshot plug-in on an LVM volume, take the following steps:
vgdisplay command in the following form as root:
vgdisplayvolume_group
Free PE / Size line.
root, run the pvcreate command in the following form to initialize a physical volume for use with the Logical Volume Manager:
pvcreatedevice
vgextend command in the following form as root to add the physical volume to the volume group:
vgextendvolume_groupphysical_volume
/etc/yum/pluginconf.d/fs-snapshot.conf, and make the following changes to the [lvm] section:
enabled option to 1:
enabled = 1
#) from the beginning of the lvcreate_size_args line, and adjust the number of logical extents to be allocated for a snapshot. For example, to allocate 80 % of the size of the original logical volume, use:
lvcreate_size_args = -l 80%ORIGIN
fs-snapshot.conf directives» for a complete list of available configuration options.
yum command, and make sure fs-snapshot is included in the list of loaded plug-ins (the Loaded plugins line) before you confirm the changes and proceed with the transaction. The fs-snapshot plug-in displays a line in the following form for each affected logical volume:
fs-snapshot: snapshottingfile_system(/dev/volume_group/logical_volume):logical_volume_yum_timestamp
lvremove command as root:
lvremove/dev/volume_group/logical_volume_yum_timestamp
root, run the command in the following form to merge a snapshot into its original logical volume:
lvconvert--merge/dev/volume_group/logical_volume_yum_timestamp
lvconvert command will inform you that a restart is required in order for the changes to take effect.
root:
rebootyum command, and make sure fs-snapshot is included in the list of loaded plug-ins (the Loaded plugins line) before you confirm the changes and proceed with the transaction. The fs-snapshot plug-in displays a line in the following form for each affected file system:
fs-snapshot: snapshottingfile_system:file_system/yum_timestamp
root:
btrfssubvolumedeletefile_system/yum_timestamp
root:
btrfssubvolumelistfile_system
root, configure the system to mount this snapshot by default:
btrfssubvolumeset-defaultidfile_system
root:
rebootfs-snapshot.conf directives| Section | Directive | Description |
|---|---|---|
[main]
|
enabled=value
|
Allows you to enable or disable the plug-in. The value must be either 1 (enabled), or 0 (disabled). When installed, the plug-in is enabled by default.
|
exclude=list
|
Allows you to exclude certain file systems. The value must be a space-separated list of mount points you do not want to snapshot (for example, /srv /mnt/backup). This option is not included in the configuration file by default.
| |
[lvm]
|
enabled=value
|
Allows you to enable or disable the use of the plug-in on LVM volumes. The value must be either 1 (enabled), or 0 (disabled). This option is disabled by default.
|
lvcreate_size_args=value
|
Allows you to specify the size of a logical volume snapshot. The value must be the -l or -L command line option for the lvcreate utility followed by a valid argument (for example, -l 80%ORIGIN).
|
yum is run. The refresh-packagekit plug-in is installed by default.
RHN Classic. This allows systems registered with RHN Classic to update and install packages from this system.
yum with a set of highly-useful security-related commands, subcommands and options.
~]# yum check-update --security
Loaded plugins: langpacks, presto, refresh-packagekit, security
Limiting package lists to security relevant ones
updates-testing/updateinfo | 329 kB 00:00
9 package(s) needed for security, out of 270 available
ConsoleKit.x86_64 0.4.5-1.fc15 updates
ConsoleKit-libs.x86_64 0.4.5-1.fc15 updates
ConsoleKit-x11.x86_64 0.4.5-1.fc15 updates
NetworkManager.x86_64 1:0.8.999-2.git20110509.fc15 updates
NetworkManager-glib.x86_64 1:0.8.999-2.git20110509.fc15 updates
[output truncated]yum update --security or yum update-minimal --security to update those packages which are affected by security advisories. Both of these commands update all packages on the system for which a security advisory has been issued. yum update-minimal --security updates them to the latest packages which were released as part of a security advisory, while yum update --security will update all packages affected by a security advisory to the latest version of that package available.
yum update-minimal --security will update you to kernel-2.6.38.6-22, and yum update --security will update you to kernel-2.6.38.6-26. Conservative system administrators may want to use update-minimal to reduce the risk incurred by updating packages as much as possible.
yum.
Yum Guides section of the Yum wiki contains more documentation.
gpk-update-viewer command at the shell prompt. In the Software Updates window, all available updates are listed along with the names of the packages being updated (minus the .rpm suffix, but including the CPU architecture), a short summary of the package, and, usually, short descriptions of the changes the update provides. Any updates you do not wish to install can be de-selected here by unchecking the checkbox corresponding to the update.
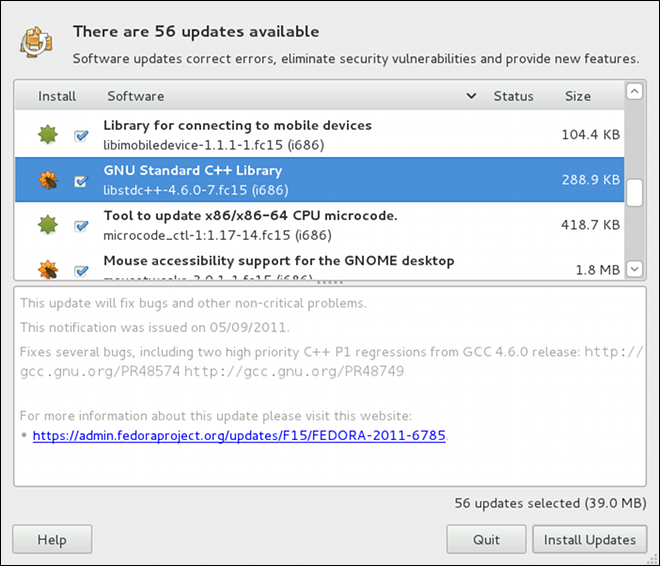
kernel package, then it will prompt you after installation, asking you whether you want to reboot the system and thereby boot into the newly-installed kernel.
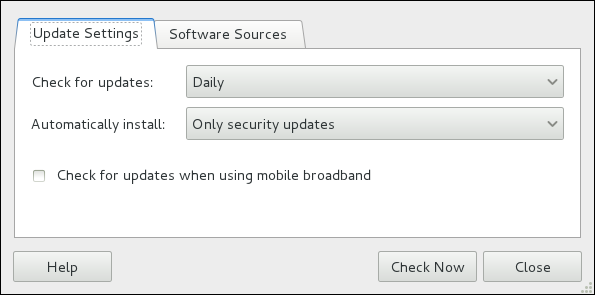
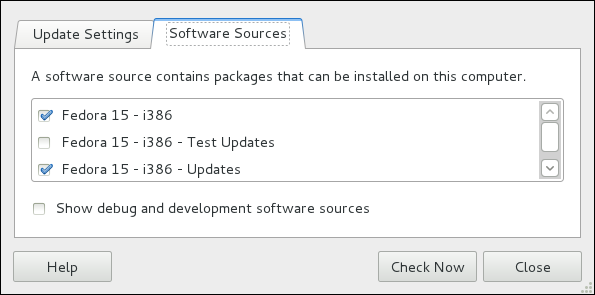
name=My Repository Name field of all [repository] sections in the /etc/yum.conf configuration file, and in all repository.repo/etc/yum.repos.d/ directory.
enabled=<1 or 0> field in [repository] sections. Checking an unchecked box enables the Yum repository, and unchecking it disables it. Performing either function causes PolicyKit to prompt for superuser authentication to enable or disable the repository. PackageKit actually inserts the enabled=<1 or 0> line into the correct [repository] section if it does not exist, or changes the value if it does. This means that enabling or disabling a repository through the Software Sources window causes that change to persist after closing the window or rebooting the system. The ability to quickly enable and disable repositories based on our needs is a highly-convenient feature of PackageKit.
gpk-application command at the shell prompt.
package_name-devel
package package-devel
package-libs
package-libs-devel
package-debuginfo
crontabs-1.10-32.1.el6.noarch.rpm) are never filtered out by checking . This filter has no affect on non-multilib systems, such as x86 machines.
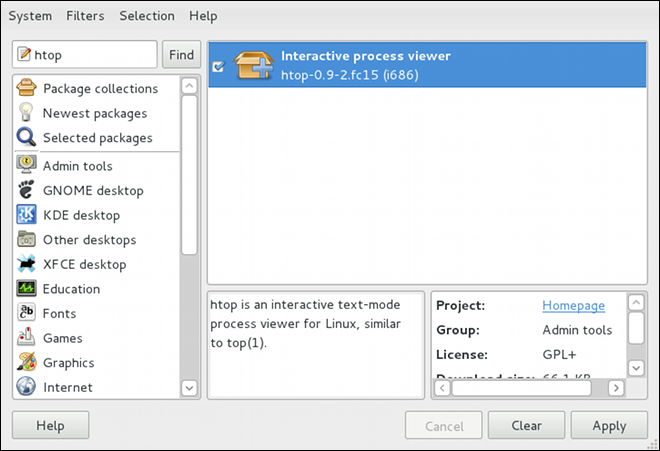
htop, a colorful and enhanced version of the top process viewer, by opening a shell prompt and entering:
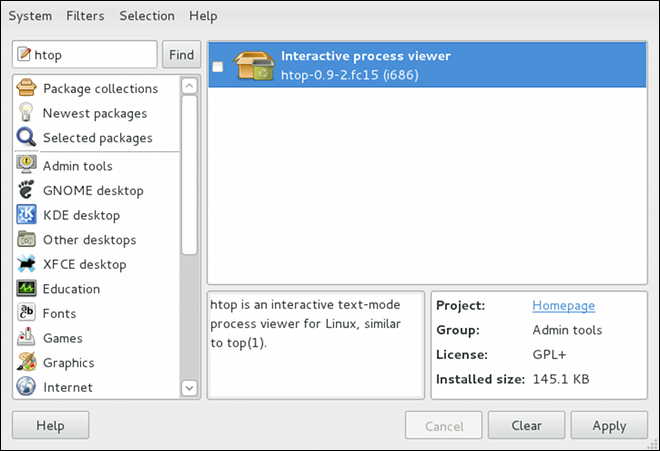
htoptop is good enough for us and we want to uninstall it. Remembering that we need to change the filter we recently used to install it to in → , we search for htop again and uncheck it. The program did not install any dependencies of its own; if it had, those would be automatically removed as well, as long as they were not also dependencies of any other packages still installed on our system.
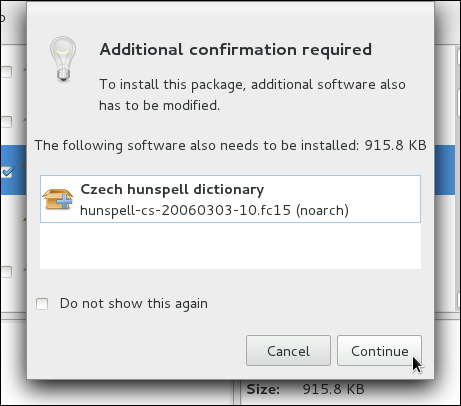
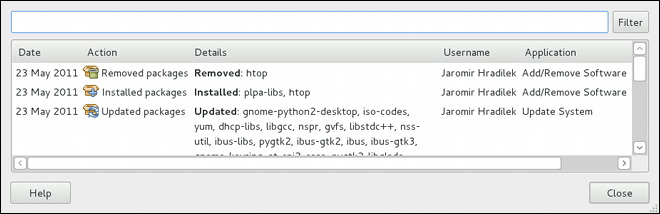
gpk-log command at the shell prompt.
Updated Packages or Installed Packages, the Date on which that action was performed, the Username of the user who performed the action, and the front end Application the user used (such as Add/Remove Software, or Update System). The Details column provides the types of the transactions, such as Updated, Installed, or Removed, as well as the list of packages the transactions were performed on.
packagekitd daemon back end, which communicates with a package manager-specific back end that utilizes Yum to perform the actual transactions, such as installing and removing packages, etc.
| Window Title | Function | How to Open | Shell Command |
|---|---|---|---|
| Add/Remove Software | Install, remove or view package info |
From the GNOME panel: → →
| gpk-application |
| Software Update | Perform package updates |
From the GNOME panel: → →
| gpk-update-viewer |
| Software Sources | Enable and disable Yum repositories |
From Add/Remove Software: →
| gpk-repo |
| Software Log Viewer | View the transaction log |
From Add/Remove Software: →
| gpk-log |
| Software Update Preferences | Set PackageKit preferences | gpk-prefs | |
| (Notification Area Alert) | Alerts you when updates are available |
From the GNOME panel: → → , Startup Programs tab
| gpk-update-icon |
packagekitd daemon runs outside the user session and communicates with the various graphical front ends. The packagekitd daemon[1] communicates via the DBus system message bus with another back end, which utilizes Yum's Python API to perform queries and make changes to the system. On Linux systems other than Red Hat Enterprise Linux and Fedora, packagekitd can communicate with other back ends that are able to utilize the native package manager for that system. This modular architecture provides the abstraction necessary for the graphical interfaces to work with many different package managers to perform essentially the same types of package management tasks. Learning how to use the PackageKit front ends means that you can use the same familiar graphical interface across many different Linux distributions, even when they utilize a native package manager other than Yum.
packagekitd daemon, which runs outside of the user session.
gnome-packagekit package instead of by PackageKit and its dependencies. Users working in a KDE environment may prefer to install the kpackagekit package, which provides a KDE interface for PackageKit.
pkcon.
systemctl command and can be turned on or off permanently by using the systemctl enable or systemctl disablecommands. They can typically be recognized by a «d» appended to their name, such as the packagekitd daemon. Refer to Глава 8, Services and Daemons for information about system services.
Содержание
DSL and PPPoE (Point-to-Point over Ethernet). In addition, NetworkManager allows for the configuration of network aliases, static routes, DNS information and VPN connections, as well as many connection-specific parameters. Finally, NetworkManager provides a rich API via D-Bus which allows applications to query and control network configuration and state.
system-config-network after its command line invocation. In Fedora 17, NetworkManager replaces the former Network Administration Tool while providing enhanced functionality, such as user-specific and mobile broadband configuration. It is also possible to configure the network in Fedora 17 by editing interface configuration files; refer to Глава 7, Сетевые интерфейсы for more information.
~]# yum install NetworkManager
~]# service NetworkManager status
NetworkManager (pid 1527) is running...
service command will report NetworkManager is stopped if the NetworkManager service is not running. To start it for the current session:
~]# service NetworkManager start
chkconfig command to ensure that NetworkManager starts up every time the system boots:
~]# chkconfig NetworkManager on

~]$ nm-applet &
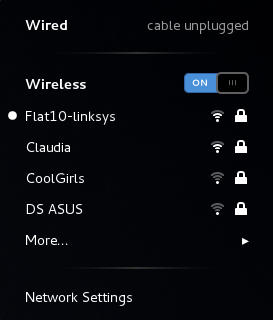
/etc/sysconfig/network-scripts/ directory (mainly in ifcfg-<network_type> interface configuration files), user connection settings are stored in the GConf configuration database and the GNOME keyring, and are only available during login sessions for the user who created them. Thus, logging out of the desktop session causes user-specific connections to become unavailable.
/etc/sysconfig/network-scripts/ directory, and to delete the GConf settings from the user's session. Conversely, converting a system to a user-specific connection causes NetworkManager to remove the system-wide configuration files and create the corresponding GConf/GNOME keyring settings.
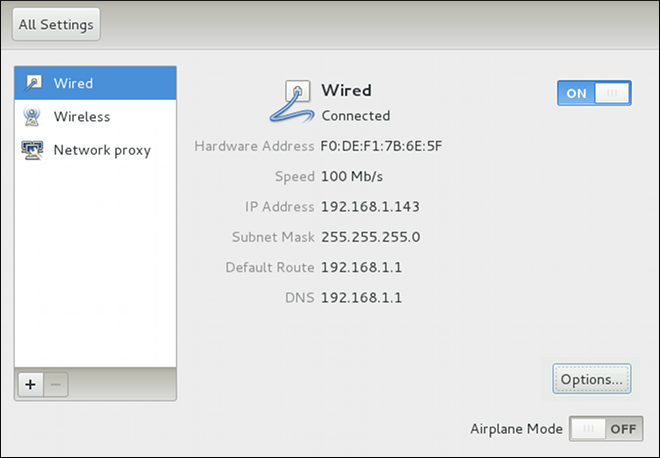
automatic. These defaults will suffice unless you are associating a wired connection with a second or specific NIC, or performing advanced networking. In such cases, refer to the following descriptions:
ip addr command will show the MAC address associated with each interface. For example, in the following ip addr output, the MAC address for the eth0 interface (which is 52:54:00:26:9e:f1) immediately follows the link/ether keyword:
~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 1000
link/ether 52:54:00:26:9e:f1 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.251/24 brd 192.168.122.255 scope global eth0
inet6 fe80::5054:ff:fe26:9ef1/64 scope link
valid_lft forever preferred_lft foreverip addr command, and then copy and paste that value into the MAC address text-entry field.
1500 when using IPv4, or a variable number 1280 or higher for IPv6, and does not generally need to be specified or changed.
a/b/g/n) connection to an Access Point.

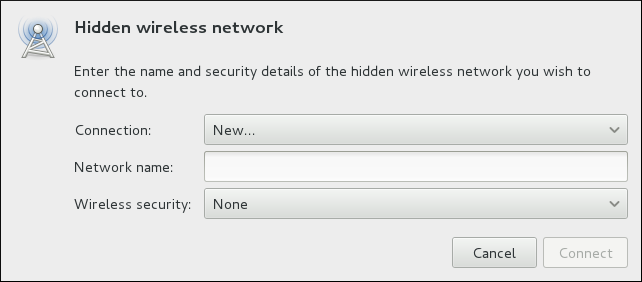
ip addr command will show the MAC address associated with each interface. For example, in the following ip addr output, the MAC address for the wlan0 interface (which is 00:1c:bf:02:f8:70) immediately follows the link/ether keyword:
~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 1000
link/ether 52:54:00:26:9e:f1 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.251/24 brd 192.168.122.255 scope global eth0
inet6 fe80::5054:ff:fe26:9ef1/64 scope link
valid_lft forever preferred_lft forever
3: wlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:1c:bf:02:f8:70 brd ff:ff:ff:ff:ff:ff
inet 10.200.130.67/24 brd 10.200.130.255 scope global wlan0
inet6 fe80::21c:bfff:fe02:f870/64 scope link
valid_lft forever preferred_lft foreverip addr command, and then copy and paste that value into the MAC address text-entry field.
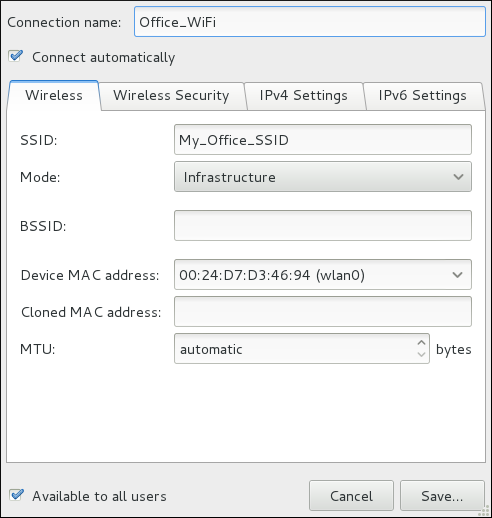
~]$ nm-connection-editor &
~]$ nm-connection-editor &
1 window then appears. This window presents settings customized for the type of VPN connection you selected in Шаг 5.
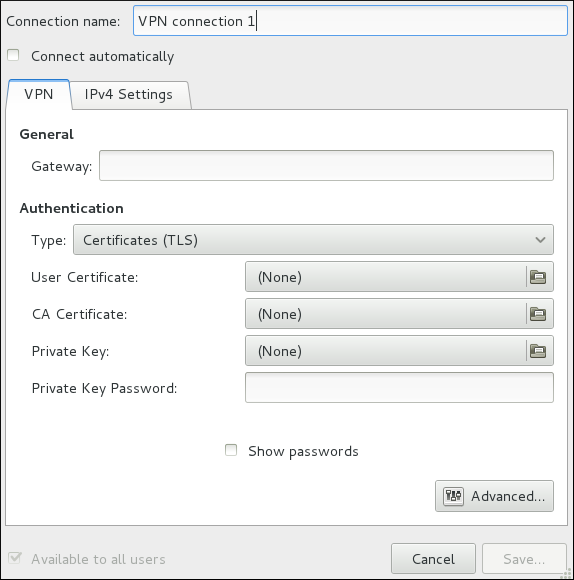
~]$ nm-connection-editor &
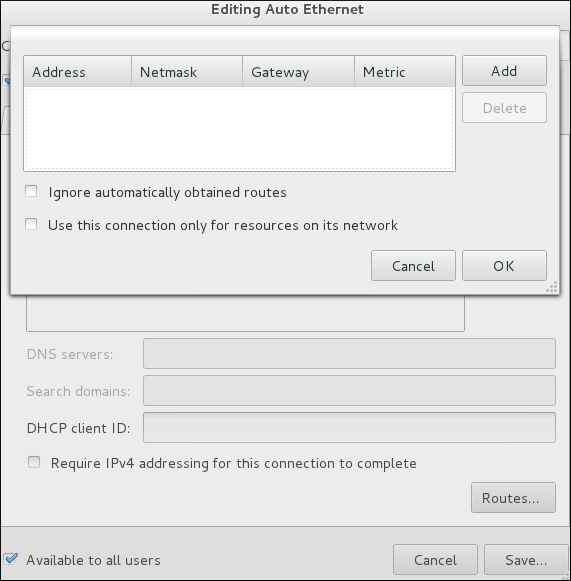
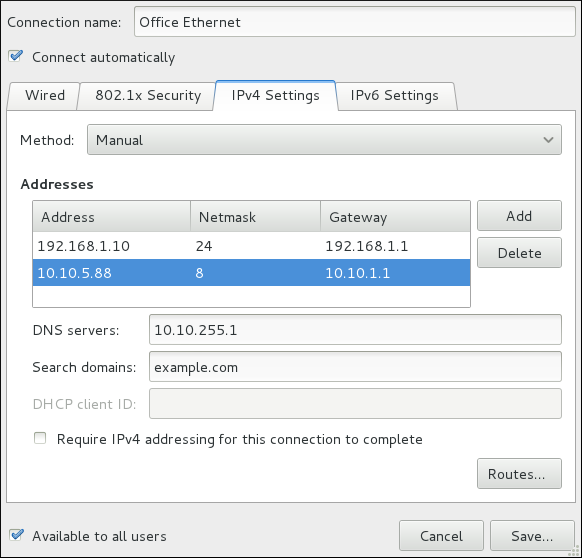
/etc/sysconfig/network-scripts/ directory. The scripts used to activate and deactivate these network interfaces are also located here. Although the number and type of interface files can differ from system to system, there are three categories of files that exist in this directory:
/etc/hosts 127.0.0.1) as localhost.localdomain. For more information, refer to the hosts(5) manual page.
/etc/resolv.conf /etc/sysconfig/network /etc/sysconfig/network-scripts/ifcfg-interface-name /etc/sysconfig/networking/ directory is used by the now deprecated Network Administration Tool (system-config-network). Its contents should not be edited manually. Using only one method for network configuration is strongly encouraged, due to the risk of configuration deletion. For more information about configuring network interfaces using graphical configuration tools, refer to Глава 6, NetworkManager.
ifcfg-name , where name refers to the name of the device that the configuration file controls.
/etc/sysconfig/network-scripts/ifcfg-eth0, which controls the first Ethernet network interface card or NIC in the system. In a system with multiple NICs, there are multiple ifcfg-ethX files (where X is a unique number corresponding to a specific interface). Because each device has its own configuration file, an administrator can control how each interface functions individually.
ifcfg-eth0 file for a system using a fixed IP address:
DEVICE=eth0 BOOTPROTO=none ONBOOT=yes NETMASK=255.255.255.0 IPADDR=10.0.1.27 USERCTL=no
ifcfg-eth0 file for an interface using DHCP looks different because IP information is provided by the DHCP server:
DEVICE=eth0 BOOTPROTO=dhcp ONBOOT=yes
BONDING_OPTS=parameters /etc/sysconfig/network-scripts/ifcfg-bondN (see Раздел 7.2.2, «Интерфейсы объединения каналов»). These parameters are identical to those used for bonding devices in /sys/class/net/bonding_device/bonding, and the module parameters for the bonding driver as described in bonding Module Directives.
BONDING_OPTS directive in ifcfg-name. Do not specify options for the bonding device in /etc/modprobe.d/bonding.conf, or in the deprecated /etc/modprobe.conf file.
BOOTPROTO=protocol protocol is one of the following:
none — No boot-time protocol should be used.
bootp — The BOOTP protocol should be used.
dhcp — The DHCP protocol should be used.
BROADCAST=addressaddress is the broadcast address. This directive is deprecated, as the value is calculated automatically with ipcalc.
DEVICE=name name is the name of the physical device (except for dynamically-allocated PPP devices where it is the logical name).
DHCP_HOSTNAME=namename is a short hostname to be sent to the DHCP server. Use this option only if the DHCP server requires the client to specify a hostname before receiving an IP address.
DNS{1,2}=addressaddress is a name server address to be placed in /etc/resolv.conf if the PEERDNS directive is set to yes.
ETHTOOL_OPTS=options options are any device-specific options supported by ethtool. For example, if you wanted to force 100Mb, full duplex:
ETHTOOL_OPTS="autoneg off speed 100 duplex full"
ETHTOOL_OPTS to set the interface speed and duplex settings. Custom initscripts run outside of the network init script lead to unpredictable results during a post-boot network service restart.
autoneg off option. This option needs to be stated first, as the option entries are order-dependent.
HOTPLUG=answeranswer is one of the following:
yes — This device should be activated when it is hot-plugged (this is the default option).
no — This device should not be activated when it is hot-plugged.
HOTPLUG=no option can be used to prevent a channel bonding interface from being activated when a bonding kernel module is loaded.
HWADDR=MAC-address MAC-address is the hardware address of the Ethernet device in the form AA:BB:CC:DD:EE:FF. This directive must be used in machines containing more than one NIC to ensure that the interfaces are assigned the correct device names regardless of the configured load order for each NIC's module. This directive should not be used in conjunction with MACADDR.
/etc/udev/rules.d/70-persistent-net.rules.
IPADDR=address address is the IP address.
LINKDELAY=time time is the number of seconds to wait for link negotiation before configuring the device.
MACADDR=MAC-address MAC-address is the hardware address of the Ethernet device in the form AA:BB:CC:DD:EE:FF.
HWADDR directive.
MASTER=bond-interface bond-interface is the channel bonding interface to which the Ethernet interface is linked.
SLAVE directive.
NETMASK=mask mask is the netmask value.
NETWORK=address address is the network address. This directive is deprecated, as the value is calculated automatically with ipcalc.
NM_CONTROLLED=answer answer is one of the following:
yes — NetworkManager is permitted to configure this device.This is the default behavior and can be omitted.
no — NetworkManager is not permitted to configure this device.
ONBOOT=answeranswer is one of the following:
yes — This device should be activated at boot-time.
no — This device should not be activated at boot-time.
PEERDNS=answeranswer is one of the following:
yes — Modify /etc/resolv.conf if the DNS directive is set. If using DHCP, then yes is the default.
no — Do not modify /etc/resolv.conf.
SLAVE=answeranswer is one of the following:
yes — This device is controlled by the channel bonding interface specified in the MASTER directive.
no — This device is not controlled by the channel bonding interface specified in the MASTER directive.
MASTER directive.
SRCADDR=address address is the specified source IP address for outgoing packets.
USERCTL=answer answer is one of the following:
yes — Non-root users are allowed to control this device.
no — Non-root users are not allowed to control this device.
bonding kernel module and a special network interface called a channel bonding interface. Channel bonding enables two or more network interfaces to act as one, simultaneously increasing the bandwidth and providing redundancy.
/etc/sysconfig/network-scripts/ directory called ifcfg-bondN, replacing N with the number for the interface, such as 0.
DEVICE directive is bondN, replacing N with the number for the interface.
DEVICE=bond0
IPADDR=192.168.1.1
NETMASK=255.255.255.0
ONBOOT=yes
BOOTPROTO=none
USERCTL=no
BONDING_OPTS="bonding parameters separated by spaces"MASTER and SLAVE directives to their configuration files. The configuration files for each of the channel-bonded interfaces can be nearly identical.
eth0 and eth1 may look like the following example:
DEVICE=ethN
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes
USERCTL=noN with the numerical value for the interface.
bonding.conf/etc/modprobe.d/ directory. Note that you can name this file anything you like as long as it ends with a .conf extension. Insert the following line in this new file:
alias bondN bondingN with the interface number, such as 0. For each configured channel bonding interface, there must be a corresponding entry in your new /etc/modprobe.d/bonding.conf file.
BONDING_OPTS="bonding parameters" directive in the ifcfg-bondN interface file. Do not specify options for the bonding device in /etc/modprobe.d/bonding.conf, or in the deprecated /etc/modprobe.conf file. For further instructions and advice on configuring the bonding module and to view the list of bonding parameters, refer to Раздел 23.7.2, «Using Channel Bonding».
/etc/sysconfig/network-scripts/ directory called ifcfg-brN, replacing N with the number for the interface, such as 0.
DEVICE directive is given an interface name as its argument in the format brN, where N is replaced with the number of the interface.
TYPE directive is given an argument Bridge or Ethernet. This directive determines the device type and the argument is case sensitive.
DELAY=0, is added to prevent the bridge from waiting while it monitors traffic, learns where hosts are located, and builds a table of MAC addresses on which to base its filtering decisions. The default delay of 30 seconds is not needed if no routing loops are possible.
NM_CONTROLLED=no should be added to the Ethernet interface to prevent NetworkManager from altering the file. It can also be added to the bridge configuration file in case future versions of NetworkManager support bridge configuration.
DEVICE=br0 TYPE=Bridge IPADDR=192.168.1.1 NETMASK=255.255.255.0 ONBOOT=yes BOOTPROTO=static NM_CONTROLLED=no DELAY=0
/etc/sysconfig/network-scripts/ifcfg-ethX, where X is a unique number corresponding to a specific interface, as follows:
DEVICE=ethX TYPE=Ethernet HWADDR=AA:BB:CC:DD:EE:FF BOOTPROTO=none ONBOOT=yes NM_CONTROLLED=no BRIDGE=br0
DEVICE directive, almost any interface name could be used as it does not determine the device type. Other commonly used names include tap, dummy and bond for example. TYPE=Ethernet is not strictly required. If the TYPE directive is not set, the device is treated as an Ethernet device (unless it's name explicitly matches a different interface configuration file.)
root:
systemctl restart network.service DEVICE=ethX TYPE=Ethernet USERCTL=no SLAVE=yes MASTER=bond0 BOOTPROTO=none HWADDR=AA:BB:CC:DD:EE:FF NM_CONTROLLED=no
ethX as the interface name is common practice but almost any name could be used. Names such as tap, dummy and bond are commonly used.
/etc/sysconfig/network-scripts/ifcfg-bond0, as follows:
DEVICE=bond0 ONBOOT=yes BONDING_OPTS='mode=1 miimon=100' BRIDGE=brbond0 NM_CONTROLLED=noFor further instructions and advice on configuring the bonding module and to view the list of bonding parameters, refer to Раздел 23.7.2, «Using Channel Bonding».
/etc/sysconfig/network-scripts/ifcfg-brbond0, as follows:
DEVICE=brbond0 ONBOOT=yes TYPE=Bridge IPADDR=192.168.1.1 NETMASK=255.255.255.0 NM_CONTROLLED=no
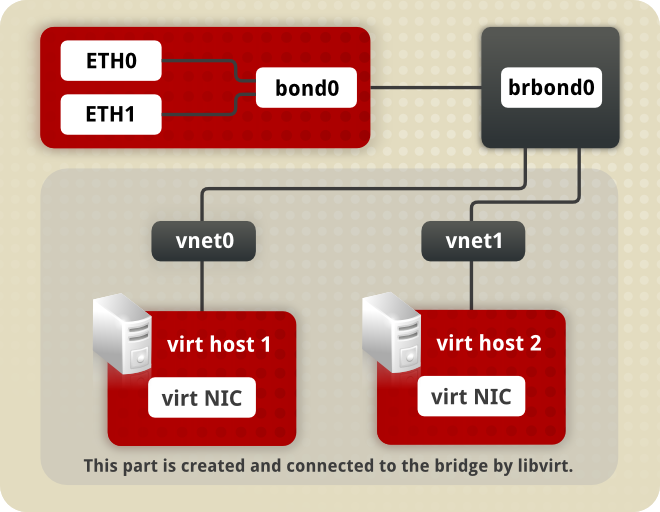
bond 0. This in turn leads to a virtual interface called BR Bond 0 on the right. From there a path leads to a virtual network below.
MASTER=bond0 directive. These point to the configuration file named /etc/sysconfig/network-scripts/ifcfg-bond0, which contains the DEVICE=bond0 directive. This ifcfg-bond0 in turn points to the /etc/sysconfig/network-scripts/ifcfg-brbond0 configuration file, which contains the IP address, and acts as an interface to the virtual networks inside the host.
root:
systemctl restart network.service lsmod | grep 8021qmodprobe 8021q/etc/sysconfig/network-scripts/ifcfg-ethX, where X is a unique number corresponding to a specific interface, as follows:
DEVICE=ethX TYPE=Ethernet BOOTPROTO=none ONBOOT=yes
/etc/sysconfig/network-scripts. The configuration filename should be the physical interface plus a . character plus the VLAN ID number. For example, if the VLAN ID is 192, and the physical interface is eth0, then the configuration filename should be ifcfg-eth0.192:
DEVICE=ethX.192 BOOTPROTO=static ONBOOT=yes IPADDR=192.168.1.1 NETMASK=255.255.255.0 USERCTL=no NETWORK=192.168.1.0 VLAN=yes
eth0 , add a new file with the name eth0.193 with the VLAN configuration details.
root:
systemctl restart network.service ip command of the iproute package now supports assigning multiple address to the same interface it is no longer necessary to use this method of binding multiple addresses to the same interface.
ifcfg files. For example, if ifcfg-eth0 and ifcfg-eth0:1 files are present, NetworkManager creates two connections, which will cause confusion.
ifcfg-if-name:alias-value naming scheme.
ifcfg-eth0:0 file could be configured to specify DEVICE=eth0:0 and a static IP address of 10.0.0.2, serving as an alias of an Ethernet interface already configured to receive its IP information via DHCP in ifcfg-eth0. Under this configuration, eth0 is bound to a dynamic IP address, but the same physical network card can receive requests via the fixed, 10.0.0.2 IP address.
ifcfg-if-name-clone-name. While an alias file allows multiple addresses for an existing interface, a clone file is used to specify additional options for an interface. For example, a standard DHCP Ethernet interface called eth0, may look similar to this:
DEVICE=eth0 ONBOOT=yes BOOTPROTO=dhcp
USERCTL directive is no if it is not specified, users cannot bring this interface up and down. To give users the ability to control the interface, create a clone by copying ifcfg-eth0 to ifcfg-eth0-user and add the following line to ifcfg-eth0-user:
USERCTL=yes
eth0 interface using the /sbin/ifup eth0-user command because the configuration options from ifcfg-eth0 and ifcfg-eth0-user are combined. While this is a very basic example, this method can be used with a variety of options and interfaces.
ifcfg-pppX X is a unique number corresponding to a specific interface.
wvdial, the Network Administration Tool or Kppp is used to create a dialup account. It is also possible to create and edit this file manually.
ifcfg-ppp0 file:
DEVICE=ppp0 NAME=test WVDIALSECT=test MODEMPORT=/dev/modem LINESPEED=115200 PAPNAME=test USERCTL=true ONBOOT=no PERSIST=no DEFROUTE=yes PEERDNS=yes DEMAND=no IDLETIMEOUT=600
ifcfg-sl0.
DEFROUTE=answer answer is one of the following:
yes — Set this interface as the default route.
no — Do not set this interface as the default route.
DEMAND=answeranswer is one of the following:
yes — This interface allows pppd to initiate a connection when someone attempts to use it.
no — A connection must be manually established for this interface.
IDLETIMEOUT=valuevalue is the number of seconds of idle activity before the interface disconnects itself.
INITSTRING=stringstring is the initialization string passed to the modem device. This option is primarily used in conjunction with SLIP interfaces.
LINESPEED=valuevalue is the baud rate of the device. Possible standard values include 57600, 38400, 19200, and 9600.
MODEMPORT=devicedevice is the name of the serial device that is used to establish the connection for the interface.
MTU=valuevalue is the Maximum Transfer Unit (MTU) setting for the interface. The MTU refers to the largest number of bytes of data a frame can carry, not counting its header information. In some dialup situations, setting this to a value of 576 results in fewer packets dropped and a slight improvement to the throughput for a connection.
NAME=namename is the reference to the title given to a collection of dialup connection configurations.
PAPNAME=namename is the username given during the Password Authentication Protocol (PAP) exchange that occurs to allow connections to a remote system.
PERSIST=answeranswer is one of the following:
yes — This interface should be kept active at all times, even if deactivated after a modem hang up.
no — This interface should not be kept active at all times.
REMIP=addressaddress is the IP address of the remote system. This is usually left unspecified.
WVDIALSECT=name name associates this interface with a dialer configuration in /etc/wvdial.conf. This file contains the phone number to be dialed and other important information for the interface.
ifcfg-lo /etc/sysconfig/network-scripts/ifcfg-lo, should never be edited manually. Doing so can prevent the system from operating correctly.
ifcfg-irlan0 ifcfg-plip0 /etc/sysconfig/network-scripts/ directory: /sbin/ifdown and /sbin/ifup.
ifup and ifdown interface scripts are symbolic links to scripts in the /sbin/ directory. When either of these scripts are called, they require the value of the interface to be specified, such as:
ifup eth0ifup and ifdown interface scripts are the only scripts that the user should use to bring up and take down network interfaces.
/etc/rc.d/init.d/functions and /etc/sysconfig/network-scripts/network-functions. Refer to Раздел 7.5, «Файлы сетевых функций» for more information.
/etc/sysconfig/network-scripts/ directory:
ifup-aliases ifup-ippp and ifdown-ippp ifup-ipv6 and ifdown-ipv6 ifup-plip ifup-plusb ifup-post and ifdown-post ifup-ppp and ifdown-ppp ifup-routes ifdown-sit and ifup-sit ifup-wireless /etc/sysconfig/network-scripts/ directory can cause interface connections to act irregularly or fail. Only advanced users should modify scripts related to a network interface.
systemctl command on the network service (/etc/rc.d/init.d/network), as illustrated by the following command:
systemctl action network.serviceaction can be either start, stop, or restart.
systemctl status network.serviceip route command to display the IP routing table. If static routes are required, they can be added to the routing table by means of the ip route add command and removed using the ip route del command. To add a static route to a host address, that is to say to a single IP address, issue the following command as root:
ip route add X.X.X.X
where X.X.X.X is the IP address of the host in dotted decimal notation. To add a static route to a network, that is to say to an IP address representing a range of IP addresses, issue the following command as root:
ip route add X.X.X.X/Y
where X.X.X.X is the IP address of the network in dotted decimal notation and Y is the network prefix. The network prefix is the number of enabled bits in the subnet mask. This format of network address slash prefix length is referred to as CIDR notation.
/etc/sysconfig/network-scripts/route-interface file. For example, static routes for the eth0 interface would be stored in the /etc/sysconfig/network-scripts/route-eth0 file. The route-interface file has two formats: IP command arguments and network/netmask directives. These are described below.
/etc/sysconfig/network file. This file specifies gateway and host information for all network interfaces. For more information about this file and the directives it accepts, refer to Раздел D.1.13, « /etc/sysconfig/network ».
default viaX.X.X.Xdevinterface
X.X.X.X is the IP address of the default gateway. The interface is the interface that is connected to, or can reach, the default gateway. The dev option can be omitted, it is optional.
X.X.X.X/YviaX.X.X.Xdevinterface
X.X.X.X/Y is the network address and netmask for the static route. X.X.X.X and interface are the IP address and interface for the default gateway respectively. The X.X.X.X address does not have to be the default gateway IP address. In most cases, X.X.X.X will be an IP address in a different subnet, and interface will be the interface that is connected to, or can reach, that subnet. Add as many static routes as required.
route-eth0 file using the IP command arguments format. The default gateway is 192.168.0.1, interface eth0. The two static routes are for the 10.10.10.0/24 and 172.16.1.0/24 networks:
default via 192.168.0.1 dev eth0 10.10.10.0/24 via 192.168.0.1 dev eth0 172.16.1.0/24 via 192.168.0.1 dev eth0
eth0 interface in the 192.168.0.0/24 subnet, and an eth1 interface (10.10.10.1) in the 10.10.10.0/24 subnet:
10.10.10.0/24 via 10.10.10.1 dev eth1
ifup command: "RTNETLINK answers: File exists" or 'Error: either "to" is a duplicate, or "X.X.X.X" is a garbage.', where X.X.X.X is the gateway, or a different IP address. These errors can also occur if you have another route to another network using the default gateway. Both of these errors are safe to ignore.
route-interface files. The following is a template for the network/netmask format, with instructions following afterwards:
ADDRESS0=X.X.X.XNETMASK0=X.X.X.XGATEWAY0=X.X.X.X
ADDRESS0=X.X.X.X is the network number for the static route.
NETMASK0=X.X.X.X is the netmask for the network number defined with ADDRESS0=X.X.X.X.
GATEWAY0=X.X.X.X is the default gateway, or an IP address that can be used to reach ADDRESS0=X.X.X.X
route-eth0 file using the network/netmask directives format. The default gateway is 192.168.0.1, interface eth0. The two static routes are for the 10.10.10.0/24 and 172.16.1.0/24 networks. However, as mentioned before, this example is not necessary as the 10.10.10.0/24 and 172.16.1.0/24 networks would use the default gateway anyway:
ADDRESS0=10.10.10.0 NETMASK0=255.255.255.0 GATEWAY0=192.168.0.1 ADDRESS1=172.16.1.0 NETMASK1=255.255.255.0 GATEWAY1=192.168.0.1
ADDRESS0, ADDRESS1, ADDRESS2, and so on.
eth0 interface in the 192.168.0.0/24 subnet, and an eth1 interface (10.10.10.1) in the 10.10.10.0/24 subnet:
ADDRESS0=10.10.10.0 NETMASK0=255.255.255.0 GATEWAY0=10.10.10.1
/etc/sysconfig/network-scripts/network-functions file contains the most commonly used IPv4 functions, which are useful to many interface control scripts. These functions include contacting running programs that have requested information about changes in the status of an interface, setting hostnames, finding a gateway device, verifying whether or not a particular device is down, and adding a default route.
/etc/sysconfig/network-scripts/network-functions-ipv6 file exists specifically to hold this information. The functions in this file configure and delete static IPv6 routes, create and remove tunnels, add and remove IPv6 addresses to an interface, and test for the existence of an IPv6 address on an interface.
/usr/share/doc/initscripts-version/sysconfig.txt httpd if you are running a web server). However, if you do not need to provide a service, you should turn it off to minimize your exposure to possible bug exploits.
/etc/rc.d/init.d/ directory, it is advised that you use the systemctl utility.
irqbalance service is enabled. In most cases, this service is installed and configured to run during the Fedora 17 installation. To verify that irqbalance is running, type the following at a shell prompt:
systemctl status irqbalance.servicesystemctl command in the following form:
systemctlenableservice_name.service
httpd service by typing the following at a shell prompt as root:
~]# systemctl enable httpd.servicesystemctl command in the following form:
systemctldisableservice_name.service
telnet service is disabled by running the following command as root:
~]# systemctl disable telnet.service/etc/rc.d/init.d/ directory, it is advised that you use the systemctl utility.
systemctl command in the following form:
systemctlstatusservice_name.service
systemctl command in the following form instead:
systemctlis-activeservice_name.service
httpd service at boot time. Imagine that the system has been restarted and you need to verify that the service is really running. You can do so by typing the following at a shell prompt:
~]$ systemctl is-active httpd.service
active~]$ systemctl status httpd.service
httpd.service - LSB: start and stop Apache HTTP Server
Loaded: loaded (/etc/rc.d/init.d/httpd)
Active: active (running) since Mon, 23 May 2011 21:38:57 +0200; 27s ago
Process: 2997 ExecStart=/etc/rc.d/init.d/httpd start (code=exited, status=0/SUCCESS)
Main PID: 3002 (httpd)
CGroup: name=systemd:/system/httpd.service
├ 3002 /usr/sbin/httpd
├ 3004 /usr/sbin/httpd
├ 3005 /usr/sbin/httpd
├ 3006 /usr/sbin/httpd
├ 3007 /usr/sbin/httpd
├ 3008 /usr/sbin/httpd
├ 3009 /usr/sbin/httpd
├ 3010 /usr/sbin/httpd
└ 3011 /usr/sbin/httpdsystemctl list-units --type=serviceUNIT — A systemd unit name. In this case, a service name.
LOAD — Information whether the systemd unit was properly loaded.
ACTIVE — A high-level unit activation state.
SUB — A low-level unit activation state.
JOB — A pending job for the unit.
DESCRIPTION — A brief description of the unit.
~]$ systemctl list-units --type=service
UNIT LOAD ACTIVE SUB JOB DESCRIPTION
abrt-ccpp.service loaded active exited LSB: Installs coredump handler which saves segfault data
abrt-oops.service loaded active running LSB: Watches system log for oops messages, creates ABRT dump directories for each oops
abrtd.service loaded active running ABRT Automated Bug Reporting Tool
accounts-daemon.service loaded active running Accounts Service
atd.service loaded active running Job spooling tools
[output truncated]abrtd service is loaded, active, and running, and it does not have any pending jobs.
systemctl command in the following form:
systemctlstartservice_name.service
httpd service at boot time. You can start the service immediately by typing the following at a shell prompt as root:
~]# systemctl start httpd.servicesystemctl command in the following form:
systemctlstopservice_name.service
telnet service at boot time. You can stop the service immediately by running the following command as root:
~]# systemctl stop telnet.servicesystemctl command in the following form:
systemctlrestartservice_name.service
/etc/ssh/sshd_config configuration file to take effect, it is required that you restart the sshd service. You can do so by typing the following at a shell prompt as root:
~]# systemctl restart sshd.servicesystemctl(1) — The manual page for the systemctl utility.
system-config-authentication at a shell prompt (for example, in an XTerm or a GNOME terminal).
LDAP server.
Transport Layer Security (TLC) will be used to encrypt passwords sent to the LDAP server. The option allows you to specify a URL from which to download a valid Certificate Authority certificate (CA). A valid CA certificate must be in the Privacy Enhanced Mail (PEM) format.
ldaps:// server address is specified in the LDAP Server field.
openldap-clients package must be installed for this option to work.
kadmind.
krb5-libs and krb5-workstation packages must be installed for this option to work. For more information about Kerberos, refer to section Using Kerberos of the Fedora 17 Managing Single Sign-On and Smart Cards guide.
ldaps:// server address or use TLS for LDAP authentication.
portmap and ypbind services are started and are also enabled to start at boot time.
krb5-server package must be installed, and Kerberos must be configured properly.
winbind should use. For more information about domain controllers, please refer to Раздел 16.1.6.3, «Domain Controller».
winbindd daemon uses the value chosen here to specify the login shell for that user.
winbindd service, refer to Раздел 16.1.2, «Samba Daemons and Related Services».
/etc/security/access.conf is consulted for authorization of a user.
authconfig man page or by typing authconfig --help at the shell prompt.
| Option | Description |
|---|---|
--enableshadow, --useshadow
| Enable shadow passwords |
--disableshadow
| Disable shadow passwords |
--passalgo=
| Hash/crypt algorithm to be used |
--enablenis
| Enable NIS for user account configuration |
--disablenis
| Disable NIS for user account configuration |
--nisdomain=
| Specify an NIS domain |
--nisserver=
| Specify an NIS server |
--enableldap
| Enable LDAP for user account configuration |
--disableldap
| Disable LDAP for user account configuration |
--enableldaptls
| Enable use of TLS with LDAP |
--disableldaptls
| Disable use of TLS with LDAP |
--enablerfc2307bis
| Enable use of RFC-2307bis schema for LDAP user information lookups |
--disablerfc2307bis
| Disable use of RFC-2307bis schema for LDAP user information lookups |
--enableldapauth
| Enable LDAP for authentication |
--disableldapauth
| Disable LDAP for authentication |
--ldapserver=
| Specify an LDAP server |
--ldapbasedn=
| Specify an LDAP base DN (Distinguished Name) |
--ldaploadcacert=
| Load a CA certificate from the specified URL |
--enablekrb5
| Enable Kerberos for authentication |
--disablekrb5
| Disable Kerberos for authentication |
--krb5kdc=
| Specify Kerberos KDC server |
--krb5adminserver=
| Specify Kerberos administration server |
--krb5realm=
| Specify Kerberos realm |
--enablekrb5kdcdns
| Enable use of DNS to find Kerberos KDCs |
--disablekrb5kdcdns
| Disable use of DNS to find Kerberos KDCs |
--enablekrb5realmdns
| Enable use of DNS to find Kerberos realms |
--disablekrb5realmdns
| Disable use of DNS to find Kerberos realms |
--enablewinbind
| Enable winbind for user account configuration |
--disablewinbind
| Disable winbind for user account configuration |
--enablewinbindauth
| Enable winbindauth for authentication |
--disablewinbindauth
| Disable winbindauth for authentication |
--winbindseparator=
|
Character used to separate the domain and user part of winbind usernames if winbindusedefaultdomain is not enabled
|
--winbindtemplatehomedir=
| Directory that winbind users have as their home |
--winbindtemplateprimarygroup=
| Group that winbind users have as their primary group |
--winbindtemplateshell=
| Shell that winbind users have as their default login shell |
--enablewinbindusedefaultdomain
| Configures winbind to assume that users with no domain in their usernames are domain users |
--disablewinbindusedefaultdomain
| Configures winbind to assume that users with no domain in their usernames are not domain users |
--winbindjoin=
| Joins the winbind domain or ADS realm as the specified administrator |
--enablewinbindoffline
| Configures winbind to allow offline login |
--disablewinbindoffline
| Configures winbind to prevent offline login |
--smbsecurity=
| Security mode to use for the Samba and Winbind services |
--smbrealm=
| Default realm for Samba and Winbind services when security is set to |
--enablewins
| Enable Wins for hostname resolution |
--disablewins
| Disable Wins for hostname resolution |
--enablesssd
| Enable SSSD for user information |
--disablesssd
| Disable SSSD for user information |
--enablecache
|
Enable nscd
|
--disablecache
|
Disable nscd
|
--enablelocauthorize
| Local authorization is sufficient for local users |
--disablelocauthorize
| Local users are also authorized through a remote service |
--enablesysnetauth
| Authenticate system accounts with network services |
--disablesysnetauth
| Authenticate system accounts with local files only |
--enablepamaccess
|
Check /etc/security/access.conf during account authorization
|
--disablepamaccess
|
Do not check /etc/security/access.conf during account authorization
|
--enablemkhomedir
| Create a home directory for a user on the first login |
--disablemkhomedir
| Do not create a home directory for a user on the first login |
--enablesmartcard
| Enable authentication with a smart card |
--disablesmartcard
| Disable authentication with a smart card |
--enablerequiresmartcard
| Require smart card for authentication |
--disablerequiresmartcard
| Do not require smart card for authentication |
--smartcardmodule=
| Default smart card module to use |
--smartcardaction=
| Action to be taken when smart card removal is detected |
--enablefingerprint
| Enable fingerprint authentication |
--disablefingerprint
| Disable fingerprint authentication |
--nostart
|
Do not start or stop the portmap, ypbind, or nscd services even if they are configured
|
--test
| Do not update the configuration files, only print the new settings |
--update, --kickstart
|
Opposite of --test, update configuration files with changed settings
|
--updateall
| Update all configuration files |
--probe
| Probe and display network defaults |
--savebackup=
| Save a backup of all configuration files |
--restorebackup=
| Restore a backup of all configuration files |
--restorelastbackup
| Restore the backup of configuration files saved before the previous configuration change |
nsswitch.conf, через который можно запрашивать данные о пользователях только через один сервер любого типа (LDAP, NIS и так далее). В SSSD вы сможете создавать несколько доменов одного типа либо различные типы идентификационного провайдера.
sssd и удалив соответствующий файл кэша. Обычно такие файлы хранятся в каталоге /var/lib/sss/db/.
cache_DOMAINNAME.ldb.
/etc/sssd/sssd.conf установить параметр ldap_referrals в значение TRUE. Этот параметр включит анонимный доступ к второму серверу LDAP.
kate в домене ldap.example.com от пользователя kate в домене ldap.myhome.com. Этого можно добиться, заставив SSSD использовать полные имена в запросах. Запросив информацию о kate, вы получите пользователя из того домена, который был указан первым в конфигурации. Однако если же вы запросите пользователя kate@ldap.myhome.com, то получите информацию о нем.
filter_users, с помощью которого можно исключать определенных пользователей из полученного от базы данных списка. Более полная информация по этому параметру доступна в man-странице sssd.conf(5).
ipa_dyndns_update, используемый для включения динамического обновления, и ipa_dyndns_iface, который указывает сетевой интерфейс, IP-адрес которого будет использоваться при обновлении DNS.
# yum install sssd
/etc/sssd/sssd.conf до нового формата, сделав предварительно резервную копию существующей конфигурации под именем /etc/sssd/sssd.conf.bak.
upgrade_config.py [
-f INFILE
] [
-o OUTFILE
] [
-verbose
] [
--no-backup
]
-f INFILE — обновляемый конфигурационный файл. Если не указано, то по умолчанию будет использоваться /etc/sssd/sssd.conf;
-o OUTFILE — имя обновленного конфигурационного файла. Если не указано, то по умолчанию будет использоваться /etc/sssd/sssd.conf;
-verbose — выводить более подробную информацию во время процесса обновления;
--no-backup — не создавать резервный файл. Если не указано, по умолчанию будет использоваться INFILE.bakservice, так и сценарий /etc/init.d/sssd. Например, следующая команду запустит sssd:
# systemctl start sssd.service
systemctl:
# systemctl enable sssd.service
/etc/sssd/sssd.conf, в котором содержатся различные секции, каждая из которых содержит несколько пар ключ/значение. Некоторые ключи могут принимать несколько значений; для таких ключей следует использовать запятые для разделения нескольких значений. В конфигурационном файле используются типы данных string (без кавычек), integer и Boolean (который может принимать значения TRUE или FALSE). Комментарий предваряются либо знаком октоторпа (#), либо точкой с запятой (;) в начале строки. Синтаксис продемонстрирован в следующем примере:
[section] # Ключи с единственным значением key1 = value key2 = val2 # Ключи с несколькими значениями key10 = val10,val11
-c (или --config).
sssd_nss, с помощью которого вы сможете настроить свою систему для получения информации о пользователях через SSSD. Для этого нужно изменить файл /etc/nsswitch.conf таким образом, чтобы система использовала базу данных sss, как указано в примере:
passwd: files sss group: files sss
/etc/pam.d/system-auth. Внесите в него изменения, соответствующие приведенному примеру, после чего перезапустите sssd:
#%PAM-1.0 # This file is auto-generated. # User changes will be destroyed the next time authconfig is run. auth required pam_env.so auth sufficient pam_unix.so nullok try_first_pass auth requisite pam_succeed_if.so uid >= 500 quiet auth sufficient pam_sss.so use_first_pass auth required pam_deny.so account required pam_unix.so broken_shadow account sufficient pam_localuser.so account sufficient pam_succeed_if.so uid < 500 quiet account [default=bad success=ok user_unknown=ignore] pam_sss.so account required pam_permit.so password requisite pam_cracklib.so try_first_pass retry=3 password sufficient pam_unix.so sha512 shadow nullok try_first_pass use_authtok password sufficient pam_sss.so use_authtok password required pam_deny.so session required pam_mkhomedir.so umask=0022 skel=/etc/skel/ session optional pam_keyinit.so revoke session required pam_limits.so session [success=1 default=ignore] pam_succeed_if.so service in crond quiet use_uid session sufficient pam_sss.so session required pam_unix.so
/home, а система настроена на создание домашнего каталога при первом входе пользователя, то такой каталог будет создан с неправильными правами. Например, если вместо привычного /home/<username> у ваших пользователей в названии каталога используется родная локаль (например, /home/<locale>/<username>), то вам заблаговременно следует выполнить следующие действия:
/home к используемому в системе хранилищу домашних каталогов. В указанном выше примере этого можно достичь, запустив следующую команду (замените имена каталогов на те, что используются в вашей системе):
# semanage fcontext -a -e /home /home/locale
pam_oddjob_mkhomedir.so, с помощью которой утилита конфигурации аутентификации создаст нестандартные домашние каталоги. Вам нужна именно эта библиотека, поскольку она, в отличие от используемой по умолчанию pam_mkhomedir.so, способна создавать ярлыки SELinux.
pam_oddjob_mkhomedir.so будет использовать именно ее. В ином случае по умолчанию будет использоваться pam_mkhomedir.so.
# semanage fcontext -a -e /home /home/locale # restorecon -R -v /home/locale
include в конфигурационных файлах. Пример:
... session include system-auth session optional pam_console.so ...
sufficient из файла system-auth вернет PAM_SUCCESS, то pam_console.so применяться не будет.
access_provider в секции [domain/<NAME>] файла /etc/sssd/sssd.conf.
access_provider в значение simple. После этого необходимо добавить список имен пользователей, разделенных запятыми, либо в simple_allow_users, либо в simple_deny_users.
example.com является одним из доменов, описанных в секции [sssd], так что здесь приведены только параметры, связанные с простым провайдером доступа.
[domain/example.com] access_provider = simple simple_allow_users = user1, user2
simple в качестве провайдера доступа.
simple_allow_users, то только пользователи из этого списка получат доступ. Этот список перекрывает список simple_deny_users (который в данном случае может быть излишним).
simple_allow_users пуст, доступ получат те пользователи, которые не указаны в списке simple_deny_users.
simple_allow_users и simple_deny_users является конфигурационной ошибкой. Если такое произойдет, SSSD при старте выдаст в файл журнала /var/log/sssd/sssd_default.log ошибку. Будущие версии SSSD при этом выдадут ошибку и завершат работу.
access_provider=ldap) и связанный фильтр (ldap_access_filter) для определения того, какие пользователи имеют доступ к указанному узлу. Заметьте, что оба этих параметра взаимосвязаны. Если вы включили использование LDAP в качестве провайдера доступа, то вы должны определить и ldap_access_filter, иначе всем пользователям доступ будет закрыт. Если вы не используете LDAP в качестве провайдера доступа, ldap_access_filter не окажет никакого эффекта.
example.com является одним из доменов, описанных в секции [sssd], так что здесь приведены только параметры, связанные с провайдером доступа на основе LDAP.
[domain/example.com] access_provider = ldap ldap_access_filter = memberOf=cn=allowedusers,ou=Groups,dc=example,dc=com
[domain/<NAME>] файла /etc/sssd/sssd.conf. Этот список может содержать сколько угодно серверов.
ldap_uri следующие значения:
ldap_uri = ldap://ldap0.mydomain.org, ldap://ldap1.mydomain.org, ldap://ldap2.mydomain.org
ldap://ldap0.mydomain.org выступает в качестве основного сервера. Если этот сервер будет недоступен, механизм отказоустойчивости SSSD сперва попытается подключиться к ldap1.mydomain.org. Если и этот сервер будет недоступен, то будет произведена попытка подключиться к ldap2.mydomain.org.
ldap_uri, krb5_server, …) не определен, то бэкенд будет использовать по умолчанию Use service discovery. Для дополнительной информации прочтите Раздел 9.2.3.2.4.1, «Использование записей SRV для обеспечения отказоустойчивости».
ldap_uri, чтобы указать резервные сервера. Они должны быть указаны в качестве списка значений, разделенных запятыми, присвоенного одному параметру ldap_uri. Если вы введете несколько записей ldap_uri, SSSD будет использовать только последнюю.
ldap_uri.
приоритет и вес возможны дополнительные возможности в определении приоритета серверов в случае, когда основной сервер будет недоступен.
_сервис._протокол._домен TTL приоритет вес порт имя-узла
сервис._протокол._домен (например, _ldap._tcp._redhat.com). После этого клиент сортирует этот список согласно приоритетам и весам, после чего подключается к первому серверу из списка.
[sssd] перечислены все службы, которые должны быть запущены при запуске sssd, выполненном директивой services.
NSS — служба-провайдер NSS из модуля sssd_nss, отвечающая на NSS-запросы.
PAM — служба-провайдер PAM, управляющая взаимодействием PAM с помощью модуля sssd_pam.
monitor — специальная служба, отслеживающая все остальные службы SSSD, запуская или перезапуская их при необходимости. Ее параметры указаны в секции [sssd] файла /etc/sssd/sssd.conf.
debug_level (целое число)
[service/<NAME>] конфигурационного файла SSSD).
reconnection_retries (целое число)
DNS не смог вернуть IPv4-адрес узла, SSSD попытается получить IPv6-адрес перед тем, как вернуть результат неудачи. Заметьте, что это делается только для обеспечения правильности асинхронного получения адресов; в данный момент в коде LDAP содержится ошибка, не позволяющая SSSD подключаться к серверу LDAP через IPv6. Эта проблема будет решена отдельно.
Name Service Switch (NSS). Для получения полной информации по каждому из параметром обратитесь к man-странице sssd.conf(5).
enum_cache_timeout (целое число)
entry_cache_nowait_percentage (целое число)
0 отключает эту возможность).
entry_cache_timeout.
0-99 и отражают процентное отношение от entry_cache_timeout для каждого из доменов.
entry_negative_timeout (целое число)
filter_users, filter_groups (строка)
root.
filter_users_in_groups (булев)
TRUE, пользователи, указанные в списке filter_users не будут отображаться членами групп при получении информации о группах. Если этот параметр выставлен в FALSE, будут возвращаться все пользователей, являющихся членами запрошенных групп. Если параметр не определен, по умолчанию используется значение TRUE.
Pluggable Authentication Module (PAM)
offline_credentials_expiration (целое число)
0 (без ограничений).
offline_failed_login_attempts (целое число)
0 (без ограничений).
offline_failed_login_delay (целое число)
offline_failed_login_attempts.
0, пользователь при достижении offline_failed_login_attempts не сможет больше войти в автономном режиме. Только успешный вход в сетевом режиме восстановит возможность автономной аутентификации. Если не указано иначе, по умолчанию используется значение 5.
[sssd]. Здесь показана только аутентификация через Kerberos, провайдер идентификации не указан.
[domain/FOO] auth_provider = krb5 krb5_server = 192.168.1.1 krb5_realm = EXAMPLE.COM
[domain/<NAME>] в файле /etc/sssd/sssd.conf, после чего указать их в списке доменов domains, расположенном в секции [sssd], в том порядке, который будет использоваться при запросах.
min_id,max_id (целое число)
min_id установлено в 1; значение по умолчанию для max_id установлено 0 (неограниченно).
min_id не определен, то для бэкендов по умолчанию используется 1. Данное значение было выбрано для обеспечения совместимости с существующими и облегчения процессов миграции. Администраторы LDAP должны осознавать, использование подобного диапазона может привести к конфликтам с пользователями из локального файла /etc/passwd. Чтобы избежать подобных конфликтов, min_id следует присваивать значение 1000 или по возможности выше.
min_id определяет минимально допустимые значения и для UID, и для GID. Учетные записи с UID или GID, меньшими значения min_id, будут отфильтрованы и не будут доступны клиенту.
enumerate (булев)
FALSE. Чтобы включить перечисление пользователей и групп домена, установите значение в TRUE.
timeout (целое число)
10 секундам. Увеличение тайм-аута может стать полезным для медленных бэкендов, например, для далеко расположенных серверов LDAP.
timeout = 0, SSSD будет использовать значение по умолчанию. Невозможно принудительно устанавливать значение тайм-аута равным нулю, так как это может привести к вынужденному зацикливанию службы sssd.
cache_credentials (булев)
FALSE. Чтобы включить автономную аутентификацию для нелокальных доменов, следует присвоить этому параметру значение TRUE.
id_provider (строка)
NSS (например, nss_nis).
id_provider равным proxy, проверьте, что также указали proxy_lib_name. Обратитесь к Раздел 9.2.7, «Настройка прокси домена» для получения информации по этому атрибуту.
SSSD.
LDAP-провайдер.
entry_cache_timeout (целое число)
use_fully_qualified_names (булев)
TRUE, то все запросы к данному домену должны использовать полные доменные имена. Также это будет означать, что в выводе запросов тоже будет использоваться полные доменные имена.
ipauser01, и при этом атрибуту use_fully_qualified_names присвоено значение TRUE:
# getent passwd ipauser01[нет выходных данных]# getent passwd ipauser01@IPAipauser01@IPA:x:937315651:937315651:ipauser01:/home/ipauser01:/bin/sh
use_fully_qualified_names присвоено значение FALSE:
# getent passwd ipauser01ipauser01:x:937315651:937315651:ipauser01:/home/ipauser01:/bin/sh# getent passwd ipauser01@IPAipauser01:x:937315651:937315651:ipauser01:/home/ipauser01:/bin/sh
use_fully_qualified_names установить в значение FALSE, то вы все равно сможете использовать полные имена в своих запросах, но при этом будет отображаться упрощенная версия.
name@domain, но не name@realm. Тем не менее, для области и домена вы можете использовать одно и то же название.
auth_provider (строка)
id_provider (если он установлен и способен принимать запросы аутентификации).
proxy_pam_target (строка)
auth_provider установлен в значение proxy, и указывает на тот объект PAM, на который будет транслироваться аутентификация.
/etc/pam.d/.
pam_sss.so.
proxy_lib_name (строка)
auth_provider установлен в значение proxy, и указывает, какая из существующих NSS-библиотек будет использоваться для трансляции запросов идентификации.
libnss_nis.so, этому параметру следует присвоить значение nis.
id_provider значения ldap (id_provider = ldap). Для такого домена необходим работающий LDAP-сервер, через который будет проходить аутентификация. Это может быть LDAP-сервер на основе открытого кода (например, OpenLDAP) или Microsoft Active Directory. В данный момент SSSD поддерживает Active Directory 2003 (вместе с надстройкой Services for UNIX) и Active Directory 2008 (вместе с подсистемой для приложений на базе UNIX). В любом случае, конфигурация клиента сохраняется в файле /etc/sssd/sssd.conf.
TLS/SSL, либо LDAPS. Если сервер LDAP используется только как провайдер идентификации, зашифрованный канал не требуется.
/etc/sssd/sssd.conf следующие строки:
# Домен с чистым LDAP [domain/LDAP] enumerate = false cache_credentials = TRUE id_provider = ldap auth_provider = ldap ldap_schema = rfc2307 chpass_provider = ldap ldap_uri = ldap://ldap.mydomain.org ldap_search_base = dc=mydomain,dc=org ldap_tls_reqcert = demand ldap_tls_cacert = /etc/pki/tls/certs/ca-bundle.crt
ldap_uri вместо имени сервера, например для сокращения временных задержек на запросы DNS при использовании GSSAPI, то настройка TSL/SSL может закончиться неудачей. Причиной будет являться то, что сертификаты TSL/SSL содержат в себе только имя сервера. Тем не менее, для указания добавочного IP-адреса сервера можно использовать особое поле под названием Альтернативное имя субъекта (subjectAltName).
key.pem) в запрос на сертификат:
openssl x509 -x509toreq -in old_cert.pem -out req.pem -signkey key.pem
/etc/pki/tls/certs/slapd.pem), запустив следующую команду:
openssl x509 -x509toreq -in old_cert.pem -out req.pem -signkey old_cert.pem
/etc/pki/tls/openssl.cnf следующую строку в секции [ v3_ca ]:
subjectAltName = IP:10.0.0.10
openssl x509 -req -in req.pem -out new_cert.pem -extfile ./openssl.cnf -extensions v3_ca -signkey old_cert.pem
openssl x509 — команда для создания нового сертификата.
-req указывает на то, что на входе будет запрос на сертификат.
-in и -out указывают входной и выходной файлы.
-extfile указывает на то, какой файл расширений сертификата следует использовать (в данном случае — расширение subjectAltName).
-extensions указывает на секцию в файле openssl.cnf, из которой будет добавляться расширение (в данном случае — из секции [ v3_ca ]).
-signkey предписывает подписать входной файл указанным закрытым ключом.
man x509.
old_cert.pem в файл new_cert.pem, чтобы держать всю необходимую информацию в одном месте.
DNS только при создании сертификата.
ldap_schema значение либо rfc2307, либо rfc2307bis. В этих схемах описывается организация групп в LDAP. Согласно RFC 2307 объекты-группы используют многозначные атрибуты memberuid, в которые перечисляются имена пользователей, принадлежащих к группе. А в RFC 2307bis вместо memberuid в объектах-группах используется атрибут member. Вместо просто имени пользователя этот атрибут содержит полное уникальное имя (Distinguished Name, DN) другого объекта в базе LDAP. Это значит, что группы могут содержать в себе другие группы. Таким образом реализуются вложенные группы.
/etc/sssd/sssd.conf, то это может повлиять на то, как будут отображаться пользователи и группы. Также это может привести к тому, что некоторые группы и сетевые ресурсы не будут доступны, даже если у вас есть полные права ими пользоваться.
id:
[f12server@ipaserver ~]$ id uid=500(f12server) gid=500(f12server) groups=500(f12server),510(f12tester)
ldap_search_timeout (целое число) — указывает тайм-аут (в секундах) для поисковых запросов LDAP, по истечению которого они отменяются и возвращаются кэшированные значения (с одновременным переходом в автономный режим). Если не указано иначе:
enumerate = False
enumerate = True. В данном случае параметр принудительно будет выставлен в минимальное значение 30.
ldap_network_timeout (целое число) — указывает тайм-аут (в секундах), по истечению которого вызовы poll(2)/select(2), следующие за connect(2) будут отзываться в случае неактивности.
ldap_opt_timeout (целое число) - указывает тайм-аут (в секундах), по истечению которого синхронные вызовы LDAP API будут отменены в случае отсутствия ответа. Данный параметр также контролирует тайм-аут при подключении к KDC, если при этом используется подключение SASL.
DNS позволяет бэкенду LDAP автоматически обнаруживать через специальные DNS-запросы подходящие DNS-серверы. Для более детальной информации об обнаружении служб DNS обратитесь к разделу Раздел 9.2.3.2.4.1, «Использование записей SRV для обеспечения отказоустойчивости».
/etc/sssd/sssd.conf, содержащий пример конфигурации для Active Directory 2003:
# Пример домена LDAP, где в роли LDAP-сервера выступает сервер Active Directory 2003. [domain/AD] description = LDAP domain with AD server enumerate = false min_id = 1000 ; id_provider = ldap auth_provider = ldap ldap_uri = ldap://your.ad.server.com ldap_schema = rfc2307bis ldap_search_base = dc=example,dc=com ldap_default_bind_dn = cn=Administrator,cn=Users,dc=example,dc=com ldap_default_authtok_type = password ldap_default_authtok = YOUR_PASSWORD ldap_user_object_class = person ldap_user_name = msSFU30Name ldap_user_uid_number = msSFU30UidNumber ldap_user_gid_number = msSFU30GidNumber ldap_user_home_directory = msSFU30HomeDirectory ldap_user_shell = msSFU30LoginShell ldap_user_principal = userPrincipalName ldap_group_object_class = group ldap_group_name = msSFU30Name ldap_group_gid_number = msSFU30GidNumber
/etc/openldap/cacerts) и что для создания подходящих символических ссылок используется функция c_rehash.
/etc/sssd/sssd.conf, поддерживающая Active Directory 2003 R2 или Active Directory 2008 в качестве бэкенда, схожа конфигурацией для AD 2003. Все необходимые изменения отображены следующем примере.
# Пример домена LDAP, где в роли LDAP-сервера выступает сервер Active Directory 2003 R2 или ctive Directory 2008. [domain/AD] description = LDAP domain with AD server ; debug_level = 9 enumerate = false id_provider = ldap auth_provider = ldap chpass_provider = ldap ldap_uri = ldap://your.ad.server.com ldap_tls_cacertdir = /etc/openldap/cacerts ldap_tls_cacert = /etc/openldap/cacerts/test.cer ldap_search_base = dc=example,dc=com ldap_default_bind_dn = cn=Administrator,cn=Users,dc=example,dc=com ldap_default_authtok_type = password ldap_default_authtok = YOUR_PASSWORD ldap_pwd_policy = none ldap_user_object_class = user ldap_group_object_class = group
/etc/openldap/cacerts) и что для создания подходящих символических ссылок используется функция c_rehash.
/etc/sssd/sssd.conf.
id_provider = ldap). Некоторая информация, необходимая для аутентификации через бэкенд Kerberos 5, должно предоставляться провайдером идентификации, например, Kerberos Principal Name (UPN). В конфигурации провайдера идентификации должна содержаться запись, указывающая на этот UPN. Обратитесь к man-странице используемого провайдера идентификации для получения необходимой информации по настройке UPN.
username@krb5_realm.
krb5_kpasswd, чтобы указать, где находится сервис, который может изменять пароли, или если он находится на нестандартном порту. Если параметр krb5_kpasswd не определен, SSSD попытается использовать Kerberos KDC для изменения пароля. Обратитесь к man-странице sssd-krb5(5) для получения информации о всех параметрах конфигурации Kerberos.
/etc/sssd/sssd.conf следующие строки:
# Домен идентификации предоставляется LDAP, а аутентификации - Kerberos [domain/KRBDOMAIN] enumerate = false id_provider = ldap chpass_provider = krb5 ldap_uri = ldap://ldap.mydomain.org ldap_search_base = dc=mydomain,dc=org tls_reqcert = demand ldap_tls_cacert = /etc/pki/tls/certs/ca-bundle.crt auth_provider = krb5 krb5_server = 192.168.1.1 krb5_realm = EXAMPLE.COM krb5_changepw_principal = kadmin/changepw krb5_ccachedir = /tmp krb5_ccname_template = FILE:%d/krb5cc_%U_XXXXXX krb5_auth_timeout = 15
DNS позволяет бэкенду аутентификации Kerberos 5 автоматически обнаруживать через специальные DNS-запросы подходящие DNS-серверы. Для более детальной информации об обнаружении служб DNS обратитесь к разделу Раздел 9.2.3.2.4.1, «Использование записей SRV для обеспечения отказоустойчивости».
-randkey для команды kadmin addprinc, чтобы создать принципал и назначить ему случайный ключ:
kadmin: addprinc -randkey ldap/server.example.com
ktadd запишите принципал сервиса в файл:
kadmin: ktadd -k /root/ldap.keytab ldap/server.example.com
-randkey для команды kadmin addprinc, чтобы создать принципал и назначить ему случайный ключ:
kadmin: addprinc -randkey host/client.example.com
ktadd запишите принципал узла в файл:
kadmin: ktadd -k /root/client.keytab host/client.example.com
/root/ldap.keytab с KDC в каталог /etc/openldap/ и переименуйте его в ldap.keytab.
/etc/openldap/ldap.keytab в режим «чтение-запись» для пользователя ldap и «чтение» для группы ldap, полностью закрыв доступ для остальных пользователей.
/root/ldap.keytab с KDC в каталог /etc/dirsrv/ и переименуйте его в ldap.keytab.
KRB5_KTNAME в файле /etc/sysconfig/dirsrv (или его экземпляре) и укажите расположение keytab в переменной KRB5_KTNAME:
# Чтобы включить SASL/GSSAPI, серверу каталогов # необходимо знать, где находится keytab-файл - # раскомментируйте следующую строку и укажите # правильное расположение файла KRB5_KTNAME=/etc/dirsrv/ldap.keytab; export KRB5_KTNAME
/root/client.keytab из KDC в каталог /etc/ и переименуйте его в krb5.keytab. Если файл /etc/krb5.keytab уже существует, объедините оба файла с помощью утилиты ktutil. Для дополнительной информации об утилите ktutil обратитесь к man ktutil.
/etc/sssd/sssd.conf следующие строки:
ldap_sasl_mech = gssapi ldap_sasl_authid = host/client.example.com@EXAMPLE.COM ldap_krb5_keytab = /etc/krb5.keytab (default) ldap_krb5_init_creds = true (default) ldap_krb5_ticket_lifetime = 86400 (default) krb5_realm = EXAMPLE.COM
/etc/sssd/sssd.conf, включив следующие параметры:
[domain/PROXY_KRB5] auth_provider = krb5 krb5_server = 192.168.1.1 krb5_realm = EXAMPLE.COM id_provider = proxy proxy_lib_name = nis enumerate = true cache_credentials = true
/etc/sssd/sssd.conf, включив следующие параметры:
[domain/LDAP_PROXY] id_provider = ldap ldap_uri = ldap://example.com ldap_search_base = dc=example,dc=com auth_provider = proxy proxy_pam_target = sssdpamproxy enumerate = true cache_credentials = true
/etc/pam.d/sssdpamproxy, который предоставляет необходимый модуль интерфейса. Файл pam_ldap.so может быть заменен на любой модуль PAM по вашему выбору.
/etc/pam.d/sssdpamproxy (если его еще нет) и внесите в него следующие строки:
auth required pam_ldap.so account required pam_ldap.so password required pam_ldap.so session required pam_ldap.so
/etc/sssd/sssd.conf, включив следующие параметры:
[domain/PROXY_PROXY] auth_provider = proxy id_provider = proxy proxy_lib_name = ldap proxy_pam_target = sssdproxyldap enumerate = true cache_credentials = true
/etc/pam.d/sssdproxyldap, который предоставляет необходимый модуль интерфейса.
man sssd.conf.
/etc/pam.d/sssdproxyldap (если его еще нет) и внесите в него следующие строки:
auth required pam_ldap.so account required pam_ldap.so password required pam_ldap.so session required pam_ldap.so
/etc/nslcd.conf (конфигурационный файл по умолчанию для службы имен LDAP), включив следующие параметры:
uid nslcd gid ldap uri ldaps://ldap.mydomain.org:636 base dc=mydomain,dc=org ssl on tls_cacertdir /etc/openldap/cacerts
man nslcd.conf.
/var/log/sssd/.
/etc/sssd/sssd.conf), а также файлы sssd_pam.log и sssd_nss.log. Такой уровень точности поможет вам быстро изолировать и решить любую проблему или ошибку, с которой вы можете столкнуться при работе с SSSD.
/var/log/secure, в котором регистрируются ошибки аутентификации и причины ошибок. Например, если напротив каждой ошибки указано Reason 4: System Error, то вам следует повысить отладочный уровень журналирования.
debug_level в файле /etc/sssd/sssd.conf, в разделе того домена, который вызывает подозрения, после чего перезапустить SSSD. Обратитесь к man-странице sssd.conf(5) для дальнейшей информации по указанию debug_level для определенного домена.
FALSE в файле /etc/sssd/sssd.conf:
--debug-timestamps=FALSE
# sssd -d4
[sssd] [ldb] (3): server_sort:Unable to register control with rootdse! [sssd] [confdb_get_domains] (0): No domains configured, fatal error! [sssd] [get_monitor_config] (0): No domains configured.
/etc/sssd/sssd.conf и убедитесь, что настроен по крайней мере один домен, после чего запустите SSSD.
# sssd -d4
[sssd] [ldb] (3): server_sort:Unable to register control with rootdse! [sssd] [get_monitor_config] (0): No services configured!
/etc/sssd/sssd.conf и убедитесь, что в нем есть по крайней мере один доступный сервис-провайдер, после чего запустите SSSD.
services файла /etc/sssd/sssd.conf. Если сервисы перечислены в виде нескольких записей, распознана будет только последняя.
NSS, симптомы и методы их решения.
NSS не может вернуть пользовательскую информацию
# systemctl is-active sssd.service
sssd (pid 21762) is running...
[nss] в файле /etc/sssd/sssd.conf: не ошиблись в определении атрибутов filter_users или filter_groups. Сверьтесь с разделом Параметры конфигурации NSS из man-страницы sssd.conf(5) для получения информации по конфигурации данных параметров.
nss в список сервисов sssd, которые должны запускаться.
/etc/nsswitch.conf. Обратитесь к разделу Раздел 9.2.3.2.1, «Настройка NSS» для получения информации по правильной настройке этого файла.
PAM, симптомы и методы их решения.
[root@clientF11 tmp]# passwd user1000 Changing password for user user1000. New password: Retype new password: New Password: Reenter new Password: passwd: all authentication tokens updated successfully.
/etc/pam.d/system-auth параметр use_authtok указан правильно.
nscd и, скорее всего, будет предупреждать об этом в файлах журналов SSSD. Даже если SSSD не конфликтует напрямую с nscd, одновременное использование обоих служб может привести к непредсказуемым результатам (особенно в случае долгоживущих записей из кэша).
resolv.conf. Обычно этот файл прочитывается только один раз, так что любые изменения в этом файле могут быть проигнорированы.
nscd это может привести ошибкам в некоторых системных службах, в частности, нарушить систему блокировок NFS до тех пор, пока служба не будет перезапущена.
hosts и services в файле /etc/nscd.conf, а кэширование passwd и group отдать SSSD. С nscd, который отвечает на запросы hosts и services, эти данные будут закэшированы и возвращаться службой nscd во время загрузки.
/etc/sssd/sssd.conf значение параметра use_fully_qualified_domains в значение TRUE.
sssd.conf(5)
sssd-ipa(5)
sssd-krb5(5)
sssd-ldap(5)
sssd(8)
sssd_krb5_locator_plugin(8)
pam_sss(8)
[sssd] config_file_version = 2 services = nss, pam domains = mybox.example.com, ldap.example.com, ipa.example.com, nis.example.com # sbus_timeout = 300 [nss] nss_filter_groups = root nss_filter_users = root nss_entry_cache_timeout = 30 nss_enum_cache_timeout = 30 [domain/mybox.example.com] domain_type = local enumerate = true min_id = 1000 # max_id = 2000 local_default_shell = /bin/bash local_default_homedir = /home # Возможные переопределения # id_provider = local # auth_provider = local # authz_provider = local # passwd_provider = local [domain/ldap.example.com] domain_type = ldap server = ldap.example.com, ldap3.example.com, 10.0.0.2 # ldap_uri = ldaps://ldap.example.com:9093 # ldap_use_tls = ssl ldap_search_base = dc=ldap,dc=example,dc=com enumerate = false # Возможные переопределения # id_provider = ldap # id_server = ldap2.example.com # auth_provider = krb5 # auth_server = krb5.example.com # krb5_realm = KRB5.EXAMPLE.COM [domain/ipa.example.com] domain_type = ipa server = ipa.example.com, ipa2.example.com enumerate = false # Возможные переопределения # id_provider = ldap # id_server = ldap2.example.com # auth_provider = krb5 # auth_server = krb5.example.com # krb5_realm = KRB5.EXAMPLE.COM [domain/nis.example.com] id_provider = proxy proxy_lib = nis auth_provider = proxy proxy_auth_target = nis_pam_proxy
SSH (Secure Shell) is a protocol which facilitates secure communications between two systems using a client/server architecture and allows users to log into server host systems remotely. Unlike other remote communication protocols, such as FTP or Telnet, SSH encrypts the login session, rendering the connection difficult for intruders to collect unencrypted passwords.
telnet or rsh. A related program called scp replaces older programs designed to copy files between hosts, such as rcp. Because these older applications do not encrypt passwords transmitted between the client and the server, avoid them whenever possible. Using secure methods to log into remote systems decreases the risks for both the client system and the remote host.
root by typing:
su -ssh, scp, and sftp), and those for the server (the sshd daemon).
/etc/ssh/ directory. See Таблица 10.1, «System-wide configuration files» for a description of its content.
| Configuration File | Description |
|---|---|
/etc/ssh/moduli
| Contains Diffie-Hellman groups used for the Diffie-Hellman key exchange which is critical for constructing a secure transport layer. When keys are exchanged at the beginning of an SSH session, a shared, secret value is created which cannot be determined by either party alone. This value is then used to provide host authentication. |
/etc/ssh/ssh_config
|
The default SSH client configuration file. Note that it is overridden by ~/.ssh/config if it exists.
|
/etc/ssh/sshd_config
|
The configuration file for the sshd daemon.
|
/etc/ssh/ssh_host_dsa_key
|
The DSA private key used by the sshd daemon.
|
/etc/ssh/ssh_host_dsa_key.pub
|
The DSA public key used by the sshd daemon.
|
/etc/ssh/ssh_host_key
|
The RSA private key used by the sshd daemon for version 1 of the SSH protocol.
|
/etc/ssh/ssh_host_key.pub
|
The RSA public key used by the sshd daemon for version 1 of the SSH protocol.
|
/etc/ssh/ssh_host_rsa_key
|
The RSA private key used by the sshd daemon for version 2 of the SSH protocol.
|
/etc/ssh/ssh_host_rsa_key.pub
|
The RSA public key used by the sshd for version 2 of the SSH protocol.
|
~/.ssh/ directory. See Таблица 10.2, «User-specific configuration files» for a description of its content.
| Configuration File | Description |
|---|---|
~/.ssh/authorized_keys
| Holds a list of authorized public keys for servers. When the client connects to a server, the server authenticates the client by checking its signed public key stored within this file. |
~/.ssh/id_dsa
| Contains the DSA private key of the user. |
~/.ssh/id_dsa.pub
| The DSA public key of the user. |
~/.ssh/id_rsa
|
The RSA private key used by ssh for version 2 of the SSH protocol.
|
~/.ssh/id_rsa.pub
|
The RSA public key used by ssh for version 2 of the SSH protocol
|
~/.ssh/identity
|
The RSA private key used by ssh for version 1 of the SSH protocol.
|
~/.ssh/identity.pub
|
The RSA public key used by ssh for version 1 of the SSH protocol.
|
~/.ssh/known_hosts
| Contains DSA host keys of SSH servers accessed by the user. This file is very important for ensuring that the SSH client is connecting the correct SSH server. |
ssh_config and sshd_config man pages for information concerning the various directives available in the SSH configuration files.
sshd daemon, type the following at a shell prompt:
systemctl start sshd.servicesshd daemon, use the following command:
systemctl stop sshd.servicesystemctl enable sshd.service@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY! Someone could be eavesdropping on you right now (man-in-the-middle attack)! It is also possible that the RSA host key has just been changed.
/etc/ssh/ directory (see Таблица 10.1, «System-wide configuration files» for a complete list), and restore them whenever you reinstall the system.
telnet, rsh, rlogin, and vsftpd.
systemctl stop telnet.servicesystemctl stop rsh.servicesystemctl stop rlogin.servicesystemctl stop vsftpd.service
systemctl disable telnet.servicesystemctl disable rsh.servicesystemctl disable rlogin.servicesystemctl disable vsftpd.service
/etc/ssh/sshd_config configuration file in a text editor, and change the PasswordAuthentication option as follows:
PasswordAuthentication no
ssh, scp, or sftp to connect to the server from a client machine, generate an authorization key pair by following the steps below. Note that keys must be generated for each user separately.
root, only root will be able to use the keys.
~/.ssh/ directory. After reinstalling, copy it back to your home directory. This process can be done for all users on your system, including root.
~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/john/.ssh/id_rsa):~/.ssh/id_rsa) for the newly created key.
Your identification has been saved in /home/john/.ssh/id_rsa. Your public key has been saved in /home/john/.ssh/id_rsa.pub. The key fingerprint is: e7:97:c7:e2:0e:f9:0e:fc:c4:d7:cb:e5:31:11:92:14 john@penguin.example.com The key's randomart image is: +--[ RSA 2048]----+ | E. | | . . | | o . | | . .| | S . . | | + o o ..| | * * +oo| | O +..=| | o* o.| +-----------------+
~/.ssh/ directory:
~]$ chmod 755 ~/.ssh~/.ssh/id_rsa.pub into the ~/.ssh/authorized_keys on the machine to which you want to connect, appending it to its end if the file already exists.
~/.ssh/authorized_keys file using the following command:
~]$ chmod 644 ~/.ssh/authorized_keys~]$ ssh-keygen -t dsa
Generating public/private dsa key pair.
Enter file in which to save the key (/home/john/.ssh/id_dsa):~/.ssh/id_dsa) for the newly created key.
Your identification has been saved in /home/john/.ssh/id_dsa. Your public key has been saved in /home/john/.ssh/id_dsa.pub. The key fingerprint is: 81:a1:91:a8:9f:e8:c5:66:0d:54:f5:90:cc:bc:cc:27 john@penguin.example.com The key's randomart image is: +--[ DSA 1024]----+ | .oo*o. | | ...o Bo | | .. . + o. | |. . E o | | o..o S | |. o= . | |. + | | . | | | +-----------------+
~/.ssh/ directory:
~]$ chmod 775 ~/.ssh~/.ssh/id_dsa.pub into the ~/.ssh/authorized_keys on the machine to which you want to connect, appending it to its end if the file already exists.
~/.ssh/authorized_keys file using the following command:
~]$ chmod 644 ~/.ssh/authorized_keys~]$ ssh-keygen -t rsa1
Generating public/private rsa1 key pair.
Enter file in which to save the key (/home/john/.ssh/identity):~/.ssh/identity) for the newly created key.
Your identification has been saved in /home/john/.ssh/identity. Your public key has been saved in /home/john/.ssh/identity.pub. The key fingerprint is: cb:f6:d5:cb:6e:5f:2b:28:ac:17:0c:e4:62:e4:6f:59 john@penguin.example.com The key's randomart image is: +--[RSA1 2048]----+ | | | . . | | o o | | + o E | | . o S | | = + . | | . = . o . .| | . = o o..o| | .o o o=o.| +-----------------+
~/.ssh/ directory:
~]$ chmod 755 ~/.ssh~/.ssh/identity.pub into the ~/.ssh/authorized_keys on the machine to which you want to connect, appending it to its end if the file already exists.
~/.ssh/authorized_keys file using the following command:
~]$ chmod 644 ~/.ssh/authorized_keysssh-agent authentication agent. To save your passphrase for a certain shell prompt, use the following command:
~]$ ssh-add
Enter passphrase for /home/john/.ssh/id_rsa:ssh allows you to log in to a remote machine and execute commands there. It is a secure replacement for the rlogin, rsh, and telnet programs.
telnet, to log in to a remote machine named penguin.example.com, type the following command at a shell prompt:
~]$ ssh penguin.example.comssh username@hostname form. For example, to log in as john, type:
~]$ ssh john@penguin.example.comThe authenticity of host 'penguin.example.com' can't be established. RSA key fingerprint is 94:68:3a:3a:bc:f3:9a:9b:01:5d:b3:07:38:e2:11:0c. Are you sure you want to continue connecting (yes/no)?
yes to confirm. You will see a notice that the server has been added to the list of known hosts, and a prompt asking for your password:
Warning: Permanently added 'penguin.example.com' (RSA) to the list of known hosts. john@penguin.example.com's password:
~/.ssh/known_hosts file. To do so, open the file in a text editor, and remove a line containing the remote machine name at the beginning. Before doing this, however, contact the system administrator of the SSH server to verify the server is not compromised.
ssh program can be used to execute a command on the remote machine without logging in to a shell prompt. The syntax for that is ssh [username@]hostname command. For example, if you want to execute the whoami command on penguin.example.com, type:
~]$ ssh john@penguin.example.com whoami
john@penguin.example.com's password:
johnscp Utilityscp can be used to transfer files between machines over a secure, encrypted connection. In its design, it is very similar to rcp.
scp localfile username@hostname:remotefiletaglist.vim to a remote machine named penguin.example.com, type the following at a shell prompt:
~]$ scp taglist.vim john@penguin.example.com:.vim/plugin/taglist.vim
john@penguin.example.com's password:
taglist.vim 100% 144KB 144.5KB/s 00:00.vim/plugin/ to the same directory on the remote machine penguin.example.com, type the following command:
~]$ scp .vim/plugin/* john@penguin.example.com:.vim/plugin/
john@penguin.example.com's password:
closetag.vim 100% 13KB 12.6KB/s 00:00
snippetsEmu.vim 100% 33KB 33.1KB/s 00:00
taglist.vim 100% 144KB 144.5KB/s 00:00scp username@hostname:remotefile localfile.vimrc configuration file from the remote machine, type:
~]$ scp john@penguin.example.com:.vimrc .vimrc
john@penguin.example.com's password:
.vimrc 100% 2233 2.2KB/s 00:00sftp Utilitysftp utility can be used to open a secure, interactive FTP session. In its design, it is similar to ftp except that it uses a secure, encrypted connection.
sftp username@hostnamepenguin.example.com with john as a username, type:
~]$ sftp john@penguin.example.com
john@penguin.example.com's password:
Connected to penguin.example.com.
sftp>sftp utility accepts a set of commands similar to those used by ftp (see Таблица 10.3, «A selection of available sftp commands»).
| Command | Description |
|---|---|
ls [directory]
|
List the content of a remote directory. If none is supplied, a current working directory is used by default.
|
cd directory
|
Change the remote working directory to directory.
|
mkdir directory
|
Create a remote directory.
|
rmdir path
|
Remove a remote directory.
|
put localfile [remotefile]
|
Transfer localfile to a remote machine.
|
get remotefile [localfile]
|
Transfer remotefile from a remote machine.
|
sftp man page.
ssh -Y username@hostnamepenguin.example.com with john as a username, type:
~]$ ssh -Y john@penguin.example.com
john@penguin.example.com's password:~]$ system-config-printer &TCP/IP protocols via port forwarding. When using this technique, the SSH server becomes an encrypted conduit to the SSH client.
localhost, use a command in the following form:
ssh -L local-port:remote-hostname:remote-port username@hostnamemail.example.com using POP3 through an encrypted connection, use the following command:
~]$ ssh -L 1100:mail.example.com:110 mail.example.com1100 on the localhost to check for new email. Any requests sent to port 1100 on the client system will be directed securely to the mail.example.com server.
mail.example.com is not running an SSH server, but another machine on the same network is, SSH can still be used to secure part of the connection. However, a slightly different command is necessary:
~]$ ssh -L 1100:mail.example.com:110 other.example.com1100 on the client machine are forwarded through the SSH connection on port 22 to the SSH server, other.example.com. Then, other.example.com connects to port 110 on mail.example.com to check for new email. Note that when using this technique, only the connection between the client system and other.example.com SSH server is secure.
No parameter for the AllowTcpForwarding line in /etc/ssh/sshd_config and restarting the sshd service.
man sshman scpman sftpman sshdman ssh-keygenman ssh_configman sshd_configСодержание
smb.conf Filedhcp package contains an ISC DHCP server. First, install the package as root:
yum install dhcpdhcp package creates a file, /etc/dhcp/dhcpd.conf, which is merely an empty configuration file:
# # DHCP Server Configuration file. # see /usr/share/doc/dhcp*/dhcpd.conf.sample # see dhcpd.conf(5) man page #
/usr/share/doc/dhcp-version/dhcpd.conf.sample. You should use this file to help you configure /etc/dhcp/dhcpd.conf, which is explained in detail below.
/var/lib/dhcpd/dhcpd.leases to store the client lease database. Refer to Раздел 11.2.2, «Lease Database» for more information.
root:
systemctl restart dhcpd.serviceomshell command provides an interactive way to connect to, query, and change the configuration of a DHCP server. By using omshell, all changes can be made while the server is running. For more information on omshell, refer to the omshell man page.
routers, subnet-mask, domain-search, domain-name-servers, and time-offset options are used for any host statements declared below it.
subnet can be declared, a subnet declaration must be included for every subnet in the network. If it is not, the DHCP server fails to start.
range declared. Clients are assigned an IP address within the range.
subnet 192.168.1.0 netmask 255.255.255.0 {
option routers 192.168.1.254;
option subnet-mask 255.255.255.0;
option domain-search "example.com";
option domain-name-servers 192.168.1.1;
option time-offset -18000; # Eastern Standard Time
range 192.168.1.10 192.168.1.100;
}range 192.168.1.10 and 192.168.1.100 to client systems.
default-lease-time 600;
max-lease-time 7200;
option subnet-mask 255.255.255.0;
option broadcast-address 192.168.1.255;
option routers 192.168.1.254;
option domain-name-servers 192.168.1.1, 192.168.1.2;
option domain-search "example.com";
subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.10 192.168.1.100;
}hardware ethernet parameter within a host declaration. As demonstrated in Пример 11.3, «Static IP address using DHCP», the host apex declaration specifies that the network interface card with the MAC address 00:A0:78:8E:9E:AA always receives the IP address 192.168.1.4.
host-name can also be used to assign a host name to the client.
host apex {
option host-name "apex.example.com";
hardware ethernet 00:A0:78:8E:9E:AA;
fixed-address 192.168.1.4;
}shared-network declaration as shown in Пример 11.4, «Shared-network declaration». Parameters within the shared-network, but outside the enclosed subnet declarations, are considered to be global parameters. The name of the shared-network must be a descriptive title for the network, such as using the title 'test-lab' to describe all the subnets in a test lab environment.
group declaration is used to apply global parameters to a group of declarations. For example, shared networks, subnets, and hosts can be grouped.
group {
option routers 192.168.1.254;
option subnet-mask 255.255.255.0;
option domain-search "example.com";
option domain-name-servers 192.168.1.1;
option time-offset -18000; # Eastern Standard Time
host apex {
option host-name "apex.example.com";
hardware ethernet 00:A0:78:8E:9E:AA;
fixed-address 192.168.1.4;
}
host raleigh {
option host-name "raleigh.example.com";
hardware ethernet 00:A1:DD:74:C3:F2;
fixed-address 192.168.1.6;
}
}cp /usr/share/doc/dhcp-version-number/dhcpd.conf.sample /etc/dhcp/dhcpd.confversion-number is the DHCP version number.
dhcp-options man page.
/var/lib/dhcpd/dhcpd.leases stores the DHCP client lease database. Do not change this file. DHCP lease information for each recently assigned IP address is automatically stored in the lease database. The information includes the length of the lease, to whom the IP address has been assigned, the start and end dates for the lease, and the MAC address of the network interface card that was used to retrieve the lease.
dhcpd.leases file is renamed dhcpd.leases~ and the temporary lease database is written to dhcpd.leases.
dhcpd.leases file does not exist, but it is required to start the service. Do not create a new lease file. If you do, all old leases are lost which causes many problems. The correct solution is to rename the dhcpd.leases~ backup file to dhcpd.leases and then start the daemon.
dhcpd.leases file exists. Use the command touch /var/lib/dhcpd/dhcpd.leases to create the file if it does not exist.
named service automatically checks for a dhcpd.leases file.
systemctl start dhcpd.servicesystemctl stop dhcpd.servicesystemctl enable dhcpd.service/etc/sysconfig/dhcpd, add the name of the interface to the list of DHCPDARGS:
# Command line options here DHCPDARGS=eth0
/etc/sysconfig/dhcpd include:
-p portnum — Specifies the UDP port number on which dhcpd should listen. The default is port 67. The DHCP server transmits responses to the DHCP clients at a port number one greater than the UDP port specified. For example, if the default port 67 is used, the server listens on port 67 for requests and responses to the client on port 68. If a port is specified here and the DHCP relay agent is used, the same port on which the DHCP relay agent should listen must be specified. Refer to Раздел 11.2.4, «DHCP Relay Agent» for details.
-f — Runs the daemon as a foreground process. This is mostly used for debugging.
-d — Logs the DHCP server daemon to the standard error descriptor. This is mostly used for debugging. If this is not specified, the log is written to /var/log/messages.
-cf filename — Specifies the location of the configuration file. The default location is /etc/dhcp/dhcpd.conf.
-lf filename — Specifies the location of the lease database file. If a lease database file already exists, it is very important that the same file be used every time the DHCP server is started. It is strongly recommended that this option only be used for debugging purposes on non-production machines. The default location is /var/lib/dhcpd/dhcpd.leases.
-q — Do not print the entire copyright message when starting the daemon.
dhcrelay) allows for the relay of DHCP and BOOTP requests from a subnet with no DHCP server on it to one or more DHCP servers on other subnets.
/etc/sysconfig/dhcrelay with the INTERFACES directive.
systemctl start dhcrelay.service/etc/sysconfig/network file to enable networking and the configuration file for each network device in the /etc/sysconfig/network-scripts directory. In this directory, each device should have a configuration file named ifcfg-eth0, where eth0 is the network device name.
/etc/sysconfig/network-scripts/ifcfg-eth0 file should contain the following lines:
DEVICE=eth0 BOOTPROTO=dhcp ONBOOT=yes
DHCP_HOSTNAME — Only use this option if the DHCP server requires the client to specify a hostname before receiving an IP address. (The DHCP server daemon in Fedora does not support this feature.)
PEERDNS=answer , where answer yes — Modify /etc/resolv.conf with information from the server. If using DHCP, then yes is the default.
no — Do not modify /etc/resolv.conf.
dhclient and dhclient.conf man pages.
/etc/sysconfig/dhcpd and /etc/dhcp/dhcpd.conf files.
/etc/sysconfig/dhcpd file to specify which network interfaces the DHCP daemon listens on. The following /etc/sysconfig/dhcpd example specifies that the DHCP daemon listens on the eth0 and eth1 interfaces:
DHCPDARGS="eth0 eth1";
eth0, eth1, and eth2 -- and it is only desired that the DHCP daemon listens on eth0, then only specify eth0 in /etc/sysconfig/dhcpd:
DHCPDARGS="eth0";
/etc/dhcp/dhcpd.conf file, for a server that has two network interfaces, eth0 in a 10.0.0.0/24 network, and eth1 in a 172.16.0.0/24 network. Multiple subnet declarations allow different settings to be defined for multiple networks:
default-lease-time600; max-lease-time7200; subnet 10.0.0.0 netmask 255.255.255.0 { option subnet-mask 255.255.255.0; option routers 10.0.0.1; range 10.0.0.5 10.0.0.15; } subnet 172.16.0.0 netmask 255.255.255.0 { option subnet-mask 255.255.255.0; option routers 172.16.0.1; range 172.16.0.5 172.16.0.15; }
subnet 10.0.0.0 netmask 255.255.255.0; subnet declaration is required for every network your DHCP server is serving. Multiple subnets require multiple subnet declarations. If the DHCP server does not have a network interface in a range of a subnet declaration, the DHCP server does not serve that network.
subnet declaration, and no network interfaces are in the range of that subnet, the DHCP daemon fails to start, and an error such as the following is logged to /var/log/messages:
dhcpd: No subnet declaration for eth0 (0.0.0.0). dhcpd: ** Ignoring requests on eth0. If this is not what dhcpd: you want, please write a subnet declaration dhcpd: in your dhcpd.conf file for the network segment dhcpd: to which interface eth1 is attached. ** dhcpd: dhcpd: dhcpd: Not configured to listen on any interfaces!
option subnet-mask 255.255.255.0; option subnet-mask option defines a subnet mask, and overrides the netmask value in the subnet declaration. In simple cases, the subnet and netmask values are the same.
option routers 10.0.0.1; option routers option defines the default gateway for the subnet. This is required for systems to reach internal networks on a different subnet, as well as external networks.
range 10.0.0.5 10.0.0.15; range option specifies the pool of available IP addresses. Systems are assigned an address from the range of specified IP addresses.
dhcpd.conf(5) man page.
/etc/dhcp/dhcpd.conf, the DHCP daemon fails to start.
/etc/sysconfig/dhcpd and /etc/dhcp/dhcpd.conf files.
/etc/dhcp/dhcpd.conf example creates two subnets, and configures an IP address for the same system, depending on which network it connects to:
default-lease-time600; max-lease-time7200; subnet 10.0.0.0 netmask 255.255.255.0 { option subnet-mask 255.255.255.0; option routers 10.0.0.1; range 10.0.0.5 10.0.0.15; } subnet 172.16.0.0 netmask 255.255.255.0 { option subnet-mask 255.255.255.0; option routers 172.16.0.1; range 172.16.0.5 172.16.0.15; } host example0 { hardware ethernet 00:1A:6B:6A:2E:0B; fixed-address 10.0.0.20; } host example1 { hardware ethernet 00:1A:6B:6A:2E:0B; fixed-address 172.16.0.20; }
host example0 host declaration defines specific parameters for a single system, such as an IP address. To configure specific parameters for multiple hosts, use multiple host declarations.
host declarations, and as such, this name can anything, as long as it is unique to other host declarations. To configure the same system for multiple networks, use a different name for each host declaration, otherwise the DHCP daemon fails to start. Systems are identified by the hardware ethernet option, not the name in the host declaration.
hardware ethernet 00:1A:6B:6A:2E:0B; hardware ethernet option identifies the system. To find this address, run the ip link command.
fixed-address 10.0.0.20; fixed-address option assigns a valid IP address to the system specified by the hardware ethernet option. This address must be outside the IP address pool specified with the range option.
option statements do not end with a semicolon, the DHCP daemon fails to start, and an error such as the following is logged to /var/log/messages:
/etc/dhcp/dhcpd.conf line 20: semicolon expected. dhcpd: } dhcpd: ^ dhcpd: /etc/dhcp/dhcpd.conf line 38: unexpected end of file dhcpd: dhcpd: ^ dhcpd: Configuration file errors encountered -- exiting
host declarations configure a single system, that has multiple network interfaces, so that each interface receives the same IP address. This configuration will not work if both network interfaces are connected to the same network at the same time:
host interface0 {
hardware ethernet 00:1a:6b:6a:2e:0b;
fixed-address 10.0.0.18;
}
host interface1 {
hardware ethernet 00:1A:6B:6A:27:3A;
fixed-address 10.0.0.18;
}interface0 is the first network interface, and interface1 is the second interface. The different hardware ethernet options identify each interface.
host declarations, remembering to:
fixed-address for the network the host is connecting to.
host declaration unique.
host declaration is not unique, the DHCP daemon fails to start, and an error such as the following is logged to /var/log/messages:
dhcpd: /etc/dhcp/dhcpd.conf line 31: host interface0: already exists dhcpd: } dhcpd: ^ dhcpd: Configuration file errors encountered -- exiting
host interface0 declarations defined in /etc/dhcp/dhcpd.conf.
/etc/dhcp/dhcpd6.conf.
/usr/share/doc/dhcp-version/dhcpd6.conf.sample.
systemctl start dhcpd6.servicesubnet6 2001:db8:0:1::/64 {
range6 2001:db8:0:1::129 2001:db8:0:1::254;
option dhcp6.name-servers fec0:0:0:1::1;
option dhcp6.domain-search "domain.example";
}dhcpd man page — Describes how the DHCP daemon works.
dhcpd.conf man page — Explains how to configure the DHCP configuration file; includes some examples.
dhcpd.leases man page — Describes a persistent database of leases.
dhcp-options man page — Explains the syntax for declaring DHCP options in dhcpd.conf; includes some examples.
dhcrelay man page — Explains the DHCP Relay Agent and its configuration options.
/usr/share/doc/dhcp-version/ — Contains sample files, README files, and release notes for current versions of the DHCP service.
DNS (Domain Name System — система доменных имен), также известная как сервер имен, является сетевой системой, которая ассоциирует имена узлов с их IP-адресами. Для пользователей она обладает неоспоримым преимуществом — они могут обращаться к компьютерам в сети по именам, что обычно гораздо проще, нежели запоминать цифры, из которых состоит сетевой адрес. Системные администраторы, использующие сервер имен, могут менять IP-адрес узла, не затрагивая запросы к него по имени, либо назначать компьютеры, которые будут на них отвечать.
bob.sales.example.com
.). В указанном примере com определяет домен верхнего уровня, example является его поддоменом, а sales — поддоменом example. В данном примере bob определяет ресурсную запись, которая является частью домена sales.example.com. За исключением самой первой слева записи (то есть bob), каждая из секций называется зоной и определяет определенное пространство имен.
named, утилита администрирования rndc и отладочный инструмент dig. Обратитесь к разделу Глава 8, Services and Daemons, чтобы узнать как настраивать службы в Fedora.
BIND (Berkeley Internet Name Domain), the DNS server included in Fedora. It focuses on the structure of its configuration files, and describes how to administer it both locally and remotely.
named service is started, it reads the configuration from the files as described in Таблица 12.1, «The named service configuration files».
| Path | Description |
|---|---|
/etc/named.conf
| The main configuration file. |
/etc/named/
| An auxiliary directory for configuration files that are included in the main configuration file. |
{ and }). Note that when editing the file, you have to be careful not to make any syntax error, otherwise the named service will not start. A typical /etc/named.conf file is organized as follows:
statement-1["statement-1-name"] [statement-1-class] {option-1;option-2;option-N; };statement-2["statement-2-name"] [statement-2-class] {option-1;option-2;option-N; };statement-N["statement-N-name"] [statement-N-class] {option-1;option-2;option-N; };
/var/named/chroot environment. In that case, the initialization script will mount the above configuration files using the mount --bind command, so that you can manage the configuration outside this environment.
/etc/named.conf:
acl acl (Access Control List) statement allows you to define groups of hosts, so that they can be permitted or denied access to the nameserver. It takes the following form:
aclacl-name{match-element; ... };
acl-name statement name is the name of the access control list, and the match-element option is usually an individual IP address (such as 10.0.1.1) or a CIDR network notation (for example, 10.0.1.0/24). For a list of already defined keywords, see Таблица 12.2, «Predefined access control lists».
| Keyword | Description |
|---|---|
any
| Matches every IP address. |
localhost
| Matches any IP address that is in use by the local system. |
localnets
| Matches any IP address on any network to which the local system is connected. |
none
| Does not match any IP address. |
acl statement can be especially useful with conjunction with other statements such as options. Пример 12.1, «Using acl in conjunction with options» defines two access control lists, black-hats and red-hats, and adds black-hats on the blacklist while granting red-hats a normal access.
acl black-hats {
10.0.2.0/24;
192.168.0.0/24;
1234:5678::9abc/24;
};
acl red-hats {
10.0.1.0/24;
};
options {
blackhole { black-hats; };
allow-query { red-hats; };
allow-query-cache { red-hats; };
};include include statement allows you to include files in the /etc/named.conf, so that potentially sensitive data can be placed in a separate file with restricted permissions. It takes the following form:
include "file-name"file-name statement name is an absolute path to a file.
include "/etc/named.rfc1912.zones";
options options statement allows you to define global server configuration options as well as to set defaults for other statements. It can be used to specify the location of the named working directory, the types of queries allowed, and much more. It takes the following form:
options {
option;
...
};option directives, see Таблица 12.3, «Commonly used options» below.
| Option | Description |
|---|---|
allow-query
| Specifies which hosts are allowed to query the nameserver for authoritative resource records. It accepts an access control lists, a collection of IP addresses, or networks in the CIDR notation. All hosts are allowed by default. |
allow-query-cache
|
Specifies which hosts are allowed to query the nameserver for non-authoritative data such as recursive queries. Only localhost and localnets are allowed by default.
|
blackhole
|
Specifies which hosts are not allowed to query the nameserver. This option should be used when particular host or network floods the server with requests. The default option is none.
|
directory
|
Specifies a working directory for the named service. The default option is /var/named/.
|
dnssec-enable
|
Specifies whether to return DNSSEC related resource records. The default option is yes.
|
dnssec-validation
|
Specifies whether to prove that resource records are authentic via DNSSEC. The default option is yes.
|
forwarders
| Specifies a list of valid IP addresses for nameservers to which the requests should be forwarded for resolution. |
forward
|
Specifies the behavior of the
forwarders directive. It accepts the following options:
|
listen-on
| Specifies the IPv4 network interface on which to listen for queries. On a DNS server that also acts as a gateway, you can use this option to answer queries originating from a single network only. All IPv4 interfaces are used by default. |
listen-on-v6
| Specifies the IPv6 network interface on which to listen for queries. On a DNS server that also acts as a gateway, you can use this option to answer queries originating from a single network only. All IPv6 interfaces are used by default. |
max-cache-size
|
Specifies the maximum amount of memory to be used for server caches. When the limit is reached, the server causes records to expire prematurely so that the limit is not exceeded. In a server with multiple views, the limit applies separately to the cache of each view. The default option is 32M.
|
notify
|
Specifies whether to notify the secondary nameservers when a zone is updated. It accepts the following options:
|
pid-file
|
Specifies the location of the process ID file created by the named service.
|
recursion
|
Specifies whether to act as a recursive server. The default option is yes.
|
statistics-file
|
Specifies an alternate location for statistics files. The /var/named/named.stats file is used by default.
|
allow-query-cache option to restrict recursive DNS services for a particular subset of clients only.
named.conf manual page for a complete list of available options.
options {
allow-query { localhost; };
listen-on port 53 { 127.0.0.1; };
listen-on-v6 port 53 { ::1; };
max-cache-size 256M;
directory "/var/named";
statistics-file "/var/named/data/named_stats.txt";
recursion yes;
dnssec-enable yes;
dnssec-validation yes;
};zone zone statement allows you to define the characteristics of a zone, such as the location of its configuration file and zone-specific options, and can be used to override the global options statements. It takes the following form:
zonezone-name[zone-class] {option; ... };
zone-name attribute is the name of the zone, zone-class is the optional class of the zone, and option is a zone statement option as described in Таблица 12.4, «Commonly used options».
zone-name attribute is particularly important, as it is the default value assigned for the $ORIGIN directive used within the corresponding zone file located in the /var/named/ directory. The named daemon appends the name of the zone to any non-fully qualified domain name listed in the zone file. For example, if a zone statement defines the namespace for example.com, use example.com as the zone-name so that it is placed at the end of hostnames within the example.com zone file.
| Option | Description |
|---|---|
allow-query
|
Specifies which clients are allowed to request information about this zone. This option overrides global allow-query option. All query requests are allowed by default.
|
allow-transfer
| Specifies which secondary servers are allowed to request a transfer of the zone's information. All transfer requests are allowed by default. |
allow-update
|
Specifies which hosts are allowed to dynamically update information in their zone. The default option is to deny all dynamic update requests.
Note that you should be careful when allowing hosts to update information about their zone. Do not set IP addresses in this option unless the server is in the trusted network. Instead, use TSIG key as described in Раздел 12.2.5.3, «Transaction SIGnatures (TSIG)».
|
file
|
Specifies the name of the file in the named working directory that contains the zone's configuration data.
|
masters
|
Specifies from which IP addresses to request authoritative zone information. This option is used only if the zone is defined as type slave.
|
notify
|
Specifies whether to notify the secondary nameservers when a zone is updated. It accepts the following options:
|
type
|
Specifies the zone type. It accepts the following options:
|
/etc/named.conf file of a primary or secondary nameserver involve adding, modifying, or deleting zone statements, and only a small subset of zone statement options is usually needed for a nameserver to work efficiently.
example.com, the type is set to master, and the named service is instructed to read the /var/named/example.com.zone file. It also allows only a secondary nameserver (192.168.0.2) to transfer the zone.
zone "example.com" IN {
type master;
file "example.com.zone";
allow-transfer { 192.168.0.2; };
};zone statement is slightly different. The type is set to slave, and the masters directive is telling named the IP address of the master server.
named service is configured to query the primary server at the 192.168.0.1 IP address for information about the example.com zone. The received information is then saved to the /var/named/slaves/example.com.zone file. Note that you have to put all slave zones to /var/named/slaves directory, otherwise the service will fail to transfer the zone.
zone "example.com" {
type slave;
file "slaves/example.com.zone";
masters { 192.168.0.1; };
};/etc/named.conf:
controls controls statement allows you to configure various security requirements necessary to use the rndc command to administer the named service.
rndc utility and its usage.
key key statement allows you to define a particular key by name. Keys are used to authenticate various actions, such as secure updates or the use of the rndc command. Two options are used with key:
algorithm algorithm-name — The type of algorithm to be used (for example, hmac-md5).
secret "key-value" — The encrypted key.
rndc utility and its usage.
logging logging statement allows you to use multiple types of logs, so called channels. By using the channel option within the statement, you can construct a customized type of log with its own file name (file), size limit (size), versioning (version), and level of importance (severity). Once a customized channel is defined, a category option is used to categorize the channel and begin logging when the named service is restarted.
named sends standard messages to the rsyslog daemon, which places them in /var/log/messages. Several standard channels are built into BIND with various severity levels, such as default_syslog (which handles informational logging messages) and default_debug (which specifically handles debugging messages). A default category, called default, uses the built-in channels to do normal logging without any special configuration.
server server statement allows you to specify options that affect how the named service should respond to remote nameservers, especially with regard to notifications and zone transfers.
transfer-format option controls the number of resource records that are sent with each message. It can be either one-answer (only one resource record), or many-answers (multiple resource records). Note that while the many-answers option is more efficient, it is not supported by older versions of BIND.
trusted-keys trusted-keys statement allows you to specify assorted public keys used for secure DNS (DNSSEC). Refer to Раздел 12.2.5.4, «DNS Security Extensions (DNSSEC)» for more information on this topic.
view view statement allows you to create special views depending upon which network the host querying the nameserver is on. This allows some hosts to receive one answer regarding a zone while other hosts receive totally different information. Alternatively, certain zones may only be made available to particular trusted hosts while non-trusted hosts can only make queries for other zones.
match-clients option allows you to specify the IP addresses that apply to a particular view. If the options statement is used within a view, it overrides the already configured global options. Finally, most view statements contain multiple zone statements that apply to the match-clients list.
view statements are listed is important, as the first statement that matches a particular client's IP address is used. For more information on this topic, refer to Раздел 12.2.5.1, «Multiple Views».
/etc/named.conf file can also contain comments. Comments are ignored by the named service, but can prove useful when providing additional information to a user. The following are valid comment tags:
//// characters to the end of the line is considered a comment. For example:
notify yes; // notify all secondary nameservers
## character to the end of the line is considered a comment. For example:
notify yes; # notify all secondary nameservers
/* and *//* and */ is considered a comment. For example:
notify yes; /* notify all secondary nameservers */
named working directory located in /var/named/ by default, and each zone file is named according to the file option in the zone statement, usually in a way that relates to the domain in question and identifies the file as containing zone data, such as example.com.zone.
| Path | Description |
|---|---|
/var/named/
|
The working directory for the named service. The nameserver is not allowed to write to this directory.
|
/var/named/slaves/
|
The directory for secondary zones. This directory is writable by the named service.
|
/var/named/dynamic/
|
The directory for other files, such as dynamic DNS (DDNS) zones or managed DNSSEC keys. This directory is writable by the named service.
|
/var/named/data/
|
The directory for various statistics and debugging files. This directory is writable by the named service.
|
$) followed by the name of the directive, and usually appear at the top of the file. The following directives are commonly used in zone files:
$INCLUDE $INCLUDE directive allows you to include another file at the place where it appears, so that other zone settings can be stored in a separate zone file.
$INCLUDE /var/named/penguin.example.com
$ORIGIN $ORIGIN directive allows you to append the domain name to unqualified records, such as those with the hostname only. Note that the use of this directive is not necessary if the zone is specified in /etc/named.conf, since the zone name is used by default.
. character) are appended with example.com.
$ORIGIN example.com.
$TTL $TTL directive allows you to set the default Time to Live (TTL) value for the zone, that is, how long is a zone record valid. Each resource record can contain its own TTL value, which overrides this directive.
$TTL 1D
A hostnameIN AIP-address
hostname value is omitted, the record will point to the last specified hostname.
server1.example.com are pointed to 10.0.1.3 or 10.0.1.5.
server1 IN A 10.0.1.3
IN A 10.0.1.5CNAME alias-nameIN CNAMEreal-name
CNAME records are most commonly used to point to services that use a common naming scheme, such as www for Web servers. However, there are multiple restrictions for their usage:
A record binds a hostname to an IP address, while the CNAME record points the commonly used www hostname to it.
server1 IN A 10.0.1.5 www IN CNAME server1
MX IN MXpreference-valueemail-server-name
email-server-name is a fully qualified domain name (FQDN). The preference-value allows numerical ranking of the email servers for a namespace, giving preference to some email systems over others. The MX resource record with the lowest preference-value is preferred over the others. However, multiple email servers can possess the same value to distribute email traffic evenly among them.
mail.example.com email server is preferred to the mail2.example.com email server when receiving email destined for the example.com domain.
example.com. IN MX 10 mail.example.com.
IN MX 20 mail2.example.com.NS IN NS nameserver-namenameserver-name should be a fully qualified domain name (FQDN). Note that when two nameservers are listed as authoritative for the domain, it is not important whether these nameservers are secondary nameservers, or if one of them is a primary server. They are both still considered authoritative.
IN NS dns1.example.com. IN NS dns2.example.com.
PTR last-IP-digitIN PTRFQDN-of-system
last-IP-digit directive is the last number in an IP address, and the FQDN-of-system is a fully qualified domain name (FQDN).
PTR records are primarily used for reverse name resolution, as they point IP addresses back to a particular name. Refer to Раздел 12.2.2.4.2, «A Reverse Name Resolution Zone File» for more examples of PTR records in use.
SOA @ IN SOAprimary-name-serverhostmaster-email(serial-numbertime-to-refreshtime-to-retrytime-to-expireminimum-TTL)
@ symbol places the $ORIGIN directive (or the zone's name if the $ORIGIN directive is not set) as the namespace being defined by this SOA resource record.
primary-name-server directive is the hostname of the primary nameserver that is authoritative for this domain.
hostmaster-email directive is the email of the person to contact about the namespace.
serial-number directive is a numerical value incremented every time the zone file is altered to indicate it is time for the named service to reload the zone.
time-to-refresh directive is the numerical value secondary nameservers use to determine how long to wait before asking the primary nameserver if any changes have been made to the zone.
time-to-retry directive is a numerical value used by secondary nameservers to determine the length of time to wait before issuing a refresh request in the event that the primary nameserver is not answering. If the primary server has not replied to a refresh request before the amount of time specified in the time-to-expire directive elapses, the secondary servers stop responding as an authority for requests concerning that namespace.
minimum-TTL directive is the amount of time other nameservers cache the zone's information. In BIND 9, it defines how long negative answers are cached for. Caching of negative answers can be set to a maximum of 3 hours (that is, 3H).
M), hours (H), days (D), and weeks (W). Таблица 12.6, «Seconds compared to other time units» shows an amount of time in seconds and the equivalent time in another format.
| Seconds | Other Time Units |
|---|---|
| 60 |
1M
|
| 1800 |
30M
|
| 3600 |
1H
|
| 10800 |
3H
|
| 21600 |
6H
|
| 43200 |
12H
|
| 86400 |
1D
|
| 259200 |
3D
|
| 604800 |
1W
|
| 31536000 |
365D
|
@ IN SOA dns1.example.com. hostmaster.example.com. (
2001062501 ; serial
21600 ; refresh after 6 hours
3600 ; retry after 1 hour
604800 ; expire after 1 week
86400 ) ; minimum TTL of 1 daynamed service, but can prove useful when providing additional information to the user. Any text after the semicolon character (that is, ;) to the end of the line is considered a comment. For example:
604800 ; expire after 1 week
SOA values.
$ORIGIN example.com.
$TTL 86400
@ IN SOA dns1.example.com. hostmaster.example.com. (
2001062501 ; serial
21600 ; refresh after 6 hours
3600 ; retry after 1 hour
604800 ; expire after 1 week
86400 ) ; minimum TTL of 1 day
;
;
IN NS dns1.example.com.
IN NS dns2.example.com.
dns1 IN A 10.0.1.1
IN AAAA aaaa:bbbb::1
dns2 IN A 10.0.1.2
IN AAAA aaaa:bbbb::2
;
;
@ IN MX 10 mail.example.com.
IN MX 20 mail2.example.com.
mail IN A 10.0.1.5
IN AAAA aaaa:bbbb::5
mail2 IN A 10.0.1.6
IN AAAA aaaa:bbbb::6
;
;
; This sample zone file illustrates sharing the same IP addresses
; for multiple services:
;
services IN A 10.0.1.10
IN AAAA aaaa:bbbb::10
IN A 10.0.1.11
IN AAAA aaaa:bbbb::11
ftp IN CNAME services.example.com.
www IN CNAME services.example.com.
;
;dns1.example.com and dns2.example.com, and are tied to the 10.0.1.1 and 10.0.1.2 IP addresses respectively using the A record.
MX records point to mail and mail2 via A records. Since these names do not end in a trailing period (that is, the . character), the $ORIGIN domain is placed after them, expanding them to mail.example.com and mail2.example.com.
www.example.com (WWW), are pointed at the appropriate servers using the CNAME record.
zone statement in the /etc/named.conf similar to the following:
zone "example.com" IN {
type master;
file "example.com.zone";
allow-update { none; };
};PTR resource records are used to link the IP addresses to a fully qualified domain name as shown in Пример 12.15, «A reverse name resolution zone file».
$ORIGIN 1.0.10.in-addr.arpa.
$TTL 86400
@ IN SOA dns1.example.com. hostmaster.example.com. (
2001062501 ; serial
21600 ; refresh after 6 hours
3600 ; retry after 1 hour
604800 ; expire after 1 week
86400 ) ; minimum TTL of 1 day
;
@ IN NS dns1.example.com.
;
1 IN PTR dns1.example.com.
2 IN PTR dns2.example.com.
;
5 IN PTR server1.example.com.
6 IN PTR server2.example.com.
;
3 IN PTR ftp.example.com.
4 IN PTR ftp.example.com.10.0.1.1 through 10.0.1.6 are pointed to the corresponding fully qualified domain name.
zone statement in the /etc/named.conf file similar to the following:
zone "1.0.10.in-addr.arpa" IN {
type master;
file "example.com.rr.zone";
allow-update { none; };
};zone statement, except for the zone name. Note that a reverse name resolution zone requires the first three blocks of the IP address reversed followed by .in-addr.arpa. This allows the single block of IP numbers used in the reverse name resolution zone file to be associated with the zone.
rndc utility is a command line tool that allows you to administer the named service, both locally and from a remote machine. Its usage is as follows:
rndc[option...]command[command-option]
named must be configured to listen on the selected port (that is, 953 by default), and an identical key must be used by both the service and the rndc utility.
rndc configuration is located in /etc/rndc.conf. If the file does not exist, the utility will use the key located in /etc/rndc.key, which was generated automatically during the installation process using the rndc-confgen -a command.
named service is configured using the controls statement in the /etc/named.conf configuration file as described in Раздел 12.2.1.2, «Other Statement Types». Unless this statement is present, only the connections from the loopback address (that is, 127.0.0.1) will be allowed, and the key located in /etc/rndc.key will be used.
/etc/rndc.key file:
~]# chmod o-rwx /etc/rndc.keynamed service, use the following command:
~]# rndc status
version: 9.7.0-P2-RedHat-9.7.0-5.P2.el6
CPUs found: 1
worker threads: 1
number of zones: 16
debug level: 0
xfers running: 0
xfers deferred: 0
soa queries in progress: 0
query logging is OFF
recursive clients: 0/0/1000
tcp clients: 0/100
server is up and running~]# rndc reload
server reload successfulreload command, for example:
~]# rndc reload localhost
zone reload up-to-date~]# rndc reconfigfreeze command first:
~]# rndc freeze localhostthaw command to allow the DDNS again and reload the zone:
~]# rndc thaw localhost
The zone reload and thaw was successful.sign command. For example:
~]# rndc sign localhostauto-dnssec option has to be set to maintain in the zone statement. For instance:
zone "localhost" IN {
type master;
file "named.localhost";
allow-update { none; };
auto-dnssec maintain;
};~]# rndc validation on~]# rndc validation offoptions statement described in Раздел 12.2.1.1, «Common Statement Types» for information on how configure this option in /etc/named.conf.
~]# rndc querylogstatus command as described in Раздел 12.2.3.2, «Checking the Service Status».
dig utility is a command line tool that allows you to perform DNS lookups and debug a nameserver configuration. Its typical usage is as follows:
dig[@server] [option...]nametype
types.
dignameNS
dig utility is used to display nameservers for example.com.
~]$ dig example.com NS
; <<>> DiG 9.7.1-P2-RedHat-9.7.1-2.P2.fc13 <<>> example.com NS
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 57883
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;example.com. IN NS
;; ANSWER SECTION:
example.com. 99374 IN NS a.iana-servers.net.
example.com. 99374 IN NS b.iana-servers.net.
;; Query time: 1 msec
;; SERVER: 10.34.255.7#53(10.34.255.7)
;; WHEN: Wed Aug 18 18:04:06 2010
;; MSG SIZE rcvd: 77dignameA
dig utility is used to display the IP address of example.com.
~]$ dig example.com A
; <<>> DiG 9.7.1-P2-RedHat-9.7.1-2.P2.fc13 <<>> example.com A
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 4849
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 2, ADDITIONAL: 0
;; QUESTION SECTION:
;example.com. IN A
;; ANSWER SECTION:
example.com. 155606 IN A 192.0.32.10
;; AUTHORITY SECTION:
example.com. 99175 IN NS a.iana-servers.net.
example.com. 99175 IN NS b.iana-servers.net.
;; Query time: 1 msec
;; SERVER: 10.34.255.7#53(10.34.255.7)
;; WHEN: Wed Aug 18 18:07:25 2010
;; MSG SIZE rcvd: 93dig-xaddress
dig utility is used to display the hostname assigned to 192.0.32.10.
~]$ dig -x 192.0.32.10
; <<>> DiG 9.7.1-P2-RedHat-9.7.1-2.P2.fc13 <<>> -x 192.0.32.10
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 29683
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 5, ADDITIONAL: 6
;; QUESTION SECTION:
;10.32.0.192.in-addr.arpa. IN PTR
;; ANSWER SECTION:
10.32.0.192.in-addr.arpa. 21600 IN PTR www.example.com.
;; AUTHORITY SECTION:
32.0.192.in-addr.arpa. 21600 IN NS b.iana-servers.org.
32.0.192.in-addr.arpa. 21600 IN NS c.iana-servers.net.
32.0.192.in-addr.arpa. 21600 IN NS d.iana-servers.net.
32.0.192.in-addr.arpa. 21600 IN NS ns.icann.org.
32.0.192.in-addr.arpa. 21600 IN NS a.iana-servers.net.
;; ADDITIONAL SECTION:
a.iana-servers.net. 13688 IN A 192.0.34.43
b.iana-servers.org. 5844 IN A 193.0.0.236
b.iana-servers.org. 5844 IN AAAA 2001:610:240:2::c100:ec
c.iana-servers.net. 12173 IN A 139.91.1.10
c.iana-servers.net. 12173 IN AAAA 2001:648:2c30::1:10
ns.icann.org. 12884 IN A 192.0.34.126
;; Query time: 156 msec
;; SERVER: 10.34.255.7#53(10.34.255.7)
;; WHEN: Wed Aug 18 18:25:15 2010
;; MSG SIZE rcvd: 310named service to provide name resolution services or to act as an authority for a particular domain. However, BIND version 9 has a number of advanced features that allow for a more secure and efficient DNS service.
view statement to the /etc/named.conf configuration file. Use the match-clients option to match IP addresses or entire networks and give them special options and zone data.
SERFVAIL response is returned for each resource record that fails the validation.
dig utility as described in Раздел 12.2.4, «Using the dig Utility». Useful options are +dnssec (requests DNSSEC-related resource records by setting the DNSSEC OK bit), +cd (tells recursive nameserver not to validate the response), and +bufsize=512 (changes the packet size to 512B to get through some firewalls).
AAAA resource records, and the listen-on-v6 directive as described in Таблица 12.3, «Commonly used options».
/etc/named.conf file can prevent the named service from starting.
. character) correctlynamed service will append the name of the zone or the value of $ORIGIN to complete it.
named service to other nameservers, the recommended best practice is to change the firewall settings whenever possible.
version with the version of the bind package installed on the system:
/usr/share/doc/bind-version//usr/share/doc/bind-version/arm//usr/share/doc/bind-version/draft//usr/share/doc/bind-version/misc/migration document for specific changes they must make when moving to BIND 9. The options file lists all of the options implemented in BIND 9 that are used in /etc/named.conf.
/usr/share/doc/bind-version/rfc/man rndcrndc containing the full documentation on its usage.
man namednamed containing the documentation on assorted arguments that can be used to control the BIND nameserver daemon.
man lwresdlwresd containing the full documentation on the lightweight resolver daemon and its usage.
man named.confnamed configuration file.
man rndc.confrndc configuration file.
HTTP (Hypertext Transfer Protocol) сервер, или web сервер, это сетевая служба которая предоставляет контент клиенту через интернет. Обычно под этим подразумеваются веб-страницы, но также этим могут являться и любые другие документы.
httpd service, and covers advanced topics such as adding server modules, setting up virtual hosts, or configuring the secure HTTP server.
httpd service configuration accordingly. This section reviews some of the newly added features, outlines important changes, and guides you through the update of older configuration files.
httpd service configuration:
LoadModule directive for each module that has been renamed.
/etc/httpd/conf.d/ssl.conf to enable the Secure Sockets Layer (SSL) protocol.
service httpd configtesthttpd service, make sure you have the httpd installed. You can do so by using the following command as root:
yum install httpdhttpd service, type the following at a shell prompt as root:
systemctl start httpd.servicesystemctl enable httpd.servicehttpd service, type the following at a shell prompt as root:
systemctl stop httpd.servicesystemctl disable httpd.servicehttpd service:
root:
systemctl restart httpd.servicehttpd service, and then start it again. Use this command after installing or removing a dynamically loaded module such as PHP.
root, type:
systemctl reload httpd.servicehttpd service to reload the configuration file. Note that any requests being currently processed will be interrupted, which may cause a client browser to display an error message or render a partial page.
root:
service httpd gracefulhttpd service to reload the configuration file. Note that any requests being currently processed will use the old configuration.
systemctl is-active httpd.servicehttpd service is started, by default, it reads the configuration from locations that are listed in Таблица 13.1, «The httpd service configuration files».
httpd service.
service httpd configtest/etc/httpd/conf/httpd.conf configuration file:
<Directory> <Directory> directive allows you to apply certain directives to a particular directory only. It takes the following form:
<Directorydirectory>directive… </Directory>
directory can be either a full path to an existing directory in the local file system, or a wildcard expression.
cgi-bin directories for server-side scripts located outside the directory that is specified by ScriptAlias. In this case, the ExecCGI and AddHandler directives must be supplied, and the permissions on the target directory must be set correctly (that is, 0755).
<Directory /var/www/html> Options Indexes FollowSymLinks AllowOverride None Order allow,deny Allow from all </Directory>
<IfDefine> IfDefine directive allows you to use certain directives only when a particular parameter is supplied on the command line. It takes the following form:
<IfDefine [!]parameter>directive… </IfDefine>
parameter can be supplied at a shell prompt using the -Dparameter command line option (for example, httpd -DEnableHome). If the optional exclamation mark (that is, !) is present, the enclosed directives are used only when the parameter is not specified.
<IfDefine EnableHome> UserDir public_html </IfDefine>
<IfModule> <IfModule> directive allows you to use certain directive only when a particular module is loaded. It takes the following form:
<IfModule [!]module>directive… </IfModule>
module can be identified either by its name, or by the file name. If the optional exclamation mark (that is, !) is present, the enclosed directives are used only when the module is not loaded.
<IfModule mod_disk_cache.c> CacheEnable disk / CacheRoot /var/cache/mod_proxy </IfModule>
<Location> <Location> directive allows you to apply certain directives to a particular URL only. It takes the following form:
<Locationurl>directive… </Location>
url can be either a path relative to the directory specified by the DocumentRoot directive (for example, /server-info), or an external URL such as http://example.com/server-info.
<Location /server-info> SetHandler server-info Order deny,allow Deny from all Allow from .example.com </Location>
<Proxy> <Proxy> directive allows you to apply certain directives to the proxy server only. It takes the following form:
<Proxypattern>directive… </Proxy>
pattern can be an external URL, or a wildcard expression (for example, http://example.com/*).
<Proxy *> Order deny,allow Deny from all Allow from .example.com </Proxy>
<VirtualHost> <VirtualHost> directive allows you apply certain directives to particular virtual hosts only. It takes the following form:
<VirtualHostaddress[:port]…>directive… </VirtualHost>
address can be an IP address, a fully qualified domain name, or a special form as described in Таблица 13.2, «Available <VirtualHost> options».
| Option | Description |
|---|---|
*
| Represents all IP addresses. |
_default_
| Represents unmatched IP addresses. |
<VirtualHost *:80> ServerAdmin webmaster@penguin.example.com DocumentRoot /www/docs/penguin.example.com ServerName penguin.example.com ErrorLog logs/penguin.example.com-error_log CustomLog logs/penguin.example.com-access_log common </VirtualHost>
AccessFileName AccessFileName directive allows you to specify the file to be used to customize access control information for each directory. It takes the following form:
AccessFileName filename…filename is a name of the file to look for in the requested directory. By default, the server looks for .htaccess.
Files tag to prevent the files beginning with .ht from being accessed by web clients. This includes the .htaccess and .htpasswd files.
AccessFileName .htaccess <Files ~ "^\.ht"> Order allow,deny Deny from all Satisfy All </Files>
Action Action directive allows you to specify a CGI script to be executed when a certain media type is requested. It takes the following form:
Actioncontent-typepath
content-type has to be a valid MIME type such as text/html, image/png, or application/pdf. The path refers to an existing CGI script, and must be relative to the directory specified by the DocumentRoot directive (for example, /cgi-bin/process-image.cgi).
Action image/png /cgi-bin/process-image.cgi
AddDescription AddDescription directive allows you to specify a short description to be displayed in server-generated directory listings for a given file. It takes the following form:
AddDescription "description"filename…
description should be a short text enclosed in double quotes (that is, "). The filename can be a full file name, a file extension, or a wildcard expression.
AddDescription "GZIP compressed tar archive" .tgz
AddEncoding AddEncoding directive allows you to specify an encoding type for a particular file extension. It takes the following form:
AddEncodingencodingextension…
encoding has to be a valid MIME encoding such as x-compress, x-gzip, etc. The extension is a case sensitive file extension, and is conventionally written with a leading dot (for example, .gz).
AddEncoding x-gzip .gz .tgz
AddHandler AddHandler directive allows you to map certain file extensions to a selected handler. It takes the following form:
AddHandlerhandlerextension…
handler has to be a name of previously defined handler. The extension is a case sensitive file extension, and is conventionally written with a leading dot (for example, .cgi).
.cgi extension as CGI scripts regardless of the directory they are in. Additionally, it is also commonly used to process server-parsed HTML and image-map files.
AddHandler cgi-script .cgi
AddIcon AddIcon directive allows you to specify an icon to be displayed for a particular file in server-generated directory listings. It takes the following form:
AddIconpathpattern…
path refers to an existing icon file, and must be relative to the directory specified by the DocumentRoot directive (for example, /icons/folder.png). The pattern can be a file name, a file extension, a wildcard expression, or a special form as described in the following table:
| Option | Description |
|---|---|
^^DIRECTORY^^
| Represents a directory. |
^^BLANKICON^^
| Represents a blank line. |
AddIcon /icons/text.png .txt README
AddIconByEncoding AddIconByEncoding directive allows you to specify an icon to be displayed for a particular encoding type in server-generated directory listings. It takes the following form:
AddIconByEncodingpathencoding…
path refers to an existing icon file, and must be relative to the directory specified by the DocumentRoot directive (for example, /icons/compressed.png). The encoding has to be a valid MIME encoding such as x-compress, x-gzip, etc.
AddIconByEncoding /icons/compressed.png x-compress x-gzip
AddIconByType AddIconByType directive allows you to specify an icon to be displayed for a particular media type in server-generated directory listings. It takes the following form:
AddIconByTypepathcontent-type…
path refers to an existing icon file, and must be relative to the directory specified by the DocumentRoot directive (for example, /icons/text.png). The content-type has to be either a valid MIME type (for example, text/html or image/png), or a wildcard expression such as text/*, image/*, etc.
AddIconByType /icons/video.png video/*
AddLanguage AddLanguage directive allows you to associate a file extension with a specific language. It takes the following form:
AddLanguagelanguageextension…
language has to be a valid MIME language such as cs, en, or fr. The extension is a case sensitive file extension, and is conventionally written with a leading dot (for example, .cs).
AddLanguage cs .cs .cz
AddType AddType directive allows you to define or override the media type for a particular file extension. It takes the following form:
AddTypecontent-typeextension…
content-type has to be a valid MIME type such as text/html, image/png, etc. The extension is a case sensitive file extension, and is conventionally written with a leading dot (for example, .cs).
AddType application/x-gzip .gz .tgz
Alias Alias directive allows you to refer to files and directories outside the default directory specified by the DocumentRoot directive. It takes the following form:
Aliasurl-pathreal-path
url-path must be relative to the directory specified by the DocumentRoot directive (for example, /images/). The real-path is a full path to a file or directory in the local file system.
Directory tag with additional permissions to access the target directory. By default, the /icons/ alias is created so that the icons from /var/www/icons/ are displayed in server-generated directory listings.
Alias /icons/ /var/www/icons/ <Directory "/var/www/icons"> Options Indexes MultiViews FollowSymLinks AllowOverride None Order allow,deny Allow from all <Directory>
AllowAllow directive allows you to specify which clients have permission to access a given directory. It takes the following form:
Allow from client…client can be a domain name, an IP address (both full and partial), a network/netmask pair, or all for all clients.
Allow from 192.168.1.0/255.255.255.0
AllowOverride AllowOverride directive allows you to specify which directives in a .htaccess file can override the default configuration. It takes the following form:
AllowOverride type…type has to be one of the available grouping options as described in Таблица 13.4, «Available AllowOverride options».
| Option | Description |
|---|---|
All
|
All directives in .htaccess are allowed to override earlier configuration settings.
|
None
|
No directive in .htaccess is allowed to override earlier configuration settings.
|
AuthConfig
|
Allows the use of authorization directives such as AuthName, AuthType, or Require.
|
FileInfo
|
Allows the use of file type, metadata, and mod_rewrite directives such as DefaultType, RequestHeader, or RewriteEngine, as well as the Action directive.
|
Indexes
|
Allows the use of directory indexing directives such as AddDescription, AddIcon, or FancyIndexing.
|
Limit
|
Allows the use of host access directives, that is, Allow, Deny, and Order.
|
Options[=option,…]
|
Allows the use of the Options directive. Additionally, you can provide a comma-separated list of options to customize which options can be set using this directive.
|
AllowOverride FileInfo AuthConfig Limit
BrowserMatch BrowserMatch directive allows you to modify the server behavior based on the client's web browser type. It takes the following form:
BrowserMatchpatternvariable…
pattern is a regular expression to match the User-Agent HTTP header field. The variable is an environment variable that is set when the header field matches the pattern.
BrowserMatch "Mozilla/2" nokeepalive
CacheDefaultExpire CacheDefaultExpire option allows you to set how long to cache a document that does not have any expiration date or the date of its last modification specified. It takes the following form:
CacheDefaultExpire timetime is specified in seconds. The default option is 3600 (that is, one hour).
CacheDefaultExpire 3600
CacheDisable CacheDisable directive allows you to disable caching of certain URLs. It takes the following form:
CacheDisable pathpath must be relative to the directory specified by the DocumentRoot directive (for example, /files/).
CacheDisable /temporary
CacheEnable CacheEnable directive allows you to specify a cache type to be used for certain URLs. It takes the following form:
CacheEnabletypeurl
type has to be a valid cache type as described in Таблица 13.5, «Available cache types». The url can be a path relative to the directory specified by the DocumentRoot directive (for example, /images/), a protocol (for example, ftp://), or an external URL such as http://example.com/.
| Type | Description |
|---|---|
mem
| The memory-based storage manager. |
disk
| The disk-based storage manager. |
fd
| The file descriptor cache. |
CacheEnable disk /
CacheLastModifiedFactor CacheLastModifiedFactor directive allows you to customize how long to cache a document that does not have any expiration date specified, but that provides information about the date of its last modification. It takes the following form:
CacheLastModifiedFactor numbernumber is a coefficient to be used to multiply the time that passed since the last modification of the document. The default option is 0.1 (that is, one tenth).
CacheLastModifiedFactor 0.1
CacheMaxExpire CacheMaxExpire directive allows you to specify the maximum amount of time to cache a document. It takes the following form:
CacheMaxExpire timetime is specified in seconds. The default option is 86400 (that is, one day).
CacheMaxExpire 86400
CacheNegotiatedDocs CacheNegotiatedDocs directive allows you to enable caching of the documents that were negotiated on the basis of content. It takes the following form:
CacheNegotiatedDocs optionoption has to be a valid keyword as described in Таблица 13.6, «Available CacheNegotiatedDocs options». Since the content-negotiated documents may change over time or because of the input from the requester, the default option is Off.
| Option | Description |
|---|---|
On
| Enables caching the content-negotiated documents. |
Off
| Disables caching the content-negotiated documents. |
CacheNegotiatedDocs On
CacheRoot CacheRoot directive allows you to specify the directory to store cache files in. It takes the following form:
CacheRoot directorydirectory must be a full path to an existing directory in the local file system. The default option is /var/cache/mod_proxy/.
CacheRoot /var/cache/mod_proxy
CustomLog CustomLog directive allows you to specify the log file name and the log file format. It takes the following form:
CustomLogpathformat
path refers to a log file, and must be relative to the directory that is specified by the ServerRoot directive (that is, /etc/httpd/ by default). The format has to be either an explicit format string, or a format name that was previously defined using the LogFormat directive.
CustomLog logs/access_log combined
DefaultIcon DefaultIcon directive allows you to specify an icon to be displayed for a file in server-generated directory listings when no other icon is associated with it. It takes the following form:
DefaultIcon pathpath refers to an existing icon file, and must be relative to the directory specified by the DocumentRoot directive (for example, /icons/unknown.png).
DefaultIcon /icons/unknown.png
DefaultType DefaultType directive allows you to specify a media type to be used in case the proper MIME type cannot be determined by the server. It takes the following form:
DefaultType content-typecontent-type has to be a valid MIME type such as text/html, image/png, application/pdf, etc.
DefaultType text/plain
Deny Deny directive allows you to specify which clients are denied access to a given directory. It takes the following form:
Deny from client…client can be a domain name, an IP address (both full and partial), a network/netmask pair, or all for all clients.
Deny from 192.168.1.1
DirectoryIndex DirectoryIndex directive allows you to specify a document to be served to a client when a directory is requested (that is, when the URL ends with the / character). It takes the following form:
DirectoryIndex filename…filename is a name of the file to look for in the requested directory. By default, the server looks for index.html, and index.html.var.
DirectoryIndex index.html index.html.var
DocumentRoot DocumentRoot directive allows you to specify the main directory from which the content is served. It takes the following form:
DocumentRoot directorydirectory must be a full path to an existing directory in the local file system. The default option is /var/www/html/.
DocumentRoot /var/www/html
ErrorDocument ErrorDocument directive allows you to specify a document or a message to be displayed as a response to a particular error. It takes the following form:
ErrorDocumenterror-codeaction
error-code has to be a valid code such as 403 (Forbidden), 404 (Not Found), or 500 (Internal Server Error). The action can be either a URL (both local and external), or a message string enclosed in double quotes (that is, ").
ErrorDocument 403 "Access Denied" ErrorDocument 404 /404-not_found.html
ErrorLog ErrorLog directive allows you to specify a file to which the server errors are logged. It takes the following form:
ErrorLog pathpath refers to a log file, and can be either absolute, or relative to the directory that is specified by the ServerRoot directive (that is, /etc/httpd/ by default). The default option is logs/error_log
ErrorLog logs/error_log
ExtendedStatus ExtendedStatus directive allows you to enable detailed server status information. It takes the following form:
ExtendedStatus optionoption has to be a valid keyword as described in Таблица 13.7, «Available ExtendedStatus options». The default option is Off.
| Option | Description |
|---|---|
On
| Enables generating the detailed server status. |
Off
| Disables generating the detailed server status. |
ExtendedStatus On
Group Group directive allows you to specify the group under which the httpd service will run. It takes the following form:
Group groupgroup has to be an existing UNIX group. The default option is apache.
Group is no longer supported inside <VirtualHost>, and has been replaced by the SuexecUserGroup directive.
Group apache
HeaderName HeaderName directive allows you to specify a file to be prepended to the beginning of the server-generated directory listing. It takes the following form:
HeaderName filenamefilename is a name of the file to look for in the requested directory. By default, the server looks for HEADER.html.
HeaderName HEADER.html
HostnameLookups HostnameLookups directive allows you to enable automatic resolving of IP addresses. It takes the following form:
HostnameLookups optionoption has to be a valid keyword as described in Таблица 13.8, «Available HostnameLookups options». To conserve resources on the server, the default option is Off.
| Option | Description |
|---|---|
On
| Enables resolving the IP address for each connection so that the hostname can be logged. However, this also adds a significant processing overhead. |
Double
| Enables performing the double-reverse DNS lookup. In comparison to the above option, this adds even more processing overhead. |
Off
| Disables resolving the IP address for each connection. |
HostnameLookups Off
Include Include directive allows you to include other configuration files. It takes the following form:
Include filenamefilename can be an absolute path, a path relative to the directory specified by the ServerRoot directive, or a wildcard expression. All configuration files from the /etc/httpd/conf.d/ directory are loaded by default.
Include conf.d/*.conf
IndexIgnore IndexIgnore directive allows you to specify a list of file names to be omitted from the server-generated directory listings. It takes the following form:
IndexIgnore filename…filename option can be either a full file name, or a wildcard expression.
IndexIgnore .??* *~ *# HEADER* README* RCS CVS *,v *,t
IndexOptions IndexOptions directive allows you to customize the behavior of server-generated directory listings. It takes the following form:
IndexOptions option…option has to be a valid keyword as described in Таблица 13.9, «Available directory listing options». The default options are Charset=UTF-8, FancyIndexing, HTMLTable, NameWidth=*, and VersionSort.
| Option | Description |
|---|---|
Charset=encoding
|
Specifies the character set of a generated web page. The encoding has to be a valid character set such as UTF-8 or ISO-8859-2.
|
Type=content-type
|
Specifies the media type of a generated web page. The content-type has to be a valid MIME type such as text/html or text/plain.
|
DescriptionWidth=value
|
Specifies the width of the description column. The value can be either a number of characters, or an asterisk (that is, *) to adjust the width automatically.
|
FancyIndexing
| Enables advanced features such as different icons for certain files or possibility to re-sort a directory listing by clicking on a column header. |
FolderFirst
| Enables listing directories first, always placing them above files. |
HTMLTable
| Enables the use of HTML tables for directory listings. |
IconsAreLinks
| Enables using the icons as links. |
IconHeight=value
|
Specifies an icon height. The value is a number of pixels.
|
IconWidth=value
|
Specifies an icon width. The value is a number of pixels.
|
IgnoreCase
| Enables sorting files and directories in a case-sensitive manner. |
IgnoreClient
| Disables accepting query variables from a client. |
NameWidth=value
|
Specifies the width of the file name column. The value can be either a number of characters, or an asterisk (that is, *) to adjust the width automatically.
|
ScanHTMLTitles
|
Enables parsing the file for a description (that is, the title element) in case it is not provided by the AddDescription directive.
|
ShowForbidden
| Enables listing the files with otherwise restricted access. |
SuppressColumnSorting
| Disables re-sorting a directory listing by clicking on a column header. |
SuppressDescription
| Disables reserving a space for file descriptions. |
SuppressHTMLPreamble
|
Disables the use of standard HTML preamble when a file specified by the HeaderName directive is present.
|
SuppressIcon
| Disables the use of icons in directory listings. |
SuppressLastModified
| Disables displaying the date of the last modification field in directory listings. |
SuppressRules
| Disables the use of horizontal lines in directory listings. |
SuppressSize
| Disables displaying the file size field in directory listings. |
TrackModified
|
Enables returning the Last-Modified and ETag values in the HTTP header.
|
VersionSort
| Enables sorting files that contain a version number in the expected manner. |
XHTML
| Enables the use of XHTML 1.0 instead of the default HTML 3.2. |
IndexOptions FancyIndexing VersionSort NameWidth=* HTMLTable Charset=UTF-8
KeepAlive KeepAlive directive allows you to enable persistent connections. It takes the following form:
KeepAlive optionoption has to be a valid keyword as described in Таблица 13.10, «Available KeepAlive options». The default option is Off.
| Option | Description |
|---|---|
On
| Enables the persistent connections. In this case, the server will accept more than one request per connection. |
Off
| Disables the keep-alive connections. |
KeepAliveTimeout to a low number, and monitor the /var/log/httpd/logs/error_log log file carefully.
KeepAlive Off
KeepAliveTimeout KeepAliveTimeout directive allows you to specify the amount of time to wait for another request before closing the connection. It takes the following form:
KeepAliveTimeout timetime is specified in seconds. The default option is 15.
KeepAliveTimeout 15
LanguagePriority LanguagePriority directive allows you to customize the precedence of languages. It takes the following form:
LanguagePriority language…language has to be a valid MIME language such as cs, en, or fr.
LanguagePriority sk cs en
Listen Listen directive allows you to specify IP addresses or ports to listen to. It takes the following form:
Listen [ip-address:]port[protocol]
ip-address is optional and unless supplied, the server will accept incoming requests on a given port from all IP addresses. Since the protocol is determined automatically from the port number, it can be usually omitted. The default option is to listen to port 80.
httpd service.
Listen 80
LoadModule LoadModule directive allows you to load a Dynamic Shared Object (DSO) module. It takes the following form:
LoadModulenamepath
name has to be a valid identifier of the required module. The path refers to an existing module file, and must be relative to the directory in which the libraries are placed (that is, /usr/lib/httpd/ on 32-bit and /usr/lib64/httpd/ on 64-bit systems by default).
LoadModule php5_module modules/libphp5.so
LogFormat LogFormat directive allows you to specify a log file format. It takes the following form:
LogFormatformatname
format is a string consisting of options as described in Таблица 13.11, «Common LogFormat options». The name can be used instead of the format string in the CustomLog directive.
| Option | Description |
|---|---|
%b
| Represents the size of the response in bytes. |
%h
| Represents the IP address or hostname of a remote client. |
%l
|
Represents the remote log name if supplied. If not, a hyphen (that is, -) is used instead.
|
%r
| Represents the first line of the request string as it came from the browser or client. |
%s
| Represents the status code. |
%t
| Represents the date and time of the request. |
%u
|
If the authentication is required, it represents the remote user. If not, a hyphen (that is, -) is used instead.
|
%{
|
Represents the content of the HTTP header field. The common options include %{Referer} (the URL of the web page that referred the client to the server) and %{User-Agent} (the type of the web browser making the request).
|
LogFormat "%h %l %u %t \"%r\" %>s %b" common
LogLevel LogLevel directive allows you to customize the verbosity level of the error log. It takes the following form:
LogLevel optionoption has to be a valid keyword as described in Таблица 13.12, «Available LogLevel options». The default option is warn.
| Option | Description |
|---|---|
emerg
| Only the emergency situations when the server cannot perform its work are logged. |
alert
| All situations when an immediate action is required are logged. |
crit
| All critical conditions are logged. |
error
| All error messages are logged. |
warn
| All warning messages are logged. |
notice
| Even normal, but still significant situations are logged. |
info
| Various informational messages are logged. |
debug
| Various debugging messages are logged. |
LogLevel warn
MaxKeepAliveRequests MaxKeepAliveRequests directive allows you to specify the maximum number of requests for a persistent connection. It takes the following form:
MaxKeepAliveRequests numbernumber can improve the performance of the server. Note that using 0 allows unlimited number of requests. The default option is 100.
MaxKeepAliveRequests 100
NameVirtualHost NameVirtualHost directive allows you to specify the IP address and port number for a name-based virtual host. It takes the following form:
NameVirtualHostip-address[:port]
ip-address can be either a full IP address, or an asterisk (that is, *) representing all interfaces. Note that IPv6 addresses have to be enclosed in square brackets (that is, [ and ]). The port is optional.
NameVirtualHost *:80
Options Options directive allows you to specify which server features are available in a particular directory. It takes the following form:
Options option…option has to be a valid keyword as described in Таблица 13.13, «Available server features».
| Option | Description |
|---|---|
ExecCGI
| Enables the execution of CGI scripts. |
FollowSymLinks
| Enables following symbolic links in the directory. |
Includes
| Enables server-side includes. |
IncludesNOEXEC
| Enables server-side includes, but does not allow the execution of commands. |
Indexes
| Enables server-generated directory listings. |
MultiViews
| Enables content-negotiated «MultiViews». |
SymLinksIfOwnerMatch
| Enables following symbolic links in the directory when both the link and the target file have the same owner. |
All
|
Enables all of the features above with the exception of MultiViews.
|
None
| Disables all of the features above. |
Options Indexes FollowSymLinks
Order Order directive allows you to specify the order in which the Allow and Deny directives are evaluated. It takes the following form:
Order optionoption has to be a valid keyword as described in Таблица 13.14, «Available Order options». The default option is allow,deny.
| Option | Description |
|---|---|
allow,deny
|
Allow directives are evaluated first.
|
deny,allow
|
Deny directives are evaluated first.
|
Order allow,deny
PidFile PidFile directive allows you to specify a file to which the process ID (PID) of the server is stored. It takes the following form:
PidFile pathpath refers to a pid file, and can be either absolute, or relative to the directory that is specified by the ServerRoot directive (that is, /etc/httpd/ by default). The default option is run/httpd.pid.
PidFile run/httpd.pid
ProxyRequests ProxyRequests directive allows you to enable forward proxy requests. It takes the following form:
ProxyRequests optionoption has to be a valid keyword as described in Таблица 13.15, «Available ProxyRequests options». The default option is Off.
| Option | Description |
|---|---|
On
| Enables forward proxy requests. |
Off
| Disables forward proxy requests. |
ProxyRequests On
ReadmeName ReadmeName directive allows you to specify a file to be appended to the end of the server-generated directory listing. It takes the following form:
ReadmeName filenamefilename is a name of the file to look for in the requested directory. By default, the server looks for README.html.
ReadmeName README.html
Redirect Redirect directive allows you to redirect a client to another URL. It takes the following form:
Redirect [status]pathurl
status is optional, and if provided, it has to be a valid keyword as described in Таблица 13.16, «Available status options». The path refers to the old location, and must be relative to the directory specified by the DocumentRoot directive (for example, /docs). The url refers to the current location of the content (for example, http://docs.example.com).
| Status | Description |
|---|---|
permanent
|
Indicates that the requested resource has been moved permanently. The 301 (Moved Permanently) status code is returned to a client.
|
temp
|
Indicates that the requested resource has been moved only temporarily. The 302 (Found) status code is returned to a client.
|
seeother
|
Indicates that the requested resource has been replaced. The 303 (See Other) status code is returned to a client.
|
gone
|
Indicates that the requested resource has been removed permanently. The 410 (Gone) status is returned to a client.
|
mod_rewrite module that is part of the Apache HTTP Server installation.
Redirect permanent /docs http://docs.example.com
ScriptAlias ScriptAlias directive allows you to specify the location of CGI scripts. It takes the following form:
ScriptAliasurl-pathreal-path
url-path must be relative to the directory specified by the DocumentRoot directive (for example, /cgi-bin/). The real-path is a full path to a file or directory in the local file system.
Directory tag with additional permissions to access the target directory. By default, the /cgi-bin/ alias is created so that the scripts located in the /var/www/cgi-bin/ are accessible.
ScriptAlias directive is used for security reasons to prevent CGI scripts from being viewed as ordinary text documents.
ScriptAlias /cgi-bin/ /var/www/cgi-bin/ <Directory "/var/www/cgi-bin"> AllowOverride None Options None Order allow,deny Allow from all </Directory>
ServerAdmin ServerAdmin directive allows you to specify the email address of the server administrator to be displayed in server-generated web pages. It takes the following form:
ServerAdmin emailroot@localhost.
webmaster@hostname, where hostname is the address of the server. Once set, alias webmaster to the person responsible for the web server in /etc/aliases, and as superuser, run the newaliases command.
ServerAdmin webmaster@penguin.example.com
ServerName ServerName directive allows you to specify the hostname and the port number of a web server. It takes the following form:
ServerNamehostname[:port]
hostname has to be a fully qualified domain name (FQDN) of the server. The port is optional, but when supplied, it has to match the number specified by the Listen directive.
/etc/hosts file.
ServerName penguin.example.com:80
ServerRoot ServerRoot directive allows you to specify the directory in which the server operates. It takes the following form:
ServerRoot directorydirectory must be a full path to an existing directory in the local file system. The default option is /etc/httpd/.
ServerRoot /etc/httpd
ServerSignature ServerSignature directive allows you to enable displaying information about the server on server-generated documents. It takes the following form:
ServerSignature optionoption has to be a valid keyword as described in Таблица 13.17, «Available ServerSignature options». The default option is On.
| Option | Description |
|---|---|
On
| Enables appending the server name and version to server-generated pages. |
Off
| Disables appending the server name and version to server-generated pages. |
EMail
|
Enables appending the server name, version, and the email address of the system administrator as specified by the ServerAdmin directive to server-generated pages.
|
ServerSignature On
ServerTokens ServerTokens directive allows you to customize what information are included in the Server response header. It takes the following form:
ServerTokens optionoption has to be a valid keyword as described in Таблица 13.18, «Available ServerTokens options». The default option is OS.
| Option | Description |
|---|---|
Prod
|
Includes the product name only (that is, Apache).
|
Major
|
Includes the product name and the major version of the server (for example, 2).
|
Minor
|
Includes the product name and the minor version of the server (for example, 2.2).
|
Min
|
Includes the product name and the minimal version of the server (for example, 2.2.15).
|
OS
|
Includes the product name, the minimal version of the server, and the type of the operating system it is running on (for example, Red Hat).
|
Full
| Includes all the information above along with the list of loaded modules. |
ServerTokens Prod
SuexecUserGroup SuexecUserGroup directive allows you to specify the user and group under which the CGI scripts will be run. It takes the following form:
SuexecUserGroupusergroup
user has to be an existing user, and the group must be a valid UNIX group.
root privileges. Note that in <VirtualHost>, SuexecUserGroup replaces the User and Group directives.
SuexecUserGroup apache apache
Timeout Timeout directive allows you to specify the amount of time to wait for an event before closing a connection. It takes the following form:
Timeout timetime is specified in seconds. The default option is 60.
Timeout 60
TypesConfig TypesConfig allows you to specify the location of the MIME types configuration file. It takes the following form:
TypesConfig pathpath refers to an existing MIME types configuration file, and can be either absolute, or relative to the directory that is specified by the ServerRoot directive (that is, /etc/httpd/ by default). The default option is /etc/mime.types.
/etc/mime.types, the recommended way to add MIME type mapping to the Apache HTTP Server is to use the AddType directive.
TypesConfig /etc/mime.types
UseCanonicalName UseCanonicalName allows you to specify the way the server refers to itself. It takes the following form:
UseCanonicalName optionoption has to be a valid keyword as described in Таблица 13.19, «Available UseCanonicalName options». The default option is Off.
| Option | Description |
|---|---|
On
|
Enables the use of the name that is specified by the ServerName directive.
|
Off
|
Disables the use of the name that is specified by the ServerName directive. The hostname and port number provided by the requesting client are used instead.
|
DNS
|
Disables the use of the name that is specified by the ServerName directive. The hostname determined by a reverse DNS lookup is used instead.
|
UseCanonicalName Off
User User directive allows you to specify the user under which the httpd service will run. It takes the following form:
User useruser has to be an existing UNIX user. The default option is apache.
httpd service should not be run with root privileges. Note that User is no longer supported inside <VirtualHost>, and has been replaced by the SuexecUserGroup directive.
User apache
UserDir UserDir directive allows you to enable serving content from users' home directories. It takes the following form:
UserDir optionoption can be either a name of the directory to look for in user's home directory (typically public_html), or a valid keyword as described in Таблица 13.20, «Available UserDir options». The default option is disabled.
| Option | Description |
|---|---|
enabled user…
|
Enables serving content from home directories of given users.
|
disabled [user…]
|
Disables serving content from home directories, either for all users, or, if a space separated list of users is supplied, for given users only.
|
UserDir directive. For example, to allow access to public_html/ in the home directory of user joe, type the following at a shell prompt as root:
~]#chmod a+x /home/joe/~]#chmod a+rx /home/joe/public_html/
UserDir public_html
/etc/httpd/conf.d/ssl.conf:
SetEnvIf SetEnvIf directive allows you to set environment variables based on the headers of incoming connections. It takes the following form:
SetEnvIfoptionpattern[!]variable[=value]…
option can be either a HTTP header field, a previously defined environment variable name, or a valid keyword as described in Таблица 13.21, «Available SetEnvIf options». The pattern is a regular expression. The variable is an environment variable that is set when the option matches the pattern. If the optional exclamation mark (that is, !) is present, the variable is removed instead of being set.
| Option | Description |
|---|---|
Remote_Host
| Refers to the client's hostname. |
Remote_Addr
| Refers to the client's IP address. |
Server_Addr
| Refers to the server's IP address. |
Request_Method
|
Refers to the request method (for example, GET).
|
Request_Protocol
|
Refers to the protocol name and version (for example, HTTP/1.1).
|
Request_URI
| Refers to the requested resource. |
SetEnvIf directive is used to disable HTTP keepalives, and to allow SSL to close the connection without a closing notification from the client browser. This is necessary for certain web browsers that do not reliably shut down the SSL connection.
SetEnvIf User-Agent ".*MSIE.*" \
nokeepalive ssl-unclean-shutdown \
downgrade-1.0 force-response-1.0/etc/httpd/conf.d/ssl.conf file to be present, the mod_ssl needs to be installed. Refer to Раздел 13.1.8, «Setting Up an SSL Server» for more information on how to install and configure an SSL server.
IfModule. By default, the server-pool is defined for both the prefork and worker MPMs.
/etc/httpd/conf/httpd.conf:
MaxClients MaxClients directive allows you to specify the maximum number of simultaneously connected clients to process at one time. It takes the following form:
MaxClients numbernumber can improve the performance of the server, although it is not recommended to exceed 256 when using the prefork MPM.
MaxClients 256
MaxRequestsPerChild MaxRequestsPerChild directive allows you to specify the maximum number of request a child process can serve before it dies. It takes the following form:
MaxRequestsPerChild numbernumber to 0 allows unlimited number of requests.
MaxRequestsPerChild directive is used to prevent long-lived processes from causing memory leaks.
MaxRequestsPerChild 4000
MaxSpareServers MaxSpareServers directive allows you to specify the maximum number of spare child processes. It takes the following form:
MaxSpareServers numberprefork MPM only.
MaxSpareServers 20
MaxSpareThreads MaxSpareThreads directive allows you to specify the maximum number of spare server threads. It takes the following form:
MaxSpareThreads numbernumber must be greater than or equal to the sum of MinSpareThreads and ThreadsPerChild. This directive is used by the worker MPM only.
MaxSpareThreads 75
MinSpareServers MinSpareServers directive allows you to specify the minimum number of spare child processes. It takes the following form:
MinSpareServers numbernumber can create a heavy processing load on the server. This directive is used by the prefork MPM only.
MinSpareServers 5
MinSpareThreads MinSpareThreads directive allows you to specify the minimum number of spare server threads. It takes the following form:
MinSpareThreads numberworker MPM only.
MinSpareThreads 75
StartServers StartServers directive allows you to specify the number of child processes to create when the service is started. It takes the following form:
StartServers numberStartServers 8
ThreadsPerChild ThreadsPerChild directive allows you to specify the number of threads a child process can create. It takes the following form:
ThreadsPerChild numberworker MPM only.
ThreadsPerChild 25
httpd service is distributed along with a number of Dynamic Shared Objects (DSOs), which can be dynamically loaded or unloaded at runtime as necessary. By default, these modules are located in /usr/lib/httpd/modules/ on 32-bit and in /usr/lib64/httpd/modules/ on 64-bit systems.
LoadModule directive as described in Раздел 13.1.5.1, «Common httpd.conf Directives». Note that modules provided by a separate package often have their own configuration file in the /etc/httpd/conf.d/ directory.
LoadModule ssl_module modules/mod_ssl.so
httpd service.
root:
yum install httpd-develapxs) utility required to compile a module.
apxs -i -a -c module_name.c/etc/httpd/conf/httpd.conf as an example, remove the hash sign (that is, #) from the beginning of each line, and customize the options according to your requirements as shown in Пример 13.80, «Sample virtual host configuration».
NameVirtualHost penguin.example.com:80
<VirtualHost penguin.example.com:80>
ServerAdmin webmaster@penguin.example.com
DocumentRoot /www/docs/penguin.example.com
ServerName penguin.example.com:80
ErrorLog logs/penguin.example.com-error_log
CustomLog logs/penguin.example.com-access_log common
</VirtualHost>ServerName must be a valid DNS name assigned to the machine. The <VirtualHost> container is highly customizable, and accepts most of the directives available within the main server configuration. Directives that are not supported within this container include User and Group, which were replaced by SuexecUserGroup.
Listen directive in the global settings section of the /etc/httpd/conf/httpd.conf file accordingly.
httpd service.
mod_ssl, a module that uses the OpenSSL toolkit to provide the SSL/TLS support, is commonly referred to as the SSL server.
mod_ssl prevents any inspection or modification of the transmitted content. This section provides basic information on how to enable this module in the Apache HTTP Server configuration, and guides you through the process of generating private keys and self-signed certificates.
| Web Browser | Link |
|---|---|
| Mozilla Firefox | Mozilla root CA list. |
| Opera | The Opera Rootstore. |
| Internet Explorer | Windows root certificate program members. |
mod_ssl module) and openssl (the OpenSSL toolkit) packages installed. To do so, type the following at a shell prompt as root:
yum install mod_ssl opensslmod_ssl configuration file at /etc/httpd/conf.d/ssl.conf, which is included in the main Apache HTTP Server configuration file by default. For the module to be loaded, restart the httpd service as described in Раздел 13.1.4.3, «Restarting the Service».
/etc/pki/tls/private/ and /etc/pki/tls/certs/ directories respectively. You can do so by running the following commands as root:
mvkey_file.key/etc/pki/tls/private/hostname.keymvcertificate.crt/etc/pki/tls/certs/hostname.crt
/etc/httpd/conf.d/ssl.conf configuration file:
SSLCertificateFile /etc/pki/tls/certs/hostname.crt SSLCertificateKeyFile /etc/pki/tls/private/hostname.key
httpd service as described in Раздел 13.1.4.3, «Restarting the Service».
~]#mv /etc/httpd/conf/httpsd.key /etc/pki/tls/private/penguin.example.com.key~]#mv /etc/httpd/conf/httpsd.crt /etc/pki/tls/certs/penguin.example.com.crt
root, you can install it by typing the following at a shell prompt:
yum install crypto-utilsroot, use the following command instead of genkey:
openssl req -x509 -new -set_serial number -key hostname.key -out hostname.crtroot:
rm /etc/pki/tls/private/hostname.keyroot, run the genkey command followed by the appropriate hostname (for example, penguin.example.com):
genkeyhostname
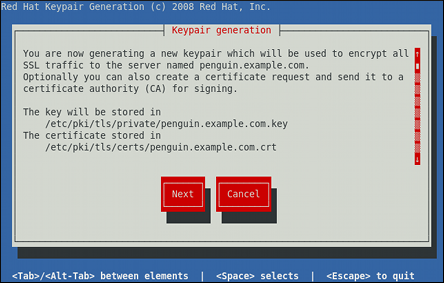
1024 bits.
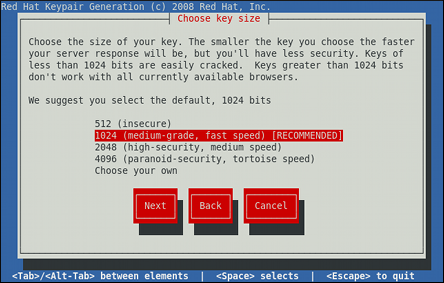
[*]) or disable ([ ]) the encryption of the private key.
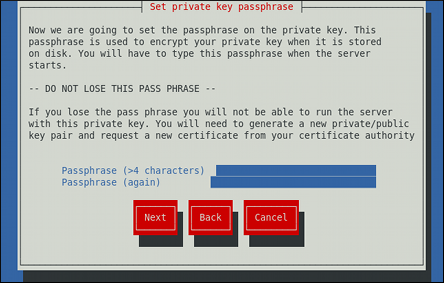
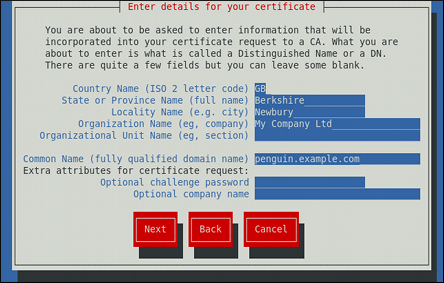
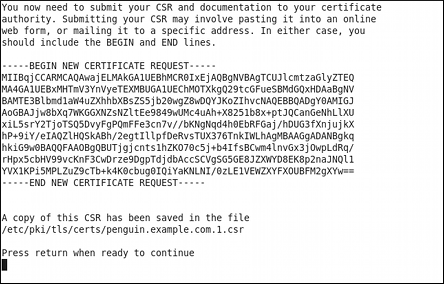
/etc/httpd/conf.d/ssl.conf configuration file:
SSLCertificateFile /etc/pki/tls/certs/hostname.crt SSLCertificateKeyFile /etc/pki/tls/private/hostname.key
httpd service as described in Раздел 13.1.4.3, «Restarting the Service», so that the updated configuration is loaded.
man httpdhttpd service containing the complete list of its command line options.
man genkeygenkey containing the full documentation on its usage.
dovecot package is installed on your system by running, as root:
yum install dovecotPOP server, email messages are downloaded by email client applications. By default, most POP email clients are automatically configured to delete the message on the email server after it has been successfully transferred, however this setting usually can be changed.
POP is fully compatible with important Internet messaging standards, such as Multipurpose Internet Mail Extensions (MIME), which allow for email attachments.
POP works best for users who have one system on which to read email. It also works well for users who do not have a persistent connection to the Internet or the network containing the mail server. Unfortunately for those with slow network connections, POP requires client programs upon authentication to download the entire content of each message. This can take a long time if any messages have large attachments.
POP protocol is POP3.
POP protocol variants:
POP3 with MDS (Monash Directory Service) authentication. An encoded hash of the user's password is sent from the email client to the server rather then sending an unencrypted password.
POP3 with Kerberos authentication.
POP3 with RPOP authentication. This uses a per-user ID, similar to a password, to authenticate POP requests. However, this ID is not encrypted, so RPOP is no more secure than standard POP.
pop3s service, or by using the /usr/sbin/stunnel application. For more information on securing email communication, refer to Раздел 14.5.1, «Securing Communication».
IMAP server under Fedora is Dovecot and is provided by the dovecot package. Refer to Раздел 14.1.2.1, «POP» for information on how to install Dovecot.
IMAP mail server, email messages remain on the server where users can read or delete them. IMAP also allows client applications to create, rename, or delete mail directories on the server to organize and store email.
IMAP is particularly useful for users who access their email using multiple machines. The protocol is also convenient for users connecting to the mail server via a slow connection, because only the email header information is downloaded for messages until opened, saving bandwidth. The user also has the ability to delete messages without viewing or downloading them.
IMAP client applications are capable of caching copies of messages locally, so the user can browse previously read messages when not directly connected to the IMAP server.
IMAP, like POP, is fully compatible with important Internet messaging standards, such as MIME, which allow for email attachments.
SSL encryption for client authentication and data transfer sessions. This can be enabled by using the imaps service, or by using the /usr/sbin/stunnel program. For more information on securing email communication, refer to Раздел 14.5.1, «Securing Communication».
imap-login and pop3-login processes which implement the IMAP and POP3 protocols are spawned by the master dovecot daemon included in the dovecot package. The use of IMAP and POP is configured through the /etc/dovecot/dovecot.conf configuration file; by default dovecot runs IMAP and POP3 together with their secure versions using SSL. To configure dovecot to use POP, complete the following steps:
/etc/dovecot/dovecot.conf configuration file to make sure the protocols variable is uncommented (remove the hash sign (#) at the beginning of the line) and contains the pop3 argument. For example:
protocols = imap imaps pop3 pop3s
protocols variable is left commented out, dovecot will use the default values specified for this variable.
root:
systemctl restart dovecot.servicesystemctl enable dovecot.servicedovecot only reports that it started the IMAP server, but also starts the POP3 server.
SMTP, both IMAP and POP3 require connecting clients to authenticate using a username and password. By default, passwords for both protocols are passed over the network unencrypted.
SSL on dovecot:
/etc/pki/dovecot/dovecot-openssl.conf configuration file as you prefer. However, in a typical installation, this file does not require modification.
/etc/pki/dovecot/certs/dovecot.pem and /etc/pki/dovecot/private/dovecot.pem.
/usr/libexec/dovecot/mkcert.sh script which creates the dovecot self signed certificates. These certificates are copied in the /etc/pki/dovecot/certs and /etc/pki/dovecot/private directories. To implement the changes, restart dovecot by typing the following at a shell prompt as root:
systemctl restart dovecot.servicedovecot can be found online at http://www.dovecot.org.
SMTP. A message may involve several MTAs as it moves to its intended destination.
mail or Procmail.
POP or IMAP protocols, setting up mailboxes to store messages, and sending outbound messages to an MTA.
root, you can either uninstall Postfix or use the following command to switch to Sendmail:
alternatives --config mtasystemctl enable|disable service.service/usr/sbin/postfix. This daemon launches all related processes needed to handle mail delivery.
/etc/postfix/ directory. The following is a list of the more commonly used files:
access — Used for access control, this file specifies which hosts are allowed to connect to Postfix.
main.cf — The global Postfix configuration file. The majority of configuration options are specified in this file.
master.cf — Specifies how Postfix interacts with various processes to accomplish mail delivery.
transport — Maps email addresses to relay hosts.
aliases file can be found in the /etc/ directory. This file is shared between Postfix and Sendmail. It is a configurable list required by the mail protocol that describes user ID aliases.
/etc/postfix/main.cf file does not allow Postfix to accept network connections from a host other than the local computer. For instructions on configuring Postfix as a server for other clients, refer to Раздел 14.3.1.2, «Basic Postfix Configuration».
postfix service after changing any options in the configuration files under the /etc/postfix directory in order for those changes to take effect. To do so, run the following command as root:
systemctl restart postfix.serviceroot to enable mail delivery for other hosts on the network:
/etc/postfix/main.cf file with a text editor, such as vi.
mydomain line by removing the hash sign (#), and replace domain.tld with the domain the mail server is servicing, such as example.com.
myorigin = $mydomain line.
myhostname line, and replace host.domain.tld with the hostname for the machine.
mydestination = $myhostname, localhost.$mydomain line.
mynetworks line, and replace 168.100.189.0/28 with a valid network setting for hosts that can connect to the server.
inet_interfaces = all line.
inet_interfaces = localhost line.
postfix service.
/etc/postfix/main.cf configuration file. Additional resources including information about Postfix configuration, SpamAssassin integration, or detailed descriptions of the /etc/postfix/main.cf parameters are available online at http://www.postfix.org/.
LDAP directory as a source for various lookup tables (e.g.: aliases, virtual, canonical, etc.). This allows LDAP to store hierarchical user information and Postfix to only be given the result of LDAP queries when needed. By not storing this information locally, administrators can easily maintain it.
LDAP to look up the /etc/aliases file. Make sure your /etc/postfix/main.cf contains the following:
alias_maps = hash:/etc/aliases, ldap:/etc/postfix/ldap-aliases.cf
/etc/postfix/ldap-aliases.cf file if you do not have one created already and make sure it contains the following:
server_host =ldap.example.comsearch_base = dc=example, dc=com
ldap.example.com, example, and com are parameters that need to be replaced with specification of an existing available LDAP server.
/etc/postfix/ldap-aliases.cf file can specify various parameters, including parameters that enable LDAP SSL and STARTTLS. For more information, refer to the ldap_table(5) man page.
LDAP, refer to Раздел 15.1, «OpenLDAP».
SMTP protocol. However, Sendmail is highly configurable, allowing control over almost every aspect of how email is handled, including the protocol used. Many system administrators elect to use Sendmail as their MTA due to its power and scalability.
POP or IMAP, to download their messages to their local machine. Or, they may prefer a Web interface to gain access to their mailbox. These other applications can work in conjunction with Sendmail, but they actually exist for different reasons and can operate separately from one another.
root:
yum install sendmailroot:
yum install sendmail-cf/usr/sbin/sendmail.
/etc/mail/sendmail.cf. Avoid editing the sendmail.cf file directly. To make configuration changes to Sendmail, edit the /etc/mail/sendmail.mc file, back up the original /etc/mail/sendmail.cf, and use the following alternatives to generate a new configuration file:
/etc/mail/ (~]# make all -C /etc/mail/) to create a new /etc/mail/sendmail.cf configuration file. All other generated files in /etc/mail (db files) will be regenerated if needed. The old makemap commands are still usable. The make command will automatically be used by systemctl start|restart|reload sendmail.service.
m4 macro processor to create a new /etc/mail/sendmail.cf. The m4 macro processor is not installed by default. Before using it to create /etc/mail/sendmail.cf, install the m4 package as root:
yum install m4/etc/mail/ directory including:
access — Specifies which systems can use Sendmail for outbound email.
domaintable — Specifies domain name mapping.
local-host-names — Specifies aliases for the host.
mailertable — Specifies instructions that override routing for particular domains.
virtusertable — Specifies a domain-specific form of aliasing, allowing multiple virtual domains to be hosted on one machine.
/etc/mail/, such as access, domaintable, mailertable and virtusertable, must actually store their information in database files before Sendmail can use any configuration changes. To include any changes made to these configurations in their database files, run the following command, as root:
makemap hash /etc/mail/name < /etc/mail/namename represents the name of the configuration file to be updated. You may also restart the sendmail service for the changes to take effect by running:
systemctl restart sendmail.serviceexample.com domain delivered to bob@other-example.com
, add the following line to the virtusertable file:
@example.com bob@other-example.comvirtusertable.db file must be updated:
makemap hash /etc/mail/virtusertable < /etc/mail/virtusertablevirtusertable.db file containing the new configuration.
/etc/mail/sendmail.cf file.
sendmail.cf file, it is a good idea to create a backup copy.
/etc/mail/sendmail.mc file as root. Once you are finished, restart the sendmail service and, if the m4 package is installed, the m4 macro processor will automatically generate a new sendmail.cf configuration file:
systemctl restart sendmail.servicesendmail.cf file does not allow Sendmail to accept network connections from any host other than the local computer. To configure Sendmail as a server for other clients, edit the /etc/mail/sendmail.mc file, and either change the address specified in the Addr= option of the DAEMON_OPTIONS directive from 127.0.0.1 to the IP address of an active network device or comment out the DAEMON_OPTIONS directive all together by placing dnl at the beginning of the line. When finished, regenerate /etc/mail/sendmail.cf by restarting the service:
systemctl restart sendmail.serviceSMTP-only sites. However, it does not work for UUCP (UNIX-to-UNIX Copy Protocol) sites. If using UUCP mail transfers, the /etc/mail/sendmail.mc file must be reconfigured and a new /etc/mail/sendmail.cf file must be generated.
/usr/share/sendmail-cf/README file before editing any files in the directories under the /usr/share/sendmail-cf directory, as they can affect the future configuration of the /etc/mail/sendmail.cf file.
mail.example.com that handles all of their email and assigns a consistent return address to all outgoing mail.
user@example.com instead of user@host.example.com.
/etc/mail/sendmail.mc:
FEATURE(always_add_domain)dnl FEATURE(`masquerade_entire_domain')dnl FEATURE(`masquerade_envelope')dnl FEATURE(`allmasquerade')dnl MASQUERADE_AS(`bigcorp.com.')dnl MASQUERADE_DOMAIN(`bigcorp.com.')dnl MASQUERADE_AS(bigcorp.com)dnl
sendmail.cf using the m4 macro processor, this configuration makes all mail from inside the network appear as if it were sent from bigcorp.com.
SMTP messages, also called relaying, has been disabled by default since Sendmail version 8.9. Before this change occurred, Sendmail directed the mail host (x.edu) to accept messages from one party (y.com) and sent them to a different party (z.net). Now, however, Sendmail must be configured to permit any domain to relay mail through the server. To configure relay domains, edit the /etc/mail/relay-domains file and restart Sendmail:
systemctl restart sendmail.service/etc/mail/access file can be used to prevent connections from unwanted hosts. The following example illustrates how this file can be used to both block and specifically allow access to the Sendmail server:
badspammer.com ERROR:550 "Go away and do not spam us" tux.badspammer.com OK 10.0 RELAY
badspammer.com is blocked with a 550 RFC-821 compliant error code, with a message sent back to the spammer. Email sent from the tux.badspammer.com sub-domain, is accepted. The last line shows that any email sent from the 10.0.*.* network can be relayed through the mail server.
/etc/mail/access.db file is a database, use the makemap command to update any changes. Do this using the following command as root:
makemap hash /etc/mail/access < /etc/mail/accessSMTP servers store information about an email's journey in the message header. As the message travels from one MTA to another, each puts in a Received header above all the other Received headers. It is important to note that this information may be altered by spammers.
/usr/share/sendmail-cf/README for more information and examples.
LDAP is a very quick and powerful way to find specific information about a particular user from a much larger group. For example, an LDAP server can be used to look up a particular email address from a common corporate directory by the user's last name. In this kind of implementation, LDAP is largely separate from Sendmail, with LDAP storing the hierarchical user information and Sendmail only being given the result of LDAP queries in pre-addressed email messages.
LDAP, where it uses LDAP to replace separately maintained files, such as /etc/aliases and /etc/mail/virtusertables, on different mail servers that work together to support a medium- to enterprise-level organization. In short, LDAP abstracts the mail routing level from Sendmail and its separate configuration files to a powerful LDAP cluster that can be leveraged by many different applications.
LDAP. To extend the Sendmail server using LDAP, first get an LDAP server, such as OpenLDAP, running and properly configured. Then edit the /etc/mail/sendmail.mc to include the following:
LDAPROUTE_DOMAIN('yourdomain.com')dnl
FEATURE('ldap_routing')dnlLDAP. The configuration can differ greatly from this depending on the implementation of LDAP, especially when configuring several Sendmail machines to use a common LDAP server.
/usr/share/sendmail-cf/README for detailed LDAP routing configuration instructions and examples.
/etc/mail/sendmail.cf file by running the m4 macro processor and again restarting Sendmail. Refer to Раздел 14.3.2.3, «Common Sendmail Configuration Changes» for instructions.
LDAP, refer to Раздел 15.1, «OpenLDAP».
POP3 and IMAP. It can even forward email messages to an SMTP server, if necessary.
root:
yum install fetchmail.fetchmailrc file in the user's home directory. If it does not already exist, create the .fetchmailrc file in your home directory
.fetchmailrc file, Fetchmail checks for email on a remote server and downloads it. It then delivers it to port 25 on the local machine, using the local MTA to place the email in the correct user's spool file. If Procmail is available, it is launched to filter the email and place it in a mailbox so that it can be read by an MUA.
.fetchmailrc file is much easier. Place any desired configuration options in the .fetchmailrc file for those options to be used each time the fetchmail command is issued. It is possible to override these at the time Fetchmail is run by specifying that option on the command line.
.fetchmailrc file contains three classes of configuration options:
.fetchmailrc file, followed by one or more server options, each of which designate a different email server that Fetchmail should check. User options follow server options for each user account checking that email server. Like server options, multiple user options may be specified for use with a particular server as well as to check multiple email accounts on the same server.
.fetchmailrc file by the use of a special option verb, poll or skip, that precedes any of the server information. The poll action tells Fetchmail to use this server option when it is run, which checks for email using the specified user options. Any server options after a skip action, however, are not checked unless this server's hostname is specified when Fetchmail is invoked. The skip option is useful when testing configurations in the .fetchmailrc file because it only checks skipped servers when specifically invoked, and does not affect any currently working configurations.
.fetchmailrc file:
set postmaster "user1"
set bouncemail
poll pop.domain.com proto pop3
user 'user1' there with password 'secret' is user1 here
poll mail.domain2.com
user 'user5' there with password 'secret2' is user1 here
user 'user7' there with password 'secret3' is user1 herepostmaster option) and all email errors are sent to the postmaster instead of the sender (bouncemail option). The set action tells Fetchmail that this line contains a global option. Then, two email servers are specified, one set to check using POP3, the other for trying various protocols to find one that works. Two users are checked using the second server option, but all email found for any user is sent to user1's mail spool. This allows multiple mailboxes to be checked on multiple servers, while appearing in a single MUA inbox. Each user's specific information begins with the user action.
.fetchmailrc file. Omitting the with password 'password' section causes Fetchmail to ask for a password when it is launched.
fetchmail man page explains each option in detail, but the most common ones are listed in the following three sections.
set action.
daemon seconds — Specifies daemon-mode, where Fetchmail stays in the background. Replace seconds with the number of seconds Fetchmail is to wait before polling the server.
postmaster — Specifies a local user to send mail to in case of delivery problems.
syslog — Specifies the log file for errors and status messages. By default, this is /var/log/maillog.
.fetchmailrc after a poll or skip action.
auth auth-type — Replace auth-type with the type of authentication to be used. By default, password authentication is used, but some protocols support other types of authentication, including kerberos_v5, kerberos_v4, and ssh. If the any authentication type is used, Fetchmail first tries methods that do not require a password, then methods that mask the password, and finally attempts to send the password unencrypted to authenticate to the server.
interval number — Polls the specified server every number port port-number — Replace port-number with the port number. This value overrides the default port number for the specified protocol.
proto protocol — Replace protocol with the protocol, such as pop3 or imap, to use when checking for messages on the server.
timeout seconds — Replace seconds with the number of seconds of server inactivity after which Fetchmail gives up on a connection attempt. If this value is not set, a default of 300 seconds is assumed.
user option (defined below).
fetchall — Orders Fetchmail to download all messages in the queue, including messages that have already been viewed. By default, Fetchmail only pulls down new messages.
fetchlimit number — Replace number with the number of messages to be retrieved before stopping.
flush — Deletes all previously viewed messages in the queue before retrieving new messages.
limit max-number-bytes — Replace max-number-bytes with the maximum size in bytes that messages are allowed to be when retrieved by Fetchmail. This option is useful with slow network links, when a large message takes too long to download.
password 'password' — Replace password with the user's password.
preconnect "command" — Replace command with a command to be executed before retrieving messages for the user.
postconnect "command" — Replace command with a command to be executed after retrieving messages for the user.
ssl — Activates SSL encryption.
user "username" — Replace username with the username used by Fetchmail to retrieve messages. This option must precede all other user options.
fetchmail command mirror the .fetchmailrc configuration options. In this way, Fetchmail may be used with or without a configuration file. These options are not used on the command line by most users because it is easier to leave them in the .fetchmailrc file.
fetchmail command with other options for a particular purpose. It is possible to issue command options to temporarily override a .fetchmailrc setting that is causing an error, as any options specified at the command line override configuration file options.
fetchmail command can supply important information.
--configdump — Displays every possible option based on information from .fetchmailrc and Fetchmail defaults. No email is retrieved for any users when using this option.
-s — Executes Fetchmail in silent mode, preventing any messages, other than errors, from appearing after the fetchmail command.
-v — Executes Fetchmail in verbose mode, displaying every communication between Fetchmail and remote email servers.
-V — Displays detailed version information, lists its global options, and shows settings to be used with each user, including the email protocol and authentication method. No email is retrieved for any users when using this option.
.fetchmailrc file.
-a — Fetchmail downloads all messages from the remote email server, whether new or previously viewed. By default, Fetchmail only downloads new messages.
-k — Fetchmail leaves the messages on the remote email server after downloading them. This option overrides the default behavior of deleting messages after downloading them.
-l max-number-bytes — Fetchmail does not download any messages over a particular size and leaves them on the remote email server.
--quit — Quits the Fetchmail daemon process.
.fetchmailrc options can be found in the fetchmail man page.
/bin/mail command to send email containing log messages to the root user of the local system.
mail. Both of the applications are considered LDAs and both move email from the MTA's spool file into the user's mailbox. However, Procmail provides a robust filtering system.
mail command, consult its man page (man mail).
/etc/procmailrc or of a ~/.procmailrc file (also called an rc file) in the user's home directory invokes Procmail whenever an MTA receives a new message.
rc files exist in the /etc/ directory and no .procmailrc files exist in any user's home directory. Therefore, to use Procmail, each user must construct a .procmailrc file with specific environment variables and rules.
rc file. If a message matches a recipe, then the email is placed in a specified file, is deleted, or is otherwise processed.
/etc/procmailrc file and rc files in the /etc/procmailrcs directory for default, system-wide, Procmail environmental variables and recipes. Procmail then searches for a .procmailrc file in the user's home directory. Many users also create additional rc files for Procmail that are referred to within the .procmailrc file in their home directory.
~/.procmailrc file in the following format:
env-variable="value"
env-variable value DEFAULT — Sets the default mailbox where messages that do not match any recipes are placed.
DEFAULT value is the same as $ORGMAIL.
INCLUDERC — Specifies additional rc files containing more recipes for messages to be checked against. This breaks up the Procmail recipe lists into individual files that fulfill different roles, such as blocking spam and managing email lists, that can then be turned off or on by using comment characters in the user's ~/.procmailrc file.
.procmailrc file may look like this:
MAILDIR=$HOME/Msgs INCLUDERC=$MAILDIR/lists.rc INCLUDERC=$MAILDIR/spam.rc
INCLUDERC line with a hash sign (#).
LOCKSLEEP — Sets the amount of time, in seconds, between attempts by Procmail to use a particular lockfile. The default is 8 seconds.
LOCKTIMEOUT — Sets the amount of time, in seconds, that must pass after a lockfile was last modified before Procmail assumes that the lockfile is old and can be deleted. The default is 1024 seconds.
LOGFILE — The file to which any Procmail information or error messages are written.
MAILDIR — Sets the current working directory for Procmail. If set, all other Procmail paths are relative to this directory.
ORGMAIL — Specifies the original mailbox, or another place to put the messages if they cannot be placed in the default or recipe-required location.
/var/spool/mail/$LOGNAME is used.
SUSPEND — Sets the amount of time, in seconds, that Procmail pauses if a necessary resource, such as swap space, is not available.
SWITCHRC — Allows a user to specify an external file containing additional Procmail recipes, much like the INCLUDERC option, except that recipe checking is actually stopped on the referring configuration file and only the recipes on the SWITCHRC-specified file are used.
VERBOSE — Causes Procmail to log more information. This option is useful for debugging.
LOGNAME, which is the login name; HOME, which is the location of the home directory; and SHELL, which is the default shell.
procmailrc man page.
:0flags:lockfile-name*special-condition-charactercondition-1*special-condition-charactercondition-2*special-condition-charactercondition-Nspecial-action-characteraction-to-perform
flags lockfile-name *) can further control the condition.
action-to-perform{ }, that are performed on messages which match the recipe's conditions. Nesting blocks can be nested inside one another, providing greater control for identifying and performing actions on messages.
A — Specifies that this recipe is only used if the previous recipe without an A or a flag also matched this message.
a — Specifies that this recipe is only used if the previous recipe with an A or a flag also matched this message and was successfully completed.
B — Parses the body of the message and looks for matching conditions.
b — Uses the body in any resulting action, such as writing the message to a file or forwarding it. This is the default behavior.
c — Generates a carbon copy of the email. This is useful with delivering recipes, since the required action can be performed on the message and a copy of the message can continue being processed in the rc files.
D — Makes the egrep comparison case-sensitive. By default, the comparison process is not case-sensitive.
E — While similar to the A flag, the conditions in the recipe are only compared to the message if the immediately preceding the recipe without an E flag did not match. This is comparable to an else action.
e — The recipe is compared to the message only if the action specified in the immediately preceding recipe fails.
f — Uses the pipe as a filter.
H — Parses the header of the message and looks for matching conditions. This is the default behavior.
h — Uses the header in a resulting action. This is the default behavior.
w — Tells Procmail to wait for the specified filter or program to finish, and reports whether or not it was successful before considering the message filtered.
W — Is identical to w except that "Program failure" messages are suppressed.
procmailrc man page.
:) after any flags on a recipe's first line. This creates a local lockfile based on the destination file name plus whatever has been set in the LOCKEXT global environment variable.
*) at the beginning of a recipe's condition line:
! — In the condition line, this character inverts the condition, causing a match to occur only if the condition does not match the message.
< — Checks if the message is under a specified number of bytes.
> — Checks if the message is over a specified number of bytes.
! — In the action line, this character tells Procmail to forward the message to the specified email addresses.
$ — Refers to a variable set earlier in the rc file. This is often used to set a common mailbox that is referred to by various recipes.
| — Starts a specified program to process the message.
{ and } — Constructs a nesting block, used to contain additional recipes to apply to matching messages.
grep man page.
:0: new-mail.spool
LOCKEXT environment variable. No condition is specified, so every message matches this recipe and is placed in the single spool file called new-mail.spool, located within the directory specified by the MAILDIR environment variable. An MUA can then view messages in this file.
rc files to direct messages to a default location.
:0 * ^From: spammer@domain.com /dev/null
spammer@domain.com are sent to the /dev/null device, deleting them.
/dev/null for permanent deletion. If a recipe inadvertently catches unintended messages, and those messages disappear, it becomes difficult to troubleshoot the rule.
/dev/null.
:0: * ^(From|Cc|To).*tux-lug tuxlug
tux-lug@domain.com mailing list are placed in the tuxlug mailbox automatically for the MUA. Note that the condition in this example matches the message if it has the mailing list's email address on the From, Cc, or To lines.
root:
yum install spamassassin~/.procmailrc file:
INCLUDERC=/etc/mail/spamassassin/spamassassin-default.rc
/etc/mail/spamassassin/spamassassin-default.rc contains a simple Procmail rule that activates SpamAssassin for all incoming email. If an email is determined to be spam, it is tagged in the header as such and the title is prepended with the following pattern:
*****SPAM*****
:0 Hw * ^X-Spam-Status: Yes spam
spam.
spamd) and the client application (spamc). Configuring SpamAssassin this way, however, requires root access to the host.
spamd daemon, type the following command:
systemctl start spamassassin.servicesystemctl enable spamassassin.service~/.procmailrc file. For a system-wide configuration, place it in /etc/procmailrc:
INCLUDERC=/etc/mail/spamassassin/spamassassin-spamc.rc
mutt.
mutt offer SSL-encrypted email sessions.
POP and IMAP protocols pass authentication information unencrypted, it is possible for an attacker to gain access to user accounts by collecting usernames and passwords as they are passed over the network.
IMAP and POP have known port numbers (993 and 995, respectively) that the MUA uses to authenticate and download messages.
IMAP and POP users on the email server is a simple matter.
IMAP or POP, change to the /etc/pki/dovecot/ directory, edit the certificate parameters in the /etc/pki/dovecot/dovecot-openssl.conf configuration file as you prefer, and type the following commands, as root:
dovecot]#rm -f certs/dovecot.pem private/dovecot.pemdovecot]#/usr/libexec/dovecot/mkcert.sh
/etc/dovecot/conf.d/10-ssl.conf file:
ssl_cert = </etc/pki/dovecot/certs/dovecot.pem ssl_key = </etc/pki/dovecot/private/dovecot.pem
systemctl restart dovecot.service command to restart the dovecot daemon.
stunnel command can be used as an SSL encryption wrapper around the standard, non-secure connections to IMAP or POP services.
stunnel utility uses external OpenSSL libraries included with Fedora to provide strong cryptography and to protect the network connections. It is recommended to apply to a CA to obtain an SSL certificate, but it is also possible to create a self-signed certificate.
stunnel, first ensure the stunnel package is installed on your system by running, as root:
yum install stunnel/etc/pki/tls/certs/ directory, and type the following command:
certs]# make stunnel.pemstunnel configuration file, for example /etc/stunnel/mail.conf, with the following content:
cert = /etc/pki/tls/certs/stunnel.pem [pop3s] accept = 995 connect = 110 [imaps] accept = 993 connect = 143
stunnel with the created configuration file using the /usr/bin/stunnel /etc/stunnel/mail.conf command, it will be possible to use an IMAP or a POP email client and connect to the email server using SSL encryption.
stunnel, refer to the stunnel man page or the documents in the /usr/share/doc/stunnel-version-number / directory, where version-number is the version number of stunnel.
sendmail and sendmail-cf packages.
/usr/share/sendmail-cf/README — Contains information on the m4 macro processor, file locations for Sendmail, supported mailers, how to access enhanced features, and more.
sendmail and aliases man pages contain helpful information covering various Sendmail options and the proper configuration of the Sendmail /etc/mail/aliases file.
/usr/share/doc/postfix-version-number — Contains a large amount of information about ways to configure Postfix. Replace version-number with the version number of Postfix.
/usr/share/doc/fetchmail-version-number — Contains a full list of Fetchmail features in the FEATURES file and an introductory FAQ document. Replace version-number with the version number of Fetchmail.
/usr/share/doc/procmail-version-number — Contains a README file that provides an overview of Procmail, a FEATURES file that explores every program feature, and an FAQ file with answers to many common configuration questions. Replace version-number with the version number of Procmail.
procmail — Provides an overview of how Procmail works and the steps involved with filtering email.
procmailrc — Explains the rc file format used to construct recipes.
procmailex — Gives a number of useful, real-world examples of Procmail recipes.
procmailsc — Explains the weighted scoring technique used by Procmail to match a particular recipe to a message.
/usr/share/doc/spamassassin-version-number/ — Contains a large amount of information pertaining to SpamAssassin. Replace version-number with the version number of the spamassassin package.
.procmailrc files and use Procmail scoring to decide if a particular action should be taken.
LDAP (Lightweight Directory Access Protocol) is a set of open protocols used to access centrally stored information over a network. It is based on the X.500 standard for directory sharing, but is less complex and resource-intensive. For this reason, LDAP is sometimes referred to as «X.500 Lite».
objectClass definition, and can be found in schema files located in the /etc/openldap/slapd.d/cn=config/cn=schema/ directory.
[id] dn:distinguished_nameattribute_type:attribute_value…attribute_type:attribute_value… …
id is a number determined by the application that is used to edit the entry. Each entry can contain as many attribute_type and attribute_value pairs as needed, as long as they are all defined in a corresponding schema file. A blank line indicates the end of an entry.
slapd service as described in Раздел 15.1.4, «Running an OpenLDAP Server».
ldapadd utility to add entries to the LDAP directory.
ldapsearch utility to verify that the slapd service is accessing the information correctly.
| Package | Description |
|---|---|
| openldap | A package containing the libraries necessary to run the OpenLDAP server and client applications. |
| openldap-clients | A package containing the command line utilities for viewing and modifying directories on an LDAP server. |
| openldap-servers |
A package containing both the services and utilities to configure and run an LDAP server. This includes the Standalone LDAP Daemon, slapd.
|
| openldap-servers-sql | A package containing the SQL support module. |
| Package | Description |
|---|---|
| nss-pam-ldapd |
A package containing nslcd, a local LDAP name service that allows a user to perform local LDAP queries.
|
| mod_authz_ldap |
A package containing
mod_authz_ldap, the LDAP authorization module for the Apache HTTP Server. This module uses the short form of the distinguished name for a subject and the issuer of the client SSL certificate to determine the distinguished name of the user within an LDAP directory. It is also capable of authorizing users based on attributes of that user's LDAP directory entry, determining access to assets based on the user and group privileges of the asset, and denying access for users with expired passwords. Note that the mod_ssl module is required when using the mod_authz_ldap module.
|
yum command in the following form:
yuminstallpackage…
root:
yum install openldap openldap-clients openldap-serversroot) to run this command. For more information on how to install new packages in Fedora, refer to Раздел 4.2.4, «Installing Packages».
slapd service:
| Command | Description |
|---|---|
slapacl
| Allows you to check the access to a list of attributes. |
slapadd
| Allows you to add entries from an LDIF file to an LDAP directory. |
slapauth
| Allows you to check a list of IDs for authentication and authorization permissions. |
slapcat
| Allows you to pull entries from an LDAP directory in the default format and save them in an LDIF file. |
slapdn
| Allows you to check a list of Distinguished Names (DNs) based on available schema syntax. |
slapindex
|
Allows you to re-index the slapd directory based on the current content. Run this utility whenever you change indexing options in the configuration file.
|
slappasswd
|
Allows you to create an encrypted user password to be used with the ldapmodify utility, or in the slapd configuration file.
|
slapschema
| Allows you to check the compliance of a database with the corresponding schema. |
slaptest
| Allows you to check the LDAP server configuration. |
root can run slapadd, the slapd service runs as the ldap user. Because of this, the directory server is unable to modify any files created by slapadd. To correct this issue, after running the slapadd utility, type the following at a shell prompt:
chown -R ldap:ldap /var/lib/ldapslapd service before using slapadd, slapcat, or slapindex. You can do so by typing the following at a shell prompt as root:
systemctl stop slapd.serviceslapd service, refer to Раздел 15.1.4, «Running an OpenLDAP Server».
| Command | Description |
|---|---|
ldapadd
|
Allows you to add entries to an LDAP directory, either from a file, or from standard input. It is a symbolic link to ldapmodify -a.
|
ldapcompare
| Allows you to compare given attribute with an LDAP directory entry. |
ldapdelete
| Allows you to delete entries from an LDAP directory. |
ldapexop
| Allows you to perform extended LDAP operations. |
ldapmodify
| Allows you to modify entries in an LDAP directory, either from a file, or from standard input. |
ldapmodrdn
| Allows you to modify the RDN value of an LDAP directory entry. |
ldappasswd
| Allows you to set or change the password for an LDAP user. |
ldapsearch
| Allows you to search LDAP directory entries. |
ldapurl
| Allows you to compose or decompose LDAP URLs. |
ldapwhoami
|
Allows you to perform a whoami operation on an LDAP server.
|
ldapsearch, each of these utilities is more easily used by referencing a file containing the changes to be made rather than typing a command for each entry to be changed within an LDAP directory. The format of such a file is outlined in the man page for each utility.
/etc/openldap/ directory. The following table highlights the most important directories and files within this directory:
/etc/openldap/slapd.conf file. Instead, it uses a configuration database located in the /etc/openldap/slapd.d/ directory. If you have an existing slapd.conf file from a previous installation, you can convert it to the new format by running the following command as root:
slaptest -f /etc/openldap/slapd.conf -F /etc/openldap/slapd.d/slapd configuration consists of LDIF entries organized in a hierarchical directory structure, and the recommended way to edit these entries is to use the server utilities described in Раздел 15.1.2.1, «Overview of OpenLDAP Server Utilities».
slapd service unable to start. Because of this, it is strongly advised that you avoid editing the LDIF files within the /etc/openldap/slapd.d/ directly.
/etc/openldap/slapd.d/cn=config.ldif file. The following directives are commonly used:
olcAllows olcAllows directive allows you to specify which features to enable. It takes the following form:
olcAllows:feature…
bind_v2.
| Option | Description |
|---|---|
bind_v2
| Enables the acceptance of LDAP version 2 bind requests. |
bind_anon_cred
| Enables an anonymous bind when the Distinguished Name (DN) is empty. |
bind_anon_dn
| Enables an anonymous bind when the Distinguished Name (DN) is not empty. |
update_anon
| Enables processing of anonymous update operations. |
proxy_authz_anon
| Enables processing of anonymous proxy authorization control. |
olcAllows: bind_v2 update_anon
olcConnMaxPending olcConnMaxPending directive allows you to specify the maximum number of pending requests for an anonymous session. It takes the following form:
olcConnMaxPending:number
100.
olcConnMaxPending: 100
olcConnMaxPendingAuth olcConnMaxPendingAuth directive allows you to specify the maximum number of pending requests for an authenticated session. It takes the following form:
olcConnMaxPendingAuth:number
1000.
olcConnMaxPendingAuth: 1000
olcDisallows olcDisallows directive allows you to specify which features to disable. It takes the following form:
olcDisallows:feature…
| Option | Description |
|---|---|
bind_anon
| Disables the acceptance of anonymous bind requests. |
bind_simple
| Disables the simple bind authentication mechanism. |
tls_2_anon
| Disables the enforcing of an anonymous session when the STARTTLS command is received. |
tls_authc
| Disallows the STARTTLS command when authenticated. |
olcDisallows: bind_anon
olcIdleTimeout olcIdleTimeout directive allows you to specify how many seconds to wait before closing an idle connection. It takes the following form:
olcIdleTimeout:number
0).
olcIdleTimeout: 180
olcLogFile olcLogFile directive allows you to specify a file in which to write log messages. It takes the following form:
olcLogFile:file_name
olcLogFile: /var/log/slapd.log
olcReferral olcReferral option allows you to specify a URL of a server to process the request in case the server is not able to handle it. It takes the following form:
olcReferral:URL
olcReferral: ldap://root.openldap.org
olcWriteTimeout olcWriteTimeout option allows you to specify how many seconds to wait before closing a connection with an outstanding write request. It takes the following form:
olcWriteTimeout0).
olcWriteTimeout: 180
/etc/openldap/slapd.d/cn=config/olcDatabase={1}bdb.ldif file. The following directives are commonly used in a database-specific configuration:
olcReadOnly olcReadOnly directive allows you to use the database in a read-only mode. It takes the following form:
olcReadOnly:boolean
TRUE (enable the read-only mode), or FALSE (enable modifications of the database). The default option is FALSE.
olcReadOnly: TRUE
olcRootDN olcRootDN directive allows you to specify the user that is unrestricted by access controls or administrative limit parameters set for operations on the LDAP directory. It takes the following form:
olcRootDN:distinguished_name
cn=Manager,dn=my-domain,dc=com.
olcRootDN: cn=root,dn=example,dn=com
olcRootPW olcRootPW directive allows you to set a password for the user that is specified using the olcRootDN directive. It takes the following form:
olcRootPW:password
slappaswd utility, for example:
~]$ slappaswd
New password:
Re-enter new password:
{SSHA}WczWsyPEnMchFf1GRTweq2q7XJcvmSxDolcRootPW: {SSHA}WczWsyPEnMchFf1GRTweq2q7XJcvmSxDolcSuffix olcSuffix directive allows you to specify the domain for which to provide information. It takes the following form:
olcSuffix:domain_name
dc=my-domain,dc=com.
olcSuffix: dc=example,dc=com
/etc/openldap/slapd.d/ directory also contains LDAP definitions that were previously located in /etc/openldap/schema/. It is possible to extend the schema used by OpenLDAP to support additional attribute types and object classes using the default schema files as a guide. However, this task is beyond the scope of this chapter. For more information on this topic, refer to http://www.openldap.org/doc/admin/schema.html.
slapd service, type the following at a shell prompt as root:
systemctl start slapd.servicesystemctl enable slapd.serviceslapd service, type the following at a shell prompt as root:
systemctl stop slapd.servicesystemctl disable slapd.serviceroot:
yum install openldap openldap-clients nss-pam-ldapdroot:
yum install migrationtools/usr/share/migrationtools/ directory. Once installed, edit the /usr/share/migrationtools/migrate_common.ph file and change the following lines to reflect the correct domain, for example:
# Default DNS domain $DEFAULT_MAIL_DOMAIN = "example.com"; # Default base $DEFAULT_BASE = "dc=example,dc=com";
migrate_all_online.sh script with the default base set to dc=example,dc=com, type:
export DEFAULT_BASE="dc=example,dc=com" \/usr/share/migrationtools/migrate_all_online.sh
| Existing Name Service | Is LDAP Running? | Script to Use |
|---|---|---|
/etc flat files
| yes |
migrate_all_online.sh
|
/etc flat files
| no |
migrate_all_offline.sh
|
| NetInfo | yes |
migrate_all_netinfo_online.sh
|
| NetInfo | no |
migrate_all_netinfo_offline.sh
|
| NIS (YP) | yes |
migrate_all_nis_online.sh
|
| NIS (YP) | no |
migrate_all_nis_offline.sh
|
README and the migration-tools.txt files in the /usr/share/doc/migrationtools-version/ directory.
/usr/share/doc/openldap-servers-version/guide.html/usr/share/doc/openldap-servers-version/README.schemaman ldapadd — Describes how to add entries to an LDAP directory.
man ldapdelete — Describes how to delete entries within an LDAP directory.
man ldapmodify — Describes how to modify entries within an LDAP directory.
man ldapsearch — Describes how to search for entries within an LDAP directory.
man ldappasswd — Describes how to set or change the password of an LDAP user.
man ldapcompare — Describes how to use the ldapcompare tool.
man ldapwhoami — Describes how to use the ldapwhoami tool.
man ldapmodrdn — Describes how to modify the RDNs of entries.
man slapd — Describes command line options for the LDAP server.
man slapadd — Describes command line options used to add entries to a slapd database.
man slapcat — Describes command line options used to generate an LDIF file from a slapd database.
man slapindex — Describes command line options used to regenerate an index based upon the contents of a slapd database.
man slappasswd — Describes command line options used to generate user passwords for LDAP directories.
man ldap.conf — Describes the format and options available within the configuration file for LDAP clients.
man slapd-config — Describes the format and options available within the configuration directory.
smb.conf FileSMB) protocol. It allows the networking of Microsoft Windows®, Linux, UNIX, and other operating systems together, enabling access to Windows-based file and printer shares. Samba's use of SMB allows it to appear as a Windows server to Windows clients.
root:
yum install sambaLDAP) and Kerberos
WINS) name server resolution
smbd, nmbd, and winbindd). Three services (smb, nmb, and winbind) control how the daemons are started, stopped, and other service-related features. These services act as different init scripts. Each daemon is listed in detail below, as well as which specific service has control over it.
smbd smbd server daemon provides file sharing and printing services to Windows clients. In addition, it is responsible for user authentication, resource locking, and data sharing through the SMB protocol. The default ports on which the server listens for SMB traffic are TCP ports 139 and 445.
smbd daemon is controlled by the smb service.
nmbd nmbd server daemon understands and replies to NetBIOS name service requests such as those produced by SMB/Common Internet File System (CIFS) in Windows-based systems. These systems include Windows 95/98/ME, Windows NT, Windows 2000, Windows XP, and LanManager clients. It also participates in the browsing protocols that make up the Windows Network Neighborhood view. The default port that the server listens to for NMB traffic is UDP port 137.
nmbd daemon is controlled by the nmb service.
winbindd winbind service resolves user and group information on a server running Windows NT, 2000, 2003 or Windows Server 2008. This makes Windows user / group information understandable by UNIX platforms. This is achieved by using Microsoft RPC calls, Pluggable Authentication Modules (PAM), and the Name Service Switch (NSS). This allows Windows NT domain users to appear and operate as UNIX users on a UNIX machine. Though bundled with the Samba distribution, the winbind service is controlled separately from the smb service.
winbindd daemon is controlled by the winbind service and does not require the smb service to be started in order to operate. winbindd is also used when Samba is an Active Directory member, and may also be used on a Samba domain controller (to implement nested groups and/or interdomain trust). Because winbind is a client-side service used to connect to Windows NT-based servers, further discussion of winbind is beyond the scope of this chapter.
SMB workgroup or domain on the network. Double-click one of the workgroup/domain icons to view a list of computers within the workgroup/domain.
servername and sharename with the appropriate values):
smb://servername/sharenameroot:
mount -t cifs //servername/sharename /mnt/point/ -o username=username,password=passwordsharename from servername in the local directory /mnt/point/.
root:
yum install cifs-utilsman cifs.upcall.
man mount.cifs.
root:
echo 0x37 > /proc/fs/cifs/SecurityFlags/etc/samba/smb.conf) allows users to view their home directories as a Samba share. It also shares all printers configured for the system as Samba shared printers. In other words, you can attach a printer to the system and print to it from the Windows machines on your network.
/etc/samba/smb.conf as its configuration file. If you change this configuration file, the changes do not take effect until you restart the Samba daemon with the following command, as root:
systemctl restart smb.service/etc/samba/smb.conf file:
workgroup =WORKGROUPNAMEserver string =BRIEF COMMENT ABOUT SERVER
WORKGROUPNAME with the name of the Windows workgroup to which this machine should belong. The BRIEF COMMENT ABOUT SERVER is optional and is used as the Windows comment about the Samba system.
/etc/samba/smb.conf file (after modifying it to reflect your needs and your system):
[sharename] comment =Insert a comment herepath =/home/share/valid users =tfox carolepublic = no writable = yes printable = no create mask = 0765
tfox and carole to read and write to the directory /home/share, on the Samba server, from a Samba client.
root:
systemctl start smb.servicenet join command before starting the smb service.
root:
systemctl stop smb.servicerestart option is a quick way of stopping and then starting Samba. This is the most reliable way to make configuration changes take effect after editing the configuration file for Samba. Note that the restart option starts the daemon even if it was not running originally.
root:
systemctl restart smb.servicecondrestart (conditional restart) option only starts smb on the condition that it is currently running. This option is useful for scripts, because it does not start the daemon if it is not running.
/etc/samba/smb.conf file is changed, Samba automatically reloads it after a few minutes. Issuing a manual restart or reload is just as effective.
root:
systemctl condrestart smb.service/etc/samba/smb.conf file can be useful in case of a failed automatic reload by the smb service. To ensure that the Samba server configuration file is reloaded without restarting the service, type the following command, as root:
systemctl reload smb.servicesmb service does not start automatically at boot time. To configure Samba to start at boot time, use a service manager such as systemctl. Refer to Глава 8, Services and Daemons for more information regarding this tool.
smb.conf File/etc/samba/smb.conf configuration file. Although the default smb.conf file is well documented, it does not address complex topics such as LDAP, Active Directory, and the numerous domain controller implementations.
/etc/samba/smb.conf file for a successful configuration.
/etc/samba/smb.conf file shows a sample configuration needed to implement anonymous read-only file sharing. The security = share parameter makes a share anonymous. Note, security levels for a single Samba server cannot be mixed. The security directive is a global Samba parameter located in the [global] configuration section of the /etc/samba/smb.conf file.
[global] workgroup = DOCS netbios name = DOCS_SRV security = share [data] comment = Documentation Samba Server path = /export read only = Yes guest only = Yes
/etc/samba/smb.conf file shows a sample configuration needed to implement anonymous read/write file sharing. To enable anonymous read/write file sharing, set the read only directive to no. The force user and force group directives are also added to enforce the ownership of any newly placed files specified in the share.
force user) and group (force group) in the /etc/samba/smb.conf file.
[global] workgroup = DOCS netbios name = DOCS_SRV security = share [data] comment = Data path = /export force user = docsbot force group = users read only = No guest ok = Yes
/etc/samba/smb.conf file shows a sample configuration needed to implement an anonymous print server. Setting browseable to no as shown does not list the printer in Windows Network Neighborhood. Although hidden from browsing, configuring the printer explicitly is possible. By connecting to DOCS_SRV using NetBIOS, the client can have access to the printer if the client is also part of the DOCS workgroup. It is also assumed that the client has the correct local printer driver installed, as the use client driver directive is set to Yes. In this case, the Samba server has no responsibility for sharing printer drivers to the client.
[global] workgroup = DOCS netbios name = DOCS_SRV security = share printcap name = cups disable spools= Yes show add printer wizard = No printing = cups [printers] comment = All Printers path = /var/spool/samba guest ok = Yes printable = Yes use client driver = Yes browseable = Yes
/etc/samba/smb.conf file shows a sample configuration needed to implement a secure read/write print server. Setting the security directive to user forces Samba to authenticate client connections. Notice the [homes] share does not have a force user or force group directive as the [public] share does. The [homes] share uses the authenticated user details for any files created as opposed to the force user and force group in [public].
[global] workgroup = DOCS netbios name = DOCS_SRV security = user printcap name = cups disable spools = Yes show add printer wizard = No printing = cups [homes] comment = Home Directories valid users = %S read only = No browseable = No [public] comment = Data path = /export force user = docsbot force group = users guest ok = Yes [printers] comment = All Printers path = /var/spool/samba printer admin = john, ed, @admins create mask = 0600 guest ok = Yes printable = Yes use client driver = Yes browseable = Yes
/etc/samba/smb.conf file shows a sample configuration needed to implement an Active Directory domain member server. In this example, Samba authenticates users for services being run locally but is also a client of the Active Directory. Ensure that your kerberos realm parameter is shown in all caps (for example realm = EXAMPLE.COM). Since Windows 2000/2003/2008 requires Kerberos for Active Directory authentication, the realm directive is required. If Active Directory and Kerberos are running on different servers, the password server directive may be required to help the distinction.
[global] realm = EXAMPLE.COM security = ADS encrypt passwords = yes # Optional. Use only if Samba cannot determine the Kerberos server automatically. password server = kerberos.example.com
/etc/samba/smb.conf file on the member server
/etc/krb5.conf file, on the member server
root on the member server:
kinit administrator@EXAMPLE.COMkinit command is a Kerberos initialization script that references the Active Directory administrator account and Kerberos realm. Since Active Directory requires Kerberos tickets, kinit obtains and caches a Kerberos ticket-granting ticket for client/server authentication. For more information on Kerberos, the /etc/krb5.conf file, and the kinit command, refer to the Using Kerberos section of the Red Hat Enterprise Linux 6 Managing Single Sign-On and Smart Cards guide.
root on the member server:
net ads join -S windows1.example.com -U administrator%passwordwindows1 was automatically found in the corresponding Kerberos realm (the kinit command succeeded), the net command connects to the Active Directory server using its required administrator account and password. This creates the appropriate machine account on the Active Directory and grants permissions to the Samba domain member server to join the domain.
security = ads and not security = user is used, a local password back end such as smbpasswd is not needed. Older clients that do not support security = ads are authenticated as if security = domain had been set. This change does not affect functionality and allows local users not previously in the domain.
/etc/samba/smb.conf file shows a sample configuration needed to implement a Windows NT4-based domain member server. Becoming a member server of an NT4-based domain is similar to connecting to an Active Directory. The main difference is NT4-based domains do not use Kerberos in their authentication method, making the /etc/samba/smb.conf file simpler. In this instance, the Samba member server functions as a pass through to the NT4-based domain server.
[global] workgroup = DOCS netbios name = DOCS_SRV security = domain [homes] comment = Home Directories valid users = %S read only = No browseable = No [public] comment = Data path = /export force user = docsbot force group = users guest ok = Yes
/etc/samba/smb.conf file to convert the server to a Samba-based PDC. If Windows NT-based servers are upgraded to Windows 2000/2003/2008, the /etc/samba/smb.conf file is easily modifiable to incorporate the infrastructure change to Active Directory if needed.
/etc/samba/smb.conf file, join the domain before starting Samba by typing the following command as root:
net rpc join -U administrator%password-S option, which specifies the domain server hostname, does not need to be stated in the net rpc join command. Samba uses the hostname specified by the workgroup directive in the /etc/samba/smb.conf file instead of it being stated explicitly.
tdbsam tdbsam password database back end. Replacing the aging smbpasswd back end, tdbsam has numerous improvements that are explained in more detail in Раздел 16.1.8, «Samba Account Information Databases». The passdb backend directive controls which back end is to be used for the PDC.
/etc/samba/smb.conf file shows a sample configuration needed to implement a tdbsam password database back end.
[global]
workgroup = DOCS
netbios name = DOCS_SRV
passdb backend = tdbsam
security = user
add user script = /usr/sbin/useradd -m "%u"
delete user script = /usr/sbin/userdel -r "%u"
add group script = /usr/sbin/groupadd "%g"
delete group script = /usr/sbin/groupdel "%g"
add user to group script = /usr/sbin/usermod -G "%g" "%u"
add machine script = /usr/sbin/useradd -s /bin/false -d /dev/null -g machines "%u"
# The following specifies the default logon script
# Per user logon scripts can be specified in the user
# account using pdbedit logon script = logon.bat
# This sets the default profile path.
# Set per user paths with pdbedit
logon drive = H:
domain logons = Yes
os level = 35
preferred master = Yes
domain master = Yes
[homes]
comment = Home Directories
valid users = %S
read only = No
[netlogon]
comment = Network Logon Service
path = /var/lib/samba/netlogon/scripts
browseable = No
read only = No
# For profiles to work, create a user directory under the
# path shown.
mkdir -p /var/lib/samba/profiles/john
[Profiles]
comment = Roaming Profile Share
path = /var/lib/samba/profiles
read only = No
browseable = No
guest ok = Yes
profile acls = Yes
# Other resource shares ... ...tdbsam follow these steps:
smb.conf file as shown in the example above.
root user to the Samba password database:
smbpasswd -a rootsmb service.
groupadd -f usersgroupadd -f nobodygroupadd -f ntadmins
net groupmap add ntgroup="Domain Users" unixgroup=usersnet groupmap add ntgroup="Domain Guests" unixgroup=nobodynet groupmap add ntgroup="Domain Admins" unixgroup=ntadmins
net rpc rights grant 'DOCS\Domain Admins' SetMachineAccountPrivilege -S PDC -U roottdbsam authentication back end. LDAP is recommended in these cases.
security = user directive is not listed in the /etc/samba/smb.conf file, it is used by Samba. If the server accepts the client's username/password, the client can then mount multiple shares without specifying a password for each instance. Samba can also accept session-based username/password requests. The client maintains multiple authentication contexts by using a unique UID for each logon.
/etc/samba/smb.conf file, the security = user directive that sets user-level security is:
[GLOBAL] ... security = user ...
/etc/samba/smb.conf file:
[GLOBAL] ... security = domain workgroup = MARKETING ...
/etc/samba/smb.conf file, the following directives make Samba an Active Directory member server:
[GLOBAL] ... security = ADS realm = EXAMPLE.COM password server = kerberos.example.com ...
/etc/samba/smb.conf, the following directives enable Samba to operate in server security mode:
[GLOBAL] ... encrypt passwords = Yes security = server password server = "NetBIOS_of_Domain_Controller" ...
/etc/passwd type back ends. With a plain text back end, all usernames and passwords are sent unencrypted between the client and the Samba server. This method is very unsecure and is not recommended for use by any means. It is possible that different Windows clients connecting to the Samba server with plain text passwords cannot support such an authentication method.
smbpasswd smbpasswd back end utilizes a plain ASCII text layout that includes the MS Windows LanMan and NT account, and encrypted password information. The smbpasswd back end lacks the storage of the Windows NT/2000/2003 SAM extended controls. The smbpasswd back end is not recommended because it does not scale well or hold any Windows information, such as RIDs for NT-based groups. The tdbsam back end solves these issues for use in a smaller database (250 users), but is still not an enterprise-class solution.
ldapsam_compat ldapsam_compat back end allows continued OpenLDAP support for use with upgraded versions of Samba. This option is normally used when migrating to Samba 3.0.
tdbsam tdbsam password back end provides an ideal database back end for local servers, servers that do not need built-in database replication, and servers that do not require the scalability or complexity of LDAP. The tdbsam back end includes all of the smbpasswd database information as well as the previously-excluded SAM information. The inclusion of the extended SAM data allows Samba to implement the same account and system access controls as seen with Windows NT/2000/2003/2008-based systems.
tdbsam back end is recommended for 250 users at most. Larger organizations should require Active Directory or LDAP integration due to scalability and possible network infrastructure concerns.
ldapsam ldapsam back end provides an optimal distributed account installation method for Samba. LDAP is optimal because of its ability to replicate its database to any number of servers such as the Red Hat Directory Server or an OpenLDAP Server. LDAP databases are light-weight and scalable, and as such are preferred by large enterprises. Installation and configuration of directory servers is beyond the scope of this chapter. For more information on the Red Hat Directory Server, refer to the Red Hat Directory Server 8.2 Deployment Guide. For more information on LDAP, refer to Раздел 15.1, «OpenLDAP».
/usr/share/doc/samba-version/LDAP/samba.schema) and the Red Hat Directory Server schema file (/usr/share/doc/samba-version/LDAP/samba-schema-FDS.ldif) have changed. These files contain the attribute syntax definitions and objectclass definitions that the ldapsam back end needs in order to function properly.
ldapsam back end for your Samba server, you will need to configure slapd to include one of these schema file. Refer to Раздел 15.1.3.3, «Extending Schema» for directions on how to do this.
openldap-server package installed if you want to use the ldapsam back end.
TCP/IP. NetBIOS-based networking uses broadcast (UDP) messaging to accomplish browse list management. Without NetBIOS and WINS as the primary method for TCP/IP hostname resolution, other methods such as static files (/etc/hosts) or DNS, must be used.
/etc/samba/smb.conf file for a local master browser (or no browsing at all) in a domain controller environment is the same as workgroup configuration.
/etc/samba/smb.conf file in which the Samba server is serving as a WINS server:
[global] wins support = Yes
smb.conf Settings/etc/samba/smb.conf configuration for CUPS support:
[global] load printers = Yes printing = cups printcap name = cups [printers] comment = All Printers path = /var/spool/samba browseable = No public = Yes guest ok = Yes writable = No printable = Yes printer admin = @ntadmins [print$] comment = Printer Drivers Share path = /var/lib/samba/drivers write list = ed, john printer admin = ed, john
print$ directive contains printer drivers for clients to access if not available locally. The print$ directive is optional and may not be required depending on the organization.
browseable to Yes enables the printer to be viewed in the Windows Network Neighborhood, provided the Samba server is set up correctly in the domain/workgroup.
findsmb findsmb subnet_broadcast_addressfindsmb program is a Perl script which reports information about SMB-aware systems on a specific subnet. If no subnet is specified the local subnet is used. Items displayed include IP address, NetBIOS name, workgroup or domain name, operating system, and version.
findsmb as any valid user on a system:
~]$ findsmb
IP ADDR NETBIOS NAME WORKGROUP/OS/VERSION
------------------------------------------------------------------
10.1.59.25 VERVE [MYGROUP] [Unix] [Samba 3.0.0-15]
10.1.59.26 STATION22 [MYGROUP] [Unix] [Samba 3.0.2-7.FC1]
10.1.56.45 TREK +[WORKGROUP] [Windows 5.0] [Windows 2000 LAN Manager]
10.1.57.94 PIXEL [MYGROUP] [Unix] [Samba 3.0.0-15]
10.1.57.137 MOBILE001 [WORKGROUP] [Windows 5.0] [Windows 2000 LAN Manager]
10.1.57.141 JAWS +[KWIKIMART] [Unix] [Samba 2.2.7a-security-rollup-fix]
10.1.56.159 FRED +[MYGROUP] [Unix] [Samba 3.0.0-14.3E]
10.1.59.192 LEGION *[MYGROUP] [Unix] [Samba 2.2.7-security-rollup-fix]
10.1.56.205 NANCYN +[MYGROUP] [Unix] [Samba 2.2.7a-security-rollup-fix]net net protocol function misc_options target_optionsnet utility is similar to the net utility used for Windows and MS-DOS. The first argument is used to specify the protocol to use when executing a command. The protocol ads, rap, or rpc for specifying the type of server connection. Active Directory uses ads, Win9x/NT3 uses rap, and Windows NT4/2000/2003/2008 uses rpc. If the protocol is omitted, net automatically tries to determine it.
wakko:
~]$ net -l share -S wakko
Password:
Enumerating shared resources (exports) on remote server:
Share name Type Description
---------- ---- -----------
data Disk Wakko data share
tmp Disk Wakko tmp share
IPC$ IPC IPC Service (Samba Server)
ADMIN$ IPC IPC Service (Samba Server)wakko:
~]$ net -l user -S wakko
root password:
User name Comment
-----------------------------
andriusb Documentation
joe Marketing
lisa Salesnmblookup nmblookup options netbios_namenmblookup program resolves NetBIOS names into IP addresses. The program broadcasts its query on the local subnet until the target machine replies.
~]$ nmblookup trek
querying trek on 10.1.59.255
10.1.56.45 trek<00>pdbedit pdbedit optionspdbedit program manages accounts located in the SAM database. All back ends are supported including smbpasswd, LDAP, and the tdb database library.
~]$pdbedit -a kristinnew password: retype new password: Unix username: kristin NT username: Account Flags: [U ] User SID: S-1-5-21-1210235352-3804200048-1474496110-2012 Primary Group SID: S-1-5-21-1210235352-3804200048-1474496110-2077 Full Name: Home Directory: \\wakko\kristin HomeDir Drive: Logon Script: Profile Path: \\wakko\kristin\profile Domain: WAKKO Account desc: Workstations: Munged dial: Logon time: 0 Logoff time: Mon, 18 Jan 2038 22:14:07 GMT Kickoff time: Mon, 18 Jan 2038 22:14:07 GMT Password last set: Thu, 29 Jan 2004 08:29:28 GMT Password can change: Thu, 29 Jan 2004 08:29:28 GMT Password must change: Mon, 18 Jan 2038 22:14:07 GMT~]$ pdbedit -v -L kristinUnix username: kristin NT username: Account Flags: [U ] User SID: S-1-5-21-1210235352-3804200048-1474496110-2012 Primary Group SID: S-1-5-21-1210235352-3804200048-1474496110-2077 Full Name: Home Directory: \\wakko\kristin HomeDir Drive: Logon Script: Profile Path: \\wakko\kristin\profile Domain: WAKKO Account desc: Workstations: Munged dial: Logon time: 0 Logoff time: Mon, 18 Jan 2038 22:14:07 GMT Kickoff time: Mon, 18 Jan 2038 22:14:07 GMT Password last set: Thu, 29 Jan 2004 08:29:28 GMT Password can change: Thu, 29 Jan 2004 08:29:28 GMT Password must change: Mon, 18 Jan 2038 22:14:07 GMT~]$ pdbedit -Landriusb:505: joe:503: lisa:504: kristin:506:~]$ pdbedit -x joe~]$ pdbedit -Landriusb:505: lisa:504: kristin:506:
rpcclient rpcclient server optionsrpcclient program issues administrative commands using Microsoft RPCs, which provide access to the Windows administration graphical user interfaces (GUIs) for systems management. This is most often used by advanced users that understand the full complexity of Microsoft RPCs.
smbcacls smbcacls //server/share filename optionssmbcacls program modifies Windows ACLs on files and directories shared by a Samba server or a Windows server.
smbclient smbclient //server/share password optionssmbclient program is a versatile UNIX client which provides functionality similar to ftp.
smbcontrol smbcontrol -i optionssmbcontrol options destination messagetype parameterssmbcontrol program sends control messages to running smbd, nmbd, or winbindd daemons. Executing smbcontrol -i runs commands interactively until a blank line or a 'q' is entered.
smbpasswd smbpasswd options username passwordsmbpasswd program manages encrypted passwords. This program can be run by a superuser to change any user's password as well as by an ordinary user to change their own Samba password.
smbspool smbspool job user title copies options filenamesmbspool program is a CUPS-compatible printing interface to Samba. Although designed for use with CUPS printers, smbspool can work with non-CUPS printers as well.
smbstatus smbstatus optionssmbstatus program displays the status of current connections to a Samba server.
smbtar smbtar optionssmbtar program performs backup and restores of Windows-based share files and directories to a local tape archive. Though similar to the tar command, the two are not compatible.
testparm testparm options filename hostname IP_addresstestparm program checks the syntax of the /etc/samba/smb.conf file. If your /etc/samba/smb.conf file is in the default location (/etc/samba/smb.conf) you do not need to specify the location. Specifying the hostname and IP address to the testparm program verifies that the hosts.allow and host.deny files are configured correctly. The testparm program also displays a summary of your /etc/samba/smb.conf file and the server's role (stand-alone, domain, etc.) after testing. This is convenient when debugging as it excludes comments and concisely presents information for experienced administrators to read.
~]$testparmLoad smb config files from /etc/samba/smb.conf Processing section "[homes]" Processing section "[printers]" Processing section "[tmp]" Processing section "[html]" Loaded services file OK. Server role: ROLE_STANDALONE Press enter to see a dump of your service definitions<enter># Global parameters [global] workgroup = MYGROUP server string = Samba Server security = SHARE log file = /var/log/samba/%m.log max log size = 50 socket options = TCP_NODELAY SO_RCVBUF=8192 SO_SNDBUF=8192 dns proxy = No [homes] comment = Home Directories read only = No browseable = No [printers] comment = All Printers path = /var/spool/samba printable = Yes browseable = No [tmp] comment = Wakko tmp path = /tmp guest only = Yes [html] comment = Wakko www path = /var/www/html force user = andriusb force group = users read only = No guest only = Yes
wbinfo wbinfo optionswbinfo program displays information from the winbindd daemon. The winbindd daemon must be running for wbinfo to work.
/usr/share/doc/samba-version-number/ — All additional files included with the Samba distribution. This includes all helper scripts, sample configuration files, and documentation. This directory also contains online versions of The Official Samba-3 HOWTO-Collection and Samba-3 by Example, both of which are cited below.
root:
yum install samba-docsmb.conf
samba
smbd
nmbd
winbind
FTP) это один из самых старых и всё ещё используемых протоколов которые можно найти сегодня в интернете. Его целью является надежная передача файлов между компьютерными хостами в сети, не требующая от пользователя входа непосредственно на удалённый хост или знания того, как нужно использовать удаленную систему. Это позволяет пользователям получать доступ к файлам на удалённых системах, использующих стандартный набор простых команд.
FTP, а также параметры конфигурации для основного FTP-сервера, поставляемого с Fedora, vsftpd.
FTP настолько распространен в интернете, часто требуется общий доступ к файлам. Следовательно, системные администраторы должны быть осведомлены об уникальных характеристиках протокола FTP.
FTP, для работы должным образом требует несколько сетевых портов. Когда приложение FTP-клиента инициирует соединение с FTP-сервером, он открывает 21 порт на сервере, известный как командный порт. Этот порт используется для передачи всех команд серверу. Любые данные, запрашиваемые с сервера, возвращаются клиенту через порт данных. Номер порта для передачи данных и то, как данные соединения инициализированы, различаются в зависимости от того, в каком режиме клиент запрашивает данные: активном или пассивном.
FTP для передачи данных клиентскому приложению. Когда передача файлов в активном режиме инициируется FTP-клиентом, сервер открывает соединение на 20 порту IP адреса и любом непривилегированном порту (большем, чем 1024), определяемым клиентом. Эта договорённость означает что клиентской машине должно быть выдано разрешение на приём подключений по любому порту выше 1024. С ростом небезопасных сетей, таких как интернет, использование брандмауэров для защиты клиентских машин сейчас распространено. Из-за того, что брандмауэры со стороны клиента часто запрещают входящие подключения от активного режима FTP-серверов, был разработан пассивный режим.
FTP-приложением. При запросе данных с сервера FTP-клиент показывает, что хочет получить данные в пассивном режиме, и сервер предоставляет IP-адрес и случайный, непривилегированный порт (больший, чем 1024) на сервере. Затем клиент подключается по этому порту на сервере и загружает требуемую информацию.
FTP-сервере. Это также упрощает процесс настройки правил брандмауэра для сервера. Перейдите к Раздел 16.2.5.8, «Network Options» для большей информации об ограничении пассивных портов.
FTP серверами:
FTP services. Since speed is its primary design goal, it has limited functionality and runs only as an anonymous FTP server. For more information about configuring and administering Red Hat Content Accelerator, consult the documentation available online at http://www.redhat.com/docs/manuals/tux/.
vsftpd — Быстрый, безопасный FTP демон, являющийся по умолчанию FTP сервером для Fedora. Остальная часть этого раздела посвящена vsftpd.
vsftpdvsftpd) разработан для того, чтобы быть быстрым, стабильным, и главное безопасным. vsftpd является единственным автономным FTP-сервером, распространяющимся с Fedora, благодаря способности обрабатывать большие количества соединений эффективно и безопасно.
vsftpd has three primary aspects:
libcap library, tasks that usually require full root privileges can be executed more safely from a less privileged process.
chroot jail — Whenever possible, processes are change-rooted to the directory being shared; this directory is then considered a chroot jail. For example, if the directory /var/ftp/ is the primary shared directory, vsftpd reassigns /var/ftp/ to the new root directory, known as /. This disallows any potential malicious hacker activities for any directories not contained below the new root directory.
vsftpd deals with requests:
FTP clients and run with as close to no privileges as possible.
HTTP Server, vsftpd launches unprivileged child processes to handle incoming connections. This allows the privileged, parent process to be as small as possible and handle relatively few tasks.
FTP clients is handled by unprivileged child processes in a chroot jail — Because these child processes are unprivileged and only have access to the directory being shared, any crashed processes only allows the attacker access to the shared files.
vsftpd vsftpd RPM installs the daemon (/usr/sbin/vsftpd), its configuration and related files, as well as FTP directories onto the system. The following lists the files and directories related to vsftpd configuration:
/etc/rc.d/init.d/vsftpd — The initialization script (initscript) used by the systemctl command to start, stop, or reload vsftpd. Refer to Раздел 16.2.4, «Запуск и остановка vsftpd» for more information about using this script.
/etc/pam.d/vsftpd — The Pluggable Authentication Modules (PAM) configuration file for vsftpd. This file specifies the requirements a user must meet to login to the FTP server. For more information on PAM, refer to the Using Pluggable Authentication Modules (PAM) chapter of the Fedora 17 Managing Single Sign-On and Smart Cards guide.
/etc/vsftpd/vsftpd.conf — The configuration file for vsftpd. Refer to Раздел 16.2.5, « vsftpd Configuration Options» for a list of important options contained within this file.
/etc/vsftpd/ftpusers — A list of users not allowed to log into vsftpd. By default, this list includes the root, bin, and daemon users, among others.
/etc/vsftpd/user_list — This file can be configured to either deny or allow access to the users listed, depending on whether the userlist_deny directive is set to YES (default) or NO in /etc/vsftpd/vsftpd.conf. If /etc/vsftpd/user_list is used to grant access to users, the usernames listed must not appear in /etc/vsftpd/ftpusers.
/var/ftp/ — The directory containing files served by vsftpd. It also contains the /var/ftp/pub/ directory for anonymous users. Both directories are world-readable, but writable only by the root user.
vsftpdvsftpd устанавливает /etc/rc.d/init.d/vsftpd скрипт, который может быть доступен путем использования команды systemctl.
root type:
systemctl start vsftpd.serviceroot type:
systemctl stop vsftpd.servicerestart option is a shorthand way of stopping and then starting vsftpd. This is the most efficient way to make configuration changes take effect after editing the configuration file for vsftpd.
root type:
systemctl restart vsftpd.servicecondrestart (conditional restart) option only starts vsftpd if it is currently running. This option is useful for scripts, because it does not start the daemon if it is not running.
root type:
systemctl condrestart vsftpd.servicevsftpd service does not start automatically at boot time. To configure the vsftpd service to start at boot time, use a service manager such as systemctl. Refer to Глава 8, Services and Daemons for more information on how to configure services in Fedora.
vsftpd FTP domains. This is a technique called multihoming. One way to multihome using vsftpd is by running multiple copies of the daemon, each with its own configuration file.
IP addresses to network devices or alias network devices on the system. Additional information about network configuration scripts can be found in Глава 7, Сетевые интерфейсы.
FTP domains must be configured to reference the correct machine. For information about BIND and its configuration files, refer to Раздел 12.2, «BIND».
/etc/vsftpd directory, calling systemctl start vsftpd.service results in the /etc/rc.d/init.d/vsftpd initscript starting the same number of processes as the number of configuration files. Each configuration file must have a unique name in the /etc/vsftpd/ directory and must be readable and writable only by root.
vsftpd Configuration Optionsvsftpd may not offer the level of customization other widely available FTP servers have, it offers enough options to fill most administrator's needs. The fact that it is not overly feature-laden limits configuration and programmatic errors.
vsftpd is handled by its configuration file, /etc/vsftpd/vsftpd.conf. Each directive is on its own line within the file and follows the following format:
directive=value
directive with a valid directive and value with a valid value.
directive, equal symbol, and the value in a directive.
#) and are ignored by the daemon.
vsftpd.conf.
vsftpd, refer to the Fedora 17 Security Guide.
/etc/vsftpd/vsftpd.conf. All directives not explicitly found or commented out within vsftpd's configuration file are set to their default value.
vsftpd daemon.
listen — When enabled, vsftpd runs in stand-alone mode. Fedora sets this value to YES. This directive cannot be used in conjunction with the listen_ipv6 directive.
NO.
listen_ipv6 — When enabled, vsftpd runs in stand-alone mode, but listens only to IPv6 sockets. This directive cannot be used in conjunction with the listen directive.
NO.
session_support — When enabled, vsftpd attempts to maintain login sessions for each user through Pluggable Authentication Modules (PAM). For more information, refer to the Using Pluggable Authentication Modules (PAM) chapter of the Red Hat Enterprise Linux 6 Managing Single Sign-On and Smart Cards and the PAM man pages. . If session logging is not necessary, disabling this option allows vsftpd to run with less processes and lower privileges.
YES.
anonymous_enable — When enabled, anonymous users are allowed to log in. The usernames anonymous and ftp are accepted.
YES.
banned_email_file — If the deny_email_enable directive is set to YES, this directive specifies the file containing a list of anonymous email passwords which are not permitted access to the server.
/etc/vsftpd/banned_emails.
banner_file — Specifies the file containing text displayed when a connection is established to the server. This option overrides any text specified in the ftpd_banner directive.
cmds_allowed — Specifies a comma-delimited list of FTP commands allowed by the server. All other commands are rejected.
deny_email_enable — When enabled, any anonymous user utilizing email passwords specified in the /etc/vsftpd/banned_emails are denied access to the server. The name of the file referenced by this directive can be specified using the banned_email_file directive.
NO.
ftpd_banner — When enabled, the string specified within this directive is displayed when a connection is established to the server. This option can be overridden by the banner_file directive.
vsftpd displays its standard banner.
local_enable — When enabled, local users are allowed to log into the system.
YES.
pam_service_name — Specifies the PAM service name for vsftpd.
ftp. Note, in Fedora, the value is set to vsftpd.
NO. Note, in Fedora, the value is set to YES.
userlist_deny — When used in conjunction with the userlist_enable directive and set to NO, all local users are denied access unless the username is listed in the file specified by the userlist_file directive. Because access is denied before the client is asked for a password, setting this directive to NO prevents local users from submitting unencrypted passwords over the network.
YES.
userlist_enable — When enabled, the users listed in the file specified by the userlist_file directive are denied access. Because access is denied before the client is asked for a password, users are prevented from submitting unencrypted passwords over the network.
NO, however under Fedora the value is set to YES.
userlist_file — Specifies the file referenced by vsftpd when the userlist_enable directive is enabled.
/etc/vsftpd/user_list and is created during installation.
anonymous_enable directive must be set to YES.
anon_mkdir_write_enable — When enabled in conjunction with the write_enable directive, anonymous users are allowed to create new directories within a parent directory which has write permissions.
NO.
anon_root — Specifies the directory vsftpd changes to after an anonymous user logs in.
anon_upload_enable — When enabled in conjunction with the write_enable directive, anonymous users are allowed to upload files within a parent directory which has write permissions.
NO.
anon_world_readable_only — When enabled, anonymous users are only allowed to download world-readable files.
YES.
ftp_username — Specifies the local user account (listed in /etc/passwd) used for the anonymous FTP user. The home directory specified in /etc/passwd for the user is the root directory of the anonymous FTP user.
ftp.
no_anon_password — When enabled, the anonymous user is not asked for a password.
NO.
secure_email_list_enable — When enabled, only a specified list of email passwords for anonymous logins are accepted. This is a convenient way to offer limited security to public content without the need for virtual users.
/etc/vsftpd/email_passwords. The file format is one password per line, with no trailing white spaces.
NO.
local_enable directive must be set to YES.
chmod_enable — When enabled, the FTP command SITE CHMOD is allowed for local users. This command allows the users to change the permissions on files.
YES.
chroot_list_enable — When enabled, the local users listed in the file specified in the chroot_list_file directive are placed in a chroot jail upon log in.
chroot_local_user directive, the local users listed in the file specified in the chroot_list_file directive are not placed in a chroot jail upon log in.
NO.
chroot_list_file — Specifies the file containing a list of local users referenced when the chroot_list_enable directive is set to YES.
/etc/vsftpd/chroot_list.
chroot_local_user — When enabled, local users are change-rooted to their home directories after logging in.
NO.
chroot_local_user opens up a number of security issues, especially for users with upload privileges. For this reason, it is not recommended.
guest_enable — When enabled, all non-anonymous users are logged in as the user guest, which is the local user specified in the guest_username directive.
NO.
guest_username — Specifies the username the guest user is mapped to.
ftp.
local_root — Specifies the directory vsftpd changes to after a local user logs in.
local_umask — Specifies the umask value for file creation. Note that the default value is in octal form (a numerical system with a base of eight), which includes a "0" prefix. Otherwise the value is treated as a base-10 integer.
022.
passwd_chroot_enable — When enabled in conjunction with the chroot_local_user directive, vsftpd change-roots local users based on the occurrence of the /./ in the home directory field within /etc/passwd.
NO.
user_config_dir — Specifies the path to a directory containing configuration files bearing the name of local system users that contain specific setting for that user. Any directive in the user's configuration file overrides those found in /etc/vsftpd/vsftpd.conf.
dirlist_enable — When enabled, users are allowed to view directory lists.
YES.
dirmessage_enable — When enabled, a message is displayed whenever a user enters a directory with a message file. This message resides within the current directory. The name of this file is specified in the message_file directive and is .message by default.
NO. Note, in Fedora, the value is set to YES.
force_dot_files — When enabled, files beginning with a dot (.) are listed in directory listings, with the exception of the . and .. files.
NO.
hide_ids — When enabled, all directory listings show ftp as the user and group for each file.
NO.
message_file — Specifies the name of the message file when using the dirmessage_enable directive.
.message.
text_userdb_names — When enabled, text usernames and group names are used in place of UID and GID entries. Enabling this option may slow performance of the server.
NO.
use_localtime — When enabled, directory listings reveal the local time for the computer instead of GMT.
NO.
download_enable — When enabled, file downloads are permitted.
YES.
chown_uploads — When enabled, all files uploaded by anonymous users are owned by the user specified in the chown_username directive.
NO.
chown_username — Specifies the ownership of anonymously uploaded files if the chown_uploads directive is enabled.
root.
write_enable — When enabled, FTP commands which can change the file system are allowed, such as DELE, RNFR, and STOR.
YES.
vsftpd's logging behavior.
dual_log_enable — When enabled in conjunction with xferlog_enable, vsftpd writes two files simultaneously: a wu-ftpd-compatible log to the file specified in the xferlog_file directive (/var/log/xferlog by default) and a standard vsftpd log file specified in the vsftpd_log_file directive (/var/log/vsftpd.log by default).
NO.
log_ftp_protocol — When enabled in conjunction with xferlog_enable and with xferlog_std_format set to NO, all FTP commands and responses are logged. This directive is useful for debugging.
NO.
syslog_enable — When enabled in conjunction with xferlog_enable, all logging normally written to the standard vsftpd log file specified in the vsftpd_log_file directive (/var/log/vsftpd.log by default) is sent to the system logger instead under the FTPD facility.
NO.
vsftpd_log_file — Specifies the vsftpd log file. For this file to be used, xferlog_enable must be enabled and xferlog_std_format must either be set to NO or, if xferlog_std_format is set to YES, dual_log_enable must be enabled. It is important to note that if syslog_enable is set to YES, the system log is used instead of the file specified in this directive.
/var/log/vsftpd.log.
xferlog_enable — When enabled, vsftpd logs connections (vsftpd format only) and file transfer information to the log file specified in the vsftpd_log_file directive (/var/log/vsftpd.log by default). If xferlog_std_format is set to YES, file transfer information is logged but connections are not, and the log file specified in xferlog_file (/var/log/xferlog by default) is used instead. It is important to note that both log files and log formats are used if dual_log_enable is set to YES.
NO. Note, in Fedora, the value is set to YES.
xferlog_file — Specifies the wu-ftpd-compatible log file. For this file to be used, xferlog_enable must be enabled and xferlog_std_format must be set to YES. It is also used if dual_log_enable is set to YES.
/var/log/xferlog.
xferlog_std_format — When enabled in conjunction with xferlog_enable, only a wu-ftpd-compatible file transfer log is written to the file specified in the xferlog_file directive (/var/log/xferlog by default). It is important to note that this file only logs file transfers and does not log connections to the server.
NO. Note, in Fedora, the value is set to YES.
wu-ftpd FTP server, the xferlog_std_format directive is set to YES under Fedora. However, this setting means that connections to the server are not logged.
vsftpd format and maintain a wu-ftpd-compatible file transfer log, set dual_log_enable to YES.
wu-ftpd-compatible file transfer log is not important, either set xferlog_std_format to NO, comment the line with a hash sign (#), or delete the line entirely.
vsftpd interacts with the network.
accept_timeout — Specifies the amount of time for a client using passive mode to establish a connection.
60.
anon_max_rate — Specifies the maximum data transfer rate for anonymous users in bytes per second.
0, which does not limit the transfer rate.
connect_from_port_20 When enabled, vsftpd runs with enough privileges to open port 20 on the server during active mode data transfers. Disabling this option allows vsftpd to run with less privileges, but may be incompatible with some FTP clients.
NO. Note, in Fedora, the value is set to YES.
connect_timeout — Specifies the maximum amount of time a client using active mode has to respond to a data connection, in seconds.
60.
data_connection_timeout — Specifies maximum amount of time data transfers are allowed to stall, in seconds. Once triggered, the connection to the remote client is closed.
300.
ftp_data_port — Specifies the port used for active data connections when connect_from_port_20 is set to YES.
20.
idle_session_timeout — Specifies the maximum amount of time between commands from a remote client. Once triggered, the connection to the remote client is closed.
300.
listen_address — Specifies the IP address on which vsftpd listens for network connections.
vsftpd serving different IP addresses, the configuration file for each copy of the vsftpd daemon must have a different value for this directive. Refer to Раздел 16.2.4.1, «Starting Multiple Copies of vsftpd » for more information about multihomed FTP servers.
listen_address6 — Specifies the IPv6 address on which vsftpd listens for network connections when listen_ipv6 is set to YES.
vsftpd serving different IP addresses, the configuration file for each copy of the vsftpd daemon must have a different value for this directive. Refer to Раздел 16.2.4.1, «Starting Multiple Copies of vsftpd » for more information about multihomed FTP servers.
listen_port — Specifies the port on which vsftpd listens for network connections.
21.
local_max_rate — Specifies the maximum rate data is transferred for local users logged into the server in bytes per second.
0, which does not limit the transfer rate.
max_clients — Specifies the maximum number of simultaneous clients allowed to connect to the server when it is running in standalone mode. Any additional client connections would result in an error message.
0, which does not limit connections.
max_per_ip — Specifies the maximum of clients allowed to connected from the same source IP address.
0, which does not limit connections.
pasv_address — Specifies the IP address for the public facing IP address of the server for servers behind Network Address Translation (NAT) firewalls. This enables vsftpd to hand out the correct return address for passive mode connections.
pasv_enable — When enabled, passive mode connects are allowed.
YES.
pasv_max_port — Specifies the highest possible port sent to the FTP clients for passive mode connections. This setting is used to limit the port range so that firewall rules are easier to create.
0, which does not limit the highest passive port range. The value must not exceed 65535.
pasv_min_port — Specifies the lowest possible port sent to the FTP clients for passive mode connections. This setting is used to limit the port range so that firewall rules are easier to create.
0, which does not limit the lowest passive port range. The value must not be lower 1024.
pasv_promiscuous — When enabled, data connections are not checked to make sure they are originating from the same IP address. This setting is only useful for certain types of tunneling.
IP address as the control connection that initiates the data transfer.
NO.
port_enable — When enabled, active mode connects are allowed.
YES.
vsftpd, refer to the following resources.
/usr/share/doc/vsftpd-version-number/ directory — Replace version-number with the installed version of the vsftpd package. This directory contains a README with basic information about the software. The TUNING file contains basic performance tuning tips and the SECURITY/ directory contains information about the security model employed by vsftpd.
vsftpd related man pages — There are a number of man pages for the daemon and configuration files. The following lists some of the more important man pages.
man vsftpd — Describes available command line options for vsftpd.
man vsftpd.conf — Contains a detailed list of options available within the configuration file for vsftpd.
man 5 hosts_access — Describes the format and options available within the TCP wrappers configuration files: hosts.allow and hosts.deny.
vsftpd project page is a great place to locate the latest documentation and to contact the author of the software.
FTP.
FTP protocol from the IETF.
system-config-printer command from the command line to start the tool.
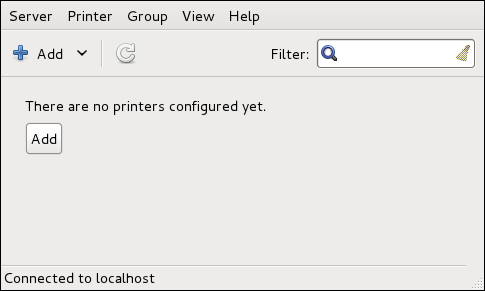
New Printer dialog (refer to Раздел 16.3.2, «Starting Printer Setup»).
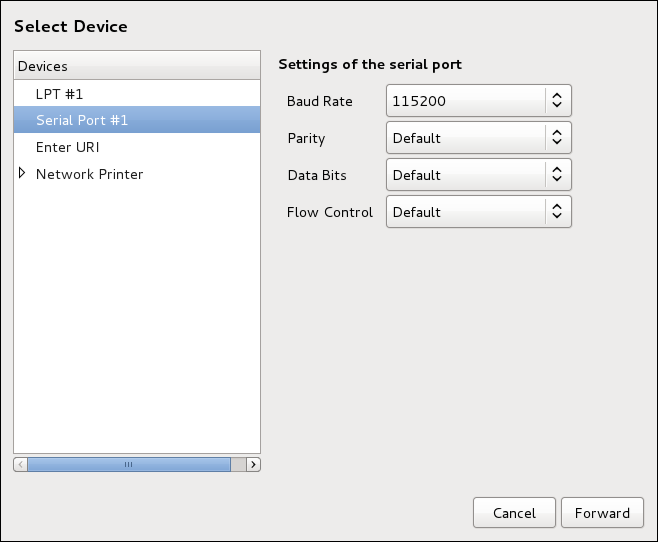
New Printer dialog (refer to Раздел 16.3.1, «Starting the Printer Configuration Tool»).
9100 by default)
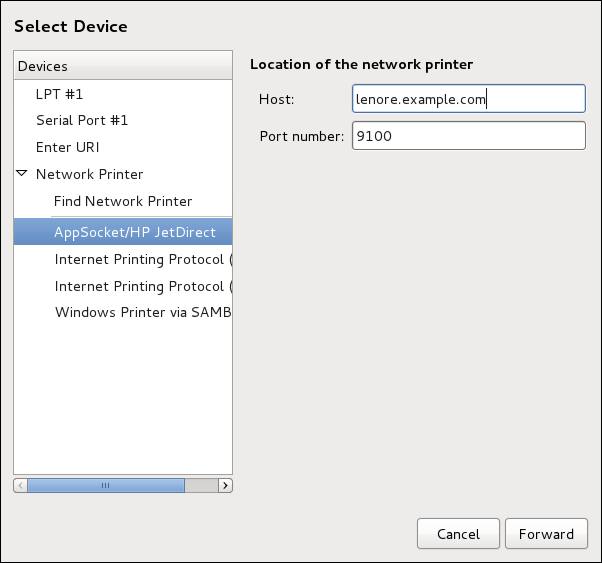
New Printer dialog (refer to Раздел 16.3.2, «Starting Printer Setup»).
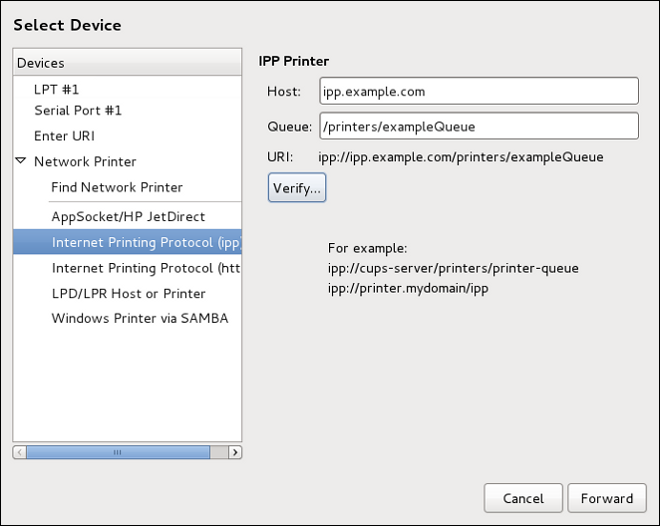
New Printer dialog (refer to Раздел 16.3.2, «Starting Printer Setup»).
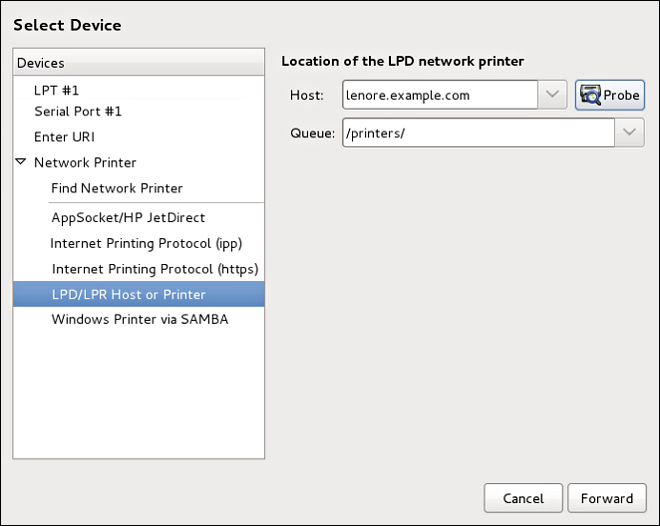
root:
yum install samba-clientNew Printer dialog (refer to Раздел 16.3.2, «Starting Printer Setup»).
computer name/printer share. In Рисунок 16.7, «Adding a SMB printer», the computer name is dellbox and the printer share is r2.
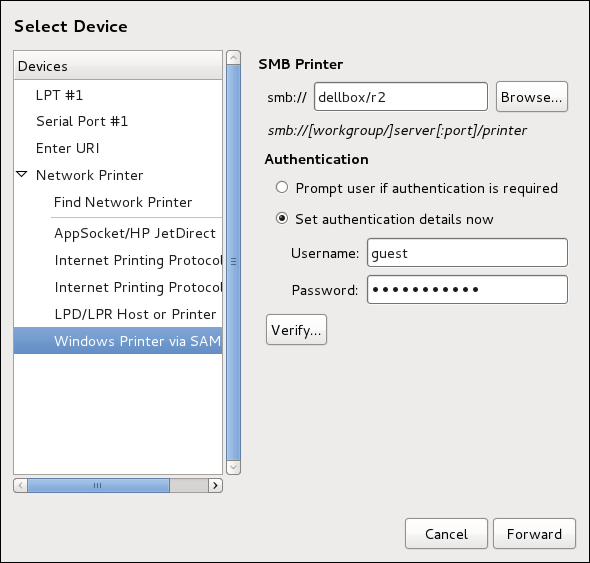
guest for Windows servers, or nobody for Samba servers.
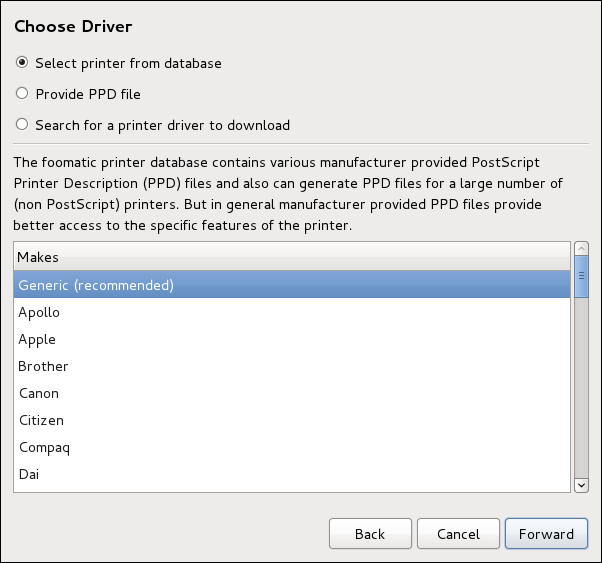
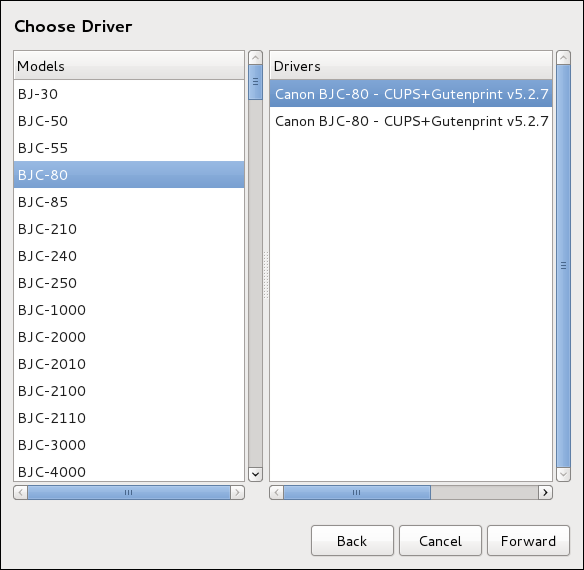
Describe Printer enter a unique name for the printer in the Printer Name field. The printer name can contain letters, numbers, dashes (-), and underscores (_); it must not contain any spaces. You can also use the Description and Location fields to add further printer information. Both fields are optional, and may contain spaces.
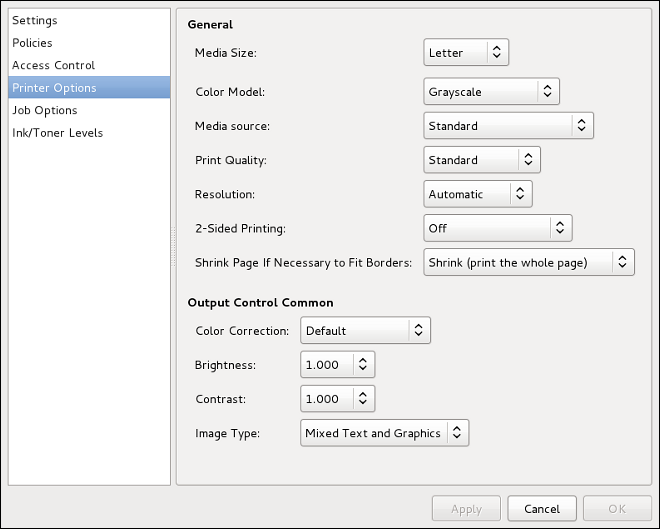
lpstat -o. The last few lines look similar to the following:
lpstat -o output$ lpstat -o
Charlie-60 twaugh 1024 Tue 08 Feb 2011 16:42:11 GMT
Aaron-61 twaugh 1024 Tue 08 Feb 2011 16:42:44 GMT
Ben-62 root 1024 Tue 08 Feb 2011 16:45:42 GMTlpstat -o and then use the command cancel job number. For example, cancel 60 would cancel the print job in Пример 16.1, «Example of lpstat -o output». You cannot cancel print jobs that were started by other users with the cancel command. However, you can enforce deletion of such job by issuing the cancel -U root job_number command. To prevent such canceling, change the printer operation policy to Authenticated to force root authentication.
lp sample.txt prints the text file sample.txt. The print filter determines what type of file it is and converts it into a format the printer can understand.
man lplpr command that allows you to print files from the command line.
man cancelman mpageman cupsdman cupsd.confman classes.confman lpstatlpstat command, which displays status information about classes, jobs, and printers.
Содержание
ps command allows you to display information about running processes. It produces a static list, that is, a snapshot of what is running when you execute the command. If you want a constantly updated list of running processes, use the top command or the System Monitor application instead.
psax
ps ax command displays the process ID (PID), the terminal that is associated with it (TTY), the current status (STAT), the cumulated CPU time (TIME), and the name of the executable file (COMMAND). For example:
~]$ ps ax
PID TTY STAT TIME COMMAND
1 ? Ss 0:02 /usr/lib/systemd/systemd --system --deserialize 20
2 ? S 0:00 [kthreadd]
3 ? S 0:00 [ksoftirqd/0]
5 ? S 0:00 [kworker/u:0]
6 ? S 0:00 [migration/0]
[output truncated]psaux
ps ax command, ps aux displays the effective username of the process owner (USER), the percentage of the CPU (%CPU) and memory (%MEM) usage, the virtual memory size in kilobytes (VSZ), the non-swapped physical memory size in kilobytes (RSS), and the time or date the process was started. For instance:
~]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.3 53128 2988 ? Ss 13:28 0:02 /usr/lib/systemd/systemd --system --deserialize 20
root 2 0.0 0.0 0 0 ? S 13:28 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 13:28 0:00 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S 13:28 0:00 [kworker/u:0]
root 6 0.0 0.0 0 0 ? S 13:28 0:00 [migration/0]
[output truncated]ps command in a combination with grep to see if a particular process is running. For example, to determine if Emacs is running, type:
~]$ ps ax | grep emacs
2625 ? Sl 0:00 emacstop command displays a real-time list of processes that are running on the system. It also displays additional information about the system uptime, current CPU and memory usage, or total number of running processes, and allows you to perform actions such as sorting the list or killing a process.
top command, type the following at a shell prompt:
toptop command displays the process ID (PID), the effective username of the process owner (USER), the priority (PR), the nice value (NI), the amount of virtual memory the process uses (VIRT), the amount of non-swapped physical memory the process uses (RES), the amount of shared memory the process uses (SHR), the percentage of the CPU (%CPU) and memory (%MEM) usage, the cumulated CPU time (TIME+), and the name of the executable file (COMMAND). For example:
~]$ top
top - 19:22:08 up 5:53, 3 users, load average: 1.08, 1.03, 0.82
Tasks: 117 total, 2 running, 115 sleeping, 0 stopped, 0 zombie
Cpu(s): 9.3%us, 1.3%sy, 0.0%ni, 85.1%id, 0.0%wa, 1.7%hi, 0.0%si, 2.6%st
Mem: 761956k total, 617256k used, 144700k free, 24356k buffers
Swap: 1540092k total, 55780k used, 1484312k free, 256408k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
510 john 20 0 1435m 99m 18m S 9.0 13.3 3:30.52 gnome-shell
32686 root 20 0 156m 27m 3628 R 2.0 3.7 0:48.69 Xorg
2625 john 20 0 488m 27m 14m S 0.3 3.7 0:00.70 emacs
1 root 20 0 53128 2640 1152 S 0.0 0.3 0:02.83 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.18 ksoftirqd/0
5 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kworker/u:0
6 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
7 root RT 0 0 0 0 S 0.0 0.0 0:00.30 watchdog/0
8 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 cpuset
9 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 khelper
10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
11 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 netns
12 root 20 0 0 0 0 S 0.0 0.0 0:00.11 sync_supers
13 root 20 0 0 0 0 S 0.0 0.0 0:00.00 bdi-default
14 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kintegrityd
15 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kblockdtop. For more information, refer to the top(1) manual page.
| Command | Описание |
|---|---|
| Enter, Space | Immediately refreshes the display. |
| h, ? | Displays a help screen. |
| k | Kills a process. You are prompted for the process ID and the signal to send to it. |
| n | Changes the number of displayed processes. You are prompted to enter the number. |
| u | Sorts the list by user. |
| M | Sorts the list by memory usage. |
| P | Sorts the list by CPU usage. |
| q | Terminates the utility and returns to the shell prompt. |
gnome-system-monitor at a shell prompt. Then click the Processes tab to view the list of running processes.
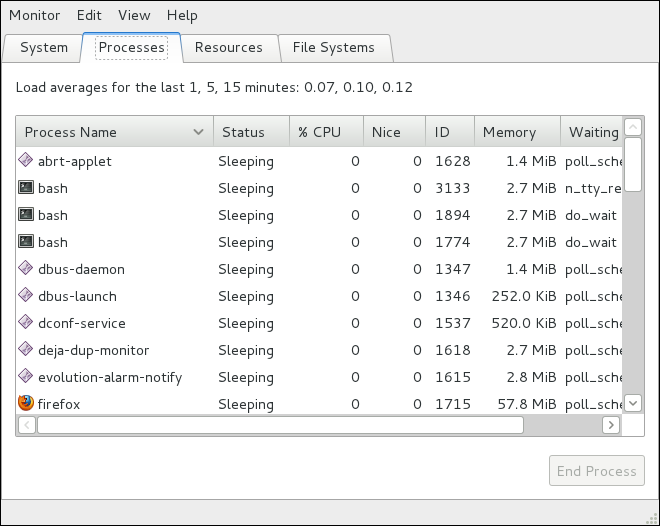
free command allows you to display the amount of free and used memory on the system. To do so, type the following at a shell prompt:
freefree command provides information about both the physical memory (Mem) and swap space (Swap). It displays the total amount of memory (total), as well as the amount of memory that is in use (used), free (free), shared (shared), in kernel buffers (buffers), and cached (cached). For example:
~]$ free
total used free shared buffers cached
Mem: 761956 607500 154456 0 37404 156176
-/+ buffers/cache: 413920 348036
Swap: 1540092 84408 1455684free displays the values in kilobytes. To display the values in megabytes, supply the -m command line option:
free-m
~]$ free -m
total used free shared buffers cached
Mem: 744 593 150 0 36 152
-/+ buffers/cache: 404 339
Swap: 1503 82 1421gnome-system-monitor at a shell prompt. Then click the Resources tab to view the system's memory usage.
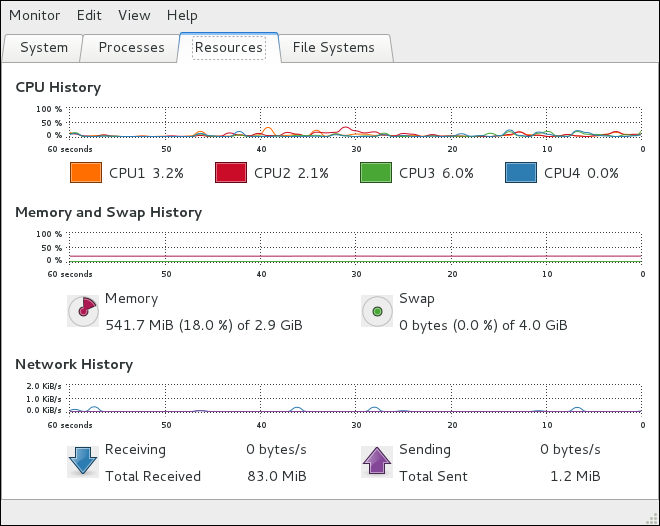
gnome-system-monitor at a shell prompt. Then click the Resources tab to view the system's CPU usage.
lsblk command allows you to display a list of available block devices. To do so, type the following at a shell prompt:
lsblklsblk command displays the device name (NAME), major and minor device number (MAJ:MIN), if the device is removable (RM), what is its size (SIZE), if the device is read-only (RO), what type is it (TYPE), and where the device is mounted (MOUNTPOINT). For example:
~]$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 20G 0 disk
|-vda1 252:1 0 500M 0 part /boot
`-vda2 252:2 0 19.5G 0 part
|-vg_fedora-lv_swap (dm-0) 253:0 0 1.5G 0 lvm [SWAP]
`-vg_fedora-lv_root (dm-1) 253:1 0 18G 0 lvm /lsblk lists block devices in a tree-like format. To display the information as an ordinary list, add the -l command line option:
lsblk-l
~]$ lsblk -l
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 20G 0 disk
vda1 252:1 0 500M 0 part /boot
vda2 252:2 0 19.5G 0 part
vg_fedora-lv_swap (dm-0) 253:0 0 1.5G 0 lvm [SWAP]
vg_fedora-lv_root (dm-1) 253:1 0 18G 0 lvm /blkid command allows you to display information about available block devices. To do so, type the following at a shell prompt as root:
blkidblkid command displays available attributes such as its universally unique identifier (UUID), file system type (TYPE), or volume label (LABEL). For example:
~]# blkid
/dev/vda1: UUID="4ea24c68-ab10-47d4-8a6b-b8d3a002acba" TYPE="ext4"
/dev/vda2: UUID="iJ9YwJ-leFf-A1zb-VVaK-H9t1-raLW-HoqlUG" TYPE="LVM2_member"
/dev/mapper/vg_fedora-lv_swap: UUID="d6d755bc-3e3e-4e8f-9bb5-a5e7f4d86ffd" TYPE="swap"
/dev/mapper/vg_fedora-lv_root: LABEL="_Fedora-17-x86_6" UUID="77ba9149-751a-48e0-974f-ad94911734b9" TYPE="ext4"lsblk command lists all available block devices. To display information about a particular device only, specify the device name on the command line:
blkiddevice_name
/dev/vda1, type:
~]# blkid /dev/vda1
/dev/vda1: UUID="4ea24c68-ab10-47d4-8a6b-b8d3a002acba" TYPE="ext4"-p and -o udev command line options to obtain more detailed information. Note that root privileges are required to run this command:
blkid-poudevdevice_name
~]# blkid -po udev /dev/vda1
ID_FS_UUID=4ea24c68-ab10-47d4-8a6b-b8d3a002acba
ID_FS_UUID_ENC=4ea24c68-ab10-47d4-8a6b-b8d3a002acba
ID_FS_VERSION=1.0
ID_FS_TYPE=ext4
ID_FS_USAGE=filesystem
ID_PART_ENTRY_SCHEME=dos
ID_PART_ENTRY_TYPE=0x83
ID_PART_ENTRY_FLAGS=0x80
ID_PART_ENTRY_NUMBER=1
ID_PART_ENTRY_OFFSET=2048
ID_PART_ENTRY_SIZE=1024000
ID_PART_ENTRY_DISK=252:0partx command allows you to display a list of disk partitions. To list the partition table of a particular disk, as root, run this command with the -s option followed by the device name:
partx-sdevice_name
/dev/vda, type:
~]# partx -s /dev/vda
NR START END SECTORS SIZE NAME UUID
1 2048 1026047 1024000 500M
2 1026048 41943039 40916992 19.5Gfindmnt command allows you to display a list of currently mounted file systems. To do so, type the following at a shell prompt:
findmntfindmnt command displays the target mount point (TARGET), source device (SOURCE), file system type (FSTYPE), and relevant mount options (OPTIONS). For example:
~]$ findmnt
TARGET SOURCE FSTYPE OPTIONS
/ /dev/mapper/vg_fedora-lv_root
ext4 rw,relatime,seclabel,data=o
|-/proc proc proc rw,nosuid,nodev,noexec,rela
| `-/proc/sys/fs/binfmt_misc systemd-1 autofs rw,relatime,fd=23,pgrp=1,ti
|-/sys sysfs sysfs rw,nosuid,nodev,noexec,rela
| |-/sys/kernel/security securityfs security rw,nosuid,nodev,noexec,rela
| |-/sys/fs/selinux selinuxfs selinuxf rw,relatime
| |-/sys/fs/cgroup tmpfs tmpfs rw,nosuid,nodev,noexec,secl
| | |-/sys/fs/cgroup/systemd cgroup cgroup rw,nosuid,nodev,noexec,rela
| | |-/sys/fs/cgroup/cpuset cgroup cgroup rw,nosuid,nodev,noexec,rela
| | |-/sys/fs/cgroup/cpu,cpuacct cgroup cgroup rw,nosuid,nodev,noexec,rela
| | |-/sys/fs/cgroup/memory cgroup cgroup rw,nosuid,nodev,noexec,rela
| | |-/sys/fs/cgroup/devices cgroup cgroup rw,nosuid,nodev,noexec,rela
| | |-/sys/fs/cgroup/freezer cgroup cgroup rw,nosuid,nodev,noexec,rela
| | |-/sys/fs/cgroup/net_cls cgroup cgroup rw,nosuid,nodev,noexec,rela
| | |-/sys/fs/cgroup/blkio cgroup cgroup rw,nosuid,nodev,noexec,rela
| | `-/sys/fs/cgroup/perf_event cgroup cgroup rw,nosuid,nodev,noexec,rela
| |-/sys/kernel/debug debugfs debugfs rw,relatime
| `-/sys/kernel/config configfs configfs rw,relatime
[output truncated]findmnt lists file systems in a tree-like format. To display the information as an ordinary list, add the -l command line option:
findmnt-l
~]$ findmnt -l
TARGET SOURCE FSTYPE OPTIONS
/proc proc proc rw,nosuid,nodev,noexec,relatime
/sys sysfs sysfs rw,nosuid,nodev,noexec,relatime,s
/dev devtmpfs devtmpfs rw,nosuid,seclabel,size=370080k,n
/dev/pts devpts devpts rw,nosuid,noexec,relatime,seclabe
/dev/shm tmpfs tmpfs rw,nosuid,nodev,seclabel
/run tmpfs tmpfs rw,nosuid,nodev,seclabel,mode=755
/ /dev/mapper/vg_fedora-lv_root
ext4 rw,relatime,seclabel,data=ordered
/sys/kernel/security securityfs security rw,nosuid,nodev,noexec,relatime
/sys/fs/selinux selinuxfs selinuxf rw,relatime
/sys/fs/cgroup tmpfs tmpfs rw,nosuid,nodev,noexec,seclabel,m
/sys/fs/cgroup/systemd cgroup cgroup rw,nosuid,nodev,noexec,relatime,r
[output truncated]-t command line option followed by a file system type:
findmnt-ttype
ext4 file systems, type:
~]$ findmnt -t ext4
TARGET SOURCE FSTYPE OPTIONS
/ /dev/mapper/vg_fedora-lv_root ext4 rw,relatime,seclabel,data=ordered
/boot /dev/vda1 ext4 rw,relatime,seclabel,data=ordereddf command allows you to display a detailed report on the system's disk space usage. To do so, type the following at a shell prompt:
dfdf command displays its name (Filesystem), size (1K-blocks or Size), how much space is used (Used), how much space is still available (Available), the percentage of space usage (Use%), and where is the file system mounted (Mounted on). For example:
~]$ df
Filesystem 1K-blocks Used Available Use% Mounted on
rootfs 18877356 4605476 14082844 25% /
devtmpfs 370080 0 370080 0% /dev
tmpfs 380976 256 380720 1% /dev/shm
tmpfs 380976 3048 377928 1% /run
/dev/mapper/vg_fedora-lv_root 18877356 4605476 14082844 25% /
tmpfs 380976 0 380976 0% /sys/fs/cgroup
tmpfs 380976 0 380976 0% /media
/dev/vda1 508745 85018 398127 18% /bootdf command shows the partition size in 1 kilobyte blocks and the amount of used and available disk space in kilobytes. To view the information in megabytes and gigabytes, supply the -h command line option, which causes df to display the values in a human-readable format:
df-h
~]$ df -h
Filesystem Size Used Avail Use% Mounted on
rootfs 19G 4.4G 14G 25% /
devtmpfs 362M 0 362M 0% /dev
tmpfs 373M 256K 372M 1% /dev/shm
tmpfs 373M 3.0M 370M 1% /run
/dev/mapper/vg_fedora-lv_root 19G 4.4G 14G 25% /
tmpfs 373M 0 373M 0% /sys/fs/cgroup
tmpfs 373M 0 373M 0% /media
/dev/vda1 497M 84M 389M 18% /boot/dev/shm entry represents the system's virtual memory file system, /sys/fs/cgroup is a cgroup file system, and /run contains information about the running system.
du command allows you to displays the amount of space that is being used by files in a directory. To display the disk usage for each of the subdirectories in the current working directory, run the command with no additional command line options:
du~]$ du
8 ./.gconf/apps/gnome-terminal/profiles/Default
12 ./.gconf/apps/gnome-terminal/profiles
16 ./.gconf/apps/gnome-terminal
[output truncated]
460 ./.gimp-2.6
68828 .du command displays the disk usage in kilobytes. To view the information in megabytes and gigabytes, supply the -h command line option, which causes the utility to display the values in a human-readable format:
du-h
~]$ du -h
8.0K ./.gconf/apps/gnome-terminal/profiles/Default
12K ./.gconf/apps/gnome-terminal/profiles
16K ./.gconf/apps/gnome-terminal
[output truncated]
460K ./.gimp-2.6
68M .du command always shows the grand total for the current directory. To display only this information, supply the -s command line option:
du-sh
~]$ du -sh
68M .gnome-system-monitor at a shell prompt. Then click the File Systems tab to view a list of file systems.
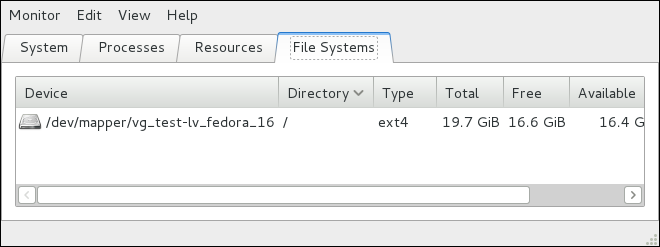
lspci command lists all PCI devices that are present in the system:
lspci~]$ lspci
00:00.0 Host bridge: Intel Corporation 82X38/X48 Express DRAM Controller
00:01.0 PCI bridge: Intel Corporation 82X38/X48 Express Host-Primary PCI Express Bridge
00:1a.0 USB Controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #4 (rev 02)
00:1a.1 USB Controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #5 (rev 02)
00:1a.2 USB Controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #6 (rev 02)
[output truncated]-v command line option to display more verbose output, or -vv for very verbose output:
lspci-v|-vv
~]$ lspci -v
[output truncated]
01:00.0 VGA compatible controller: nVidia Corporation G84 [Quadro FX 370] (rev a1) (prog-if 00 [VGA controller])
Subsystem: nVidia Corporation Device 0491
Physical Slot: 2
Flags: bus master, fast devsel, latency 0, IRQ 16
Memory at f2000000 (32-bit, non-prefetchable) [size=16M]
Memory at e0000000 (64-bit, prefetchable) [size=256M]
Memory at f0000000 (64-bit, non-prefetchable) [size=32M]
I/O ports at 1100 [size=128]
Expansion ROM at <unassigned> [disabled]
Capabilities: <access denied>
Kernel driver in use: nouveau
Kernel modules: nouveau, nvidiafb
[output truncated]lsusb command allows you to display information about USB buses and devices that are attached to them. To list all USB devices that are in the system, type the following at a shell prompt:
lsusb~]$ lsusb
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 002 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
[output truncated]
Bus 001 Device 002: ID 0bda:0151 Realtek Semiconductor Corp. Mass Storage Device (Multicard Reader)
Bus 008 Device 002: ID 03f0:2c24 Hewlett-Packard Logitech M-UAL-96 Mouse
Bus 008 Device 003: ID 04b3:3025 IBM Corp.-v command line option to display more verbose output:
lsusb-v
~]$ lsusb -v
[output truncated]
Bus 008 Device 002: ID 03f0:2c24 Hewlett-Packard Logitech M-UAL-96 Mouse
Device Descriptor:
bLength 18
bDescriptorType 1
bcdUSB 2.00
bDeviceClass 0 (Defined at Interface level)
bDeviceSubClass 0
bDeviceProtocol 0
bMaxPacketSize0 8
idVendor 0x03f0 Hewlett-Packard
idProduct 0x2c24 Logitech M-UAL-96 Mouse
bcdDevice 31.00
iManufacturer 1
iProduct 2
iSerial 0
bNumConfigurations 1
Configuration Descriptor:
bLength 9
bDescriptorType 2
[output truncated]lspcmcia command allows you to list all PCMCIA devices that are present in the system. To do so, type the following at a shell prompt:
lspcmcia~]$ lspcmcia
Socket 0 Bridge: [yenta_cardbus] (bus ID: 0000:15:00.0)-v command line option to display more verbose information, or -vv to increase the verbosity level even further:
lspcmcia-v|-vv
~]$ lspcmcia -v
Socket 0 Bridge: [yenta_cardbus] (bus ID: 0000:15:00.0)
Configuration: state: on ready: unknownlscpu command allows you to list information about CPUs that are present in the system, including the number of CPUs, their architecture, vendor, family, model, CPU caches, etc. To do so, type the following at a shell prompt:
lscpu~]$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 23
Stepping: 7
CPU MHz: 1998.000
BogoMIPS: 4999.98
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 3072K
NUMA node0 CPU(s): 0-3| Package | Provides |
|---|---|
| net-snmp | The SNMP Agent Daemon and documentation. This package is required for exporting performance data. |
| net-snmp-libs |
The netsnmp library and the bundled management information bases (MIBs). This package is required for exporting performance data.
|
| net-snmp-utils |
SNMP clients such as snmpget and snmpwalk. This package is required in order to query a system's performance data over SNMP.
|
| net-snmp-perl |
The mib2c utility and the NetSNMP Perl module.
|
| net-snmp-python | An SNMP client library for Python. |
yum command in the following form:
yuminstallpackage…
~]# yum install net-snmp net-snmp-libs net-snmp-utilsroot) to run this command. For more information on how to install new packages in Fedora, refer to Раздел 4.2.4, «Installing Packages».
snmpd, the SNMP Agent Daemon. This section provides information on how to start, stop, and restart the snmpd service, and shows how to enable or disable it in the multi-user target unit. For more information on the concept of target units and how to manage system services in Fedora in general, refer to Глава 8, Services and Daemons.
snmpd service in the current session, type the following at a shell prompt as root:
systemctlstartsnmpd.service
systemctlenablesnmpd.service
multi-user target unit.
snmpd service, type the following at a shell prompt as root:
systemctlstopsnmpd.service
systemctldisablesnmpd.service
multi-user target unit.
snmpd service, type the following at a shell prompt:
systemctlrestartsnmpd.service
systemctlreloadsnmpd.service
snmpd service to reload the configuration.
/etc/snmp/snmpd.conf configuration file. The default snmpd.conf file shipped with Fedora 17 is heavily commented and serves as a good starting point for agent configuration.
snmpconf which can be used to interactively generate a valid agent configuration.
snmpwalk utility described in this section.
snmpd service to re-read the configuration by running the following command as root:
systemctlreloadsnmpd.service
system tree. For example, the following snmpwalk command shows the system tree with a default agent configuration.
~]# snmpwalk -v2c -c public localhost system
SNMPv2-MIB::sysDescr.0 = STRING: Linux localhost.localdomain 2.6.32-122.el6.x86_64 #1 SMP Wed Mar 9 23:54:34 EST 2011 x86_64
SNMPv2-MIB::sysObjectID.0 = OID: NET-SNMP-MIB::netSnmpAgentOIDs.10
DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (99554) 0:16:35.54
SNMPv2-MIB::sysContact.0 = STRING: Root <root@localhost> (configure /etc/snmp/snmp.local.conf)
SNMPv2-MIB::sysName.0 = STRING: localhost.localdomain
SNMPv2-MIB::sysLocation.0 = STRING: Unknown (edit /etc/snmp/snmpd.conf)sysName object is set to the hostname. The sysLocation and sysContact objects can be configured in the /etc/snmp/snmpd.conf file by changing the value of the syslocation and syscontact directives, for example:
syslocation Datacenter, Row 3, Rack 2 syscontact UNIX Admin <admin@example.com>
snmpwalk command again:
~]#systemct reload snmpd.service~]#snmpwalk -v2c -c public localhost systemSNMPv2-MIB::sysDescr.0 = STRING: Linux localhost.localdomain 2.6.32-122.el6.x86_64 #1 SMP Wed Mar 9 23:54:34 EST 2011 x86_64 SNMPv2-MIB::sysObjectID.0 = OID: NET-SNMP-MIB::netSnmpAgentOIDs.10 DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (158357) 0:26:23.57 SNMPv2-MIB::sysContact.0 = STRING: UNIX Admin <admin@example.com> SNMPv2-MIB::sysName.0 = STRING: localhost.localdomain SNMPv2-MIB::sysLocation.0 = STRING: Datacenter, Row 3, Rack 2
rocommunity or rwcommunity directive in the /etc/snmp/snmpd.conf configuration file. The format of the directives is the following:
directivecommunity[source[OID]]
community is the community string to use, source is an IP address or subnet, and OID is the SNMP tree to provide access to. For example, the following directive provides read-only access to the system tree to a client using the community string «redhat» on the local machine:
rocommunity redhat 127.0.0.1 .1.3.6.1.2.1.1
snmpwalk command with the -v and -c options.
~]# snmpwalk -v2c -c redhat localhost system
SNMPv2-MIB::sysDescr.0 = STRING: Linux localhost.localdomain 2.6.32-122.el6.x86_64 #1 SMP Wed Mar 9 23:54:34 EST 2011 x86_64
SNMPv2-MIB::sysObjectID.0 = OID: NET-SNMP-MIB::netSnmpAgentOIDs.10
DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (158357) 0:26:23.57
SNMPv2-MIB::sysContact.0 = STRING: UNIX Admin <admin@example.com>
SNMPv2-MIB::sysName.0 = STRING: localhost.localdomain
SNMPv2-MIB::sysLocation.0 = STRING: Datacenter, Row 3, Rack 2net-snmp-create-v3-user command. This command adds entries to the /var/lib/net-snmp/snmpd.conf and /etc/snmp/snmpd.conf files which create the user and grant access to the user. Note that the net-snmp-create-v3-user command may only be run when the agent is not running. The following example creates the «sysadmin» user with the password «redhatsnmp»:
~]#systemctl stop snmpd.service~]#net-snmp-create-v3-userEnter a SNMPv3 user name to create: admin Enter authentication pass-phrase: redhatsnmp Enter encryption pass-phrase: [press return to reuse the authentication pass-phrase] adding the following line to /var/lib/net-snmp/snmpd.conf: createUser admin MD5 "redhatsnmp" DES adding the following line to /etc/snmp/snmpd.conf: rwuser admin ~]#systemctl start snmpd.service
rwuser directive (or rouser when the -ro command line option is supplied) that net-snmp-create-v3-user adds to /etc/snmp/snmpd.conf has a similar format to the rwcommunity and rocommunity directives:
directiveuser[noauth|auth|priv] [OID]
user is a username and OID is the SNMP tree to provide access to. By default, the Net-SNMP Agent Daemon allows only authenticated requests (the auth option). The noauth option allows you to permit unauthenticated requests, and the priv option enforces the use of encryption. The authpriv option specifies that requests must be authenticated and replies should be encrypted.
rwuser admin authpriv .1
.snmp directory in your user's home directory and a configuration file named snmp.conf in that directory (~/.snmp/snmp.conf) with the following lines:
defVersion 3 defSecurityLevel authPriv defSecurityName admin defPassphrase redhatsnmp
snmpwalk command will now use these authentication settings when querying the agent:
~]$ snmpwalk -v3 localhost system
SNMPv2-MIB::sysDescr.0 = STRING: Linux localhost.localdomain 2.6.32-122.el6.x86_64 #1 SMP Wed Mar 9 23:54:34 EST 2011 x86_64
[output truncated]Host Resources MIB included with Net-SNMP presents information about the current hardware and software configuration of a host to a client utility. Таблица 17.3, «Available OIDs» summarizes the different OIDs available under that MIB.
| OID | Описание |
|---|---|
HOST-RESOURCES-MIB::hrSystem
| Contains general system information such as uptime, number of users, and number of running processes. |
HOST-RESOURCES-MIB::hrStorage
| Contains data on memory and file system usage. |
HOST-RESOURCES-MIB::hrDevices
| Contains a listing of all processors, network devices, and file systems. |
HOST-RESOURCES-MIB::hrSWRun
| Contains a listing of all running processes. |
HOST-RESOURCES-MIB::hrSWRunPerf
| Contains memory and CPU statistics on the process table from HOST-RESOURCES-MIB::hrSWRun. |
HOST-RESOURCES-MIB::hrSWInstalled
| Contains a listing of the RPM database. |
HOST-RESOURCES-MIB::hrFSTable:
~]$ snmptable -Cb localhost HOST-RESOURCES-MIB::hrFSTable
SNMP table: HOST-RESOURCES-MIB::hrFSTable
Index MountPoint RemoteMountPoint Type
Access Bootable StorageIndex LastFullBackupDate LastPartialBackupDate
1 "/" "" HOST-RESOURCES-TYPES::hrFSLinuxExt2
readWrite true 31 0-1-1,0:0:0.0 0-1-1,0:0:0.0
5 "/dev/shm" "" HOST-RESOURCES-TYPES::hrFSOther
readWrite false 35 0-1-1,0:0:0.0 0-1-1,0:0:0.0
6 "/boot" "" HOST-RESOURCES-TYPES::hrFSLinuxExt2
readWrite false 36 0-1-1,0:0:0.0 0-1-1,0:0:0.0HOST-RESOURCES-MIB, see the /usr/share/snmp/mibs/HOST-RESOURCES-MIB.txt file.
UCD SNMP MIB. The systemStats OID provides a number of counters around processor usage:
~]$ snmpwalk localhost UCD-SNMP-MIB::systemStats
UCD-SNMP-MIB::ssIndex.0 = INTEGER: 1
UCD-SNMP-MIB::ssErrorName.0 = STRING: systemStats
UCD-SNMP-MIB::ssSwapIn.0 = INTEGER: 0 kB
UCD-SNMP-MIB::ssSwapOut.0 = INTEGER: 0 kB
UCD-SNMP-MIB::ssIOSent.0 = INTEGER: 0 blocks/s
UCD-SNMP-MIB::ssIOReceive.0 = INTEGER: 0 blocks/s
UCD-SNMP-MIB::ssSysInterrupts.0 = INTEGER: 29 interrupts/s
UCD-SNMP-MIB::ssSysContext.0 = INTEGER: 18 switches/s
UCD-SNMP-MIB::ssCpuUser.0 = INTEGER: 0
UCD-SNMP-MIB::ssCpuSystem.0 = INTEGER: 0
UCD-SNMP-MIB::ssCpuIdle.0 = INTEGER: 99
UCD-SNMP-MIB::ssCpuRawUser.0 = Counter32: 2278
UCD-SNMP-MIB::ssCpuRawNice.0 = Counter32: 1395
UCD-SNMP-MIB::ssCpuRawSystem.0 = Counter32: 6826
UCD-SNMP-MIB::ssCpuRawIdle.0 = Counter32: 3383736
UCD-SNMP-MIB::ssCpuRawWait.0 = Counter32: 7629
UCD-SNMP-MIB::ssCpuRawKernel.0 = Counter32: 0
UCD-SNMP-MIB::ssCpuRawInterrupt.0 = Counter32: 434
UCD-SNMP-MIB::ssIORawSent.0 = Counter32: 266770
UCD-SNMP-MIB::ssIORawReceived.0 = Counter32: 427302
UCD-SNMP-MIB::ssRawInterrupts.0 = Counter32: 743442
UCD-SNMP-MIB::ssRawContexts.0 = Counter32: 718557
UCD-SNMP-MIB::ssCpuRawSoftIRQ.0 = Counter32: 128
UCD-SNMP-MIB::ssRawSwapIn.0 = Counter32: 0
UCD-SNMP-MIB::ssRawSwapOut.0 = Counter32: 0ssCpuRawUser, ssCpuRawSystem, ssCpuRawWait, and ssCpuRawIdle OIDs provide counters which are helpful when determining whether a system is spending most of its processor time in kernel space, user space, or I/O. ssRawSwapIn and ssRawSwapOut can be helpful when determining whether a system is suffering from memory exhaustion.
UCD-SNMP-MIB::memory OID, which provides similar data to the free command:
~]$ snmpwalk localhost UCD-SNMP-MIB::memory
UCD-SNMP-MIB::memIndex.0 = INTEGER: 0
UCD-SNMP-MIB::memErrorName.0 = STRING: swap
UCD-SNMP-MIB::memTotalSwap.0 = INTEGER: 1023992 kB
UCD-SNMP-MIB::memAvailSwap.0 = INTEGER: 1023992 kB
UCD-SNMP-MIB::memTotalReal.0 = INTEGER: 1021588 kB
UCD-SNMP-MIB::memAvailReal.0 = INTEGER: 634260 kB
UCD-SNMP-MIB::memTotalFree.0 = INTEGER: 1658252 kB
UCD-SNMP-MIB::memMinimumSwap.0 = INTEGER: 16000 kB
UCD-SNMP-MIB::memBuffer.0 = INTEGER: 30760 kB
UCD-SNMP-MIB::memCached.0 = INTEGER: 216200 kB
UCD-SNMP-MIB::memSwapError.0 = INTEGER: noError(0)
UCD-SNMP-MIB::memSwapErrorMsg.0 = STRING:UCD SNMP MIB. The SNMP table UCD-SNMP-MIB::laTable has a listing of the 1, 5, and 15 minute load averages:
~]$ snmptable localhost UCD-SNMP-MIB::laTable
SNMP table: UCD-SNMP-MIB::laTable
laIndex laNames laLoad laConfig laLoadInt laLoadFloat laErrorFlag laErrMessage
1 Load-1 0.00 12.00 0 0.000000 noError
2 Load-5 0.00 12.00 0 0.000000 noError
3 Load-15 0.00 12.00 0 0.000000 noErrorHost Resources MIB provides information on file system size and usage. Each file system (and also each memory pool) has an entry in the HOST-RESOURCES-MIB::hrStorageTable table:
~]$ snmptable -Cb localhost HOST-RESOURCES-MIB::hrStorageTable
SNMP table: HOST-RESOURCES-MIB::hrStorageTable
Index Type Descr
AllocationUnits Size Used AllocationFailures
1 HOST-RESOURCES-TYPES::hrStorageRam Physical memory
1024 Bytes 1021588 388064 ?
3 HOST-RESOURCES-TYPES::hrStorageVirtualMemory Virtual memory
1024 Bytes 2045580 388064 ?
6 HOST-RESOURCES-TYPES::hrStorageOther Memory buffers
1024 Bytes 1021588 31048 ?
7 HOST-RESOURCES-TYPES::hrStorageOther Cached memory
1024 Bytes 216604 216604 ?
10 HOST-RESOURCES-TYPES::hrStorageVirtualMemory Swap space
1024 Bytes 1023992 0 ?
31 HOST-RESOURCES-TYPES::hrStorageFixedDisk /
4096 Bytes 2277614 250391 ?
35 HOST-RESOURCES-TYPES::hrStorageFixedDisk /dev/shm
4096 Bytes 127698 0 ?
36 HOST-RESOURCES-TYPES::hrStorageFixedDisk /boot
1024 Bytes 198337 26694 ?HOST-RESOURCES-MIB::hrStorageSize and HOST-RESOURCES-MIB::hrStorageUsed can be used to calculate the remaining capacity of each mounted file system.
UCD-SNMP-MIB::systemStats (ssIORawSent.0 and ssIORawRecieved.0) and in UCD-DISKIO-MIB::diskIOTable. The latter provides much more granular data. Under this table are OIDs for diskIONReadX and diskIONWrittenX, which provide counters for the number of bytes read from and written to the block device in question since the system boot:
~]$ snmptable -Cb localhost UCD-DISKIO-MIB::diskIOTable
SNMP table: UCD-DISKIO-MIB::diskIOTable
Index Device NRead NWritten Reads Writes LA1 LA5 LA15 NReadX NWrittenX
...
25 sda 216886272 139109376 16409 4894 ? ? ? 216886272 139109376
26 sda1 2455552 5120 613 2 ? ? ? 2455552 5120
27 sda2 1486848 0 332 0 ? ? ? 1486848 0
28 sda3 212321280 139104256 15312 4871 ? ? ? 212321280 139104256IF-MIB::ifTable provides an SNMP table with an entry for each interface on the system, the configuration of the interface, and various packet counters for the interface. The following example shows the first few columns of ifTable on a system with two physical network interfaces:
~]$ snmptable -Cb localhost IF-MIB::ifTable
SNMP table: IF-MIB::ifTable
Index Descr Type Mtu Speed PhysAddress AdminStatus
1 lo softwareLoopback 16436 10000000 up
2 eth0 ethernetCsmacd 1500 0 52:54:0:c7:69:58 up
3 eth1 ethernetCsmacd 1500 0 52:54:0:a7:a3:24 downIF-MIB::ifOutOctets and IF-MIB::ifInOctets. The following SNMP queries will retrieve network traffic for each of the interfaces on this system:
~]$snmpwalk localhost IF-MIB::ifDescrIF-MIB::ifDescr.1 = STRING: lo IF-MIB::ifDescr.2 = STRING: eth0 IF-MIB::ifDescr.3 = STRING: eth1 ~]$snmpwalk localhost IF-MIB::ifOutOctetsIF-MIB::ifOutOctets.1 = Counter32: 10060699 IF-MIB::ifOutOctets.2 = Counter32: 650 IF-MIB::ifOutOctets.3 = Counter32: 0 ~]$snmpwalk localhost IF-MIB::ifInOctetsIF-MIB::ifInOctets.1 = Counter32: 10060699 IF-MIB::ifInOctets.2 = Counter32: 78650 IF-MIB::ifInOctets.3 = Counter32: 0
NET-SNMP-EXTEND-MIB) that can be used to query arbitrary shell scripts. To specify the shell script to run, use the extend directive in the /etc/snmp/snmpd.conf file. Once defined, the Agent will provide the exit code and any output of the command over SNMP. The example below demonstrates this mechanism with a script which determines the number of httpd processes in the process table.
proc directive. Refer to the snmpd.conf(5) manual page for more information.
httpd processes running on the system at a given point in time:
#!/bin/sh NUMPIDS=`pgrep httpd | wc -l` exit $NUMPIDS
extend directive to the /etc/snmp/snmpd.conf file. The format of the extend directive is the following:
extendnameprogargs
name is an identifying string for the extension, prog is the program to run, and args are the arguments to give the program. For instance, if the above shell script is copied to /usr/local/bin/check_apache.sh, the following directive will add the script to the SNMP tree:
extend httpd_pids /bin/sh /usr/local/bin/check_apache.sh
NET-SNMP-EXTEND-MIB::nsExtendObjects:
~]$ snmpwalk localhost NET-SNMP-EXTEND-MIB::nsExtendObjects
NET-SNMP-EXTEND-MIB::nsExtendNumEntries.0 = INTEGER: 1
NET-SNMP-EXTEND-MIB::nsExtendCommand."httpd_pids" = STRING: /bin/sh
NET-SNMP-EXTEND-MIB::nsExtendArgs."httpd_pids" = STRING: /usr/local/bin/check_apache.sh
NET-SNMP-EXTEND-MIB::nsExtendInput."httpd_pids" = STRING:
NET-SNMP-EXTEND-MIB::nsExtendCacheTime."httpd_pids" = INTEGER: 5
NET-SNMP-EXTEND-MIB::nsExtendExecType."httpd_pids" = INTEGER: exec(1)
NET-SNMP-EXTEND-MIB::nsExtendRunType."httpd_pids" = INTEGER: run-on-read(1)
NET-SNMP-EXTEND-MIB::nsExtendStorage."httpd_pids" = INTEGER: permanent(4)
NET-SNMP-EXTEND-MIB::nsExtendStatus."httpd_pids" = INTEGER: active(1)
NET-SNMP-EXTEND-MIB::nsExtendOutput1Line."httpd_pids" = STRING:
NET-SNMP-EXTEND-MIB::nsExtendOutputFull."httpd_pids" = STRING:
NET-SNMP-EXTEND-MIB::nsExtendOutNumLines."httpd_pids" = INTEGER: 1
NET-SNMP-EXTEND-MIB::nsExtendResult."httpd_pids" = INTEGER: 8
NET-SNMP-EXTEND-MIB::nsExtendOutLine."httpd_pids".1 = STRING:extend directive. For example, the following shell script can be used to determine the number of processes matching an arbitrary string, and will also output a text string giving the number of processes:
#!/bin/sh PATTERN=$1 NUMPIDS=`pgrep $PATTERN | wc -l` echo "There are $NUMPIDS $PATTERN processes." exit $NUMPIDS
/etc/snmp/snmpd.conf directives will give both the number of httpd PIDs as well as the number of snmpd PIDs when the above script is copied to /usr/local/bin/check_proc.sh:
extend httpd_pids /bin/sh /usr/local/bin/check_proc.sh httpd extend snmpd_pids /bin/sh /usr/local/bin/check_proc.sh snmpd
snmpwalk of the nsExtendObjects OID:
~]$ snmpwalk localhost NET-SNMP-EXTEND-MIB::nsExtendObjects
NET-SNMP-EXTEND-MIB::nsExtendNumEntries.0 = INTEGER: 2
NET-SNMP-EXTEND-MIB::nsExtendCommand."httpd_pids" = STRING: /bin/sh
NET-SNMP-EXTEND-MIB::nsExtendCommand."snmpd_pids" = STRING: /bin/sh
NET-SNMP-EXTEND-MIB::nsExtendArgs."httpd_pids" = STRING: /usr/local/bin/check_proc.sh httpd
NET-SNMP-EXTEND-MIB::nsExtendArgs."snmpd_pids" = STRING: /usr/local/bin/check_proc.sh snmpd
NET-SNMP-EXTEND-MIB::nsExtendInput."httpd_pids" = STRING:
NET-SNMP-EXTEND-MIB::nsExtendInput."snmpd_pids" = STRING:
...
NET-SNMP-EXTEND-MIB::nsExtendResult."httpd_pids" = INTEGER: 8
NET-SNMP-EXTEND-MIB::nsExtendResult."snmpd_pids" = INTEGER: 1
NET-SNMP-EXTEND-MIB::nsExtendOutLine."httpd_pids".1 = STRING: There are 8 httpd processes.
NET-SNMP-EXTEND-MIB::nsExtendOutLine."snmpd_pids".1 = STRING: There are 1 snmpd processes.httpd processes. This query could be used during a performance test to determine the impact of the number of processes on memory pressure:
~]$snmpget localhost \'NET-SNMP-EXTEND-MIB::nsExtendResult."httpd_pids"' \UCD-SNMP-MIB::memAvailReal.0NET-SNMP-EXTEND-MIB::nsExtendResult."httpd_pids" = INTEGER: 8 UCD-SNMP-MIB::memAvailReal.0 = INTEGER: 799664 kB
extend directive is a fairly limited method for exposing custom application metrics over SNMP. The Net-SNMP Agent also provides an embedded Perl interface for exposing custom objects. The net-snmp-perl package provides the NetSNMP::agent Perl module that is used to write embedded Perl plug-ins on Fedora.
NetSNMP::agent Perl module provides an agent object which is used to handle requests for a part of the agent's OID tree. The agent object's constructor has options for running the agent as a sub-agent of snmpd or a standalone agent. No arguments are necessary to create an embedded agent:
use NetSNMP::agent (':all'); my $agent = new NetSNMP::agent();
agent object has a register method which is used to register a callback function with a particular OID. The register function takes a name, OID, and pointer to the callback function. The following example will register a callback function named hello_handler with the SNMP Agent which will handle requests under the OID .1.3.6.1.4.1.8072.9999.9999:
$agent->register("hello_world", ".1.3.6.1.4.1.8072.9999.9999", \&hello_handler);
.1.3.6.1.4.1.8072.9999.9999 (NET-SNMP-MIB::netSnmpPlaypen) is typically used for demonstration purposes only. If your organization does not already have a root OID, you can obtain one by contacting your Name Registration Authority (ANSI in the United States).
HANDLER, REGISTRATION_INFO, REQUEST_INFO, and REQUESTS. The REQUESTS parameter contains a list of requests in the current call and should be iterated over and populated with data. The request objects in the list have get and set methods which allow for manipulating the OID and value of the request. For example, the following call will set the value of a request object to the string «hello world»:
$request->setValue(ASN_OCTET_STR, "hello world");
getMode method on the request_info object passed as the third parameter to the handler function. If the request is a GET request, the caller will expect the handler to set the value of the request object, depending on the OID of the request. If the request is a GETNEXT request, the caller will also expect the handler to set the OID of the request to the next available OID in the tree. This is illustrated in the following code example:
my $request; my $string_value = "hello world"; my $integer_value = "8675309"; for($request = $requests; $request; $request = $request->next()) { my $oid = $request->getOID(); if ($request_info->getMode() == MODE_GET) { if ($oid == new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.0")) { $request->setValue(ASN_OCTET_STR, $string_value); } elsif ($oid == new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.1")) { $request->setValue(ASN_INTEGER, $integer_value); } } elsif ($request_info->getMode() == MODE_GETNEXT) { if ($oid == new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.0")) { $request->setOID(".1.3.6.1.4.1.8072.9999.9999.1.1"); $request->setValue(ASN_INTEGER, $integer_value); } elsif ($oid < new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.0")) { $request->setOID(".1.3.6.1.4.1.8072.9999.9999.1.0"); $request->setValue(ASN_OCTET_STR, $string_value); } } }
getMode returns MODE_GET, the handler analyzes the value of the getOID call on the request object. The value of the request is set to either string_value if the OID ends in «.1.0», or set to integer_value if the OID ends in «.1.1». If the getMode returns MODE_GETNEXT, the handler determines whether the OID of the request is «.1.0», and then sets the OID and value for «.1.1». If the request is higher on the tree than «.1.0», the OID and value for «.1.0» is set. This in effect returns the «next» value in the tree so that a program like snmpwalk can traverse the tree without prior knowledge of the structure.
NetSNMP::ASN. See the perldoc for NetSNMP::ASN for a full list of available constants.
#!/usr/bin/perl use NetSNMP::agent (':all'); use NetSNMP::ASN qw(ASN_OCTET_STR ASN_INTEGER); sub hello_handler { my ($handler, $registration_info, $request_info, $requests) = @_; my $request; my $string_value = "hello world"; my $integer_value = "8675309"; for($request = $requests; $request; $request = $request->next()) { my $oid = $request->getOID(); if ($request_info->getMode() == MODE_GET) { if ($oid == new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.0")) { $request->setValue(ASN_OCTET_STR, $string_value); } elsif ($oid == new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.1")) { $request->setValue(ASN_INTEGER, $integer_value); } } elsif ($request_info->getMode() == MODE_GETNEXT) { if ($oid == new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.0")) { $request->setOID(".1.3.6.1.4.1.8072.9999.9999.1.1"); $request->setValue(ASN_INTEGER, $integer_value); } elsif ($oid < new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.0")) { $request->setOID(".1.3.6.1.4.1.8072.9999.9999.1.0"); $request->setValue(ASN_OCTET_STR, $string_value); } } } } my $agent = new NetSNMP::agent(); $agent->register("hello_world", ".1.3.6.1.4.1.8072.9999.9999", \&hello_handler);
/usr/share/snmp/hello_world.pl and add the following line to the /etc/snmp/snmpd.conf configuration file:
perl do "/usr/share/snmp/hello_world.pl"
snmpwalk should return the new data:
~]$ snmpwalk localhost NET-SNMP-MIB::netSnmpPlaypen
NET-SNMP-MIB::netSnmpPlaypen.1.0 = STRING: "hello world"
NET-SNMP-MIB::netSnmpPlaypen.1.1 = INTEGER: 8675309snmpget should also be used to exercise the other mode of the handler:
~]$snmpget localhost \NET-SNMP-MIB::netSnmpPlaypen.1.0 \NET-SNMP-MIB::netSnmpPlaypen.1.1NET-SNMP-MIB::netSnmpPlaypen.1.0 = STRING: "hello world" NET-SNMP-MIB::netSnmpPlaypen.1.1 = INTEGER: 8675309
ps command.
top command.
free command.
df command.
du command.
lspci command.
snmpd service.
/etc/snmp/snmpd.conf file containing full documentation of available configuration directives.
rsyslogd. A list of log files maintained by rsyslogd can be found in the /etc/rsyslog.conf configuration file.
sysklogd daemon. rsyslog supports the same functionality as sysklogd and extends it with enhanced filtering, encryption protected relaying of messages, various configuration options, or support for transportation via the TCP or UDP protocols. Note that rsyslog is compatible with sysklogd.
/etc/rsyslog.conf. It consists of global directives, rules or comments (any empty lines or any text following a hash sign (#)). Both, global directives and rules are extensively described in the sections below.
rsyslogd daemon. They usually specify a value for a specific pre-defined variable that affects the behavior of the rsyslogd daemon or a rule that follows. All of the global directives must start with a dollar sign ($). Only one directive can be specified per line. The following is an example of a global directive that specifies the maximum size of the syslog message queue:
$MainMsgQueueSize 50000
10,000 messages) can be overridden by specifying a different value (as shown in the example above).
/etc/rsyslog.conf configuration file. A directive affects the behavior of all configuration options until another occurrence of that same directive is detected.
/usr/share/doc/rsyslog-<version-number>/rsyslog_conf_global.html.
$ModLoad <MODULE>
$ModLoad is the global directive that loads the specified module and <MODULE> represents your desired module. For example, if you want to load the Text File Input Module (imfile — enables rsyslog to convert any standard text files into syslog messages), specify the following line in your /etc/rsyslog.conf configuration file:
$ModLoad imfile
im prefix, such as imfile, imrelp, etc.
om prefix, such as omsnmp, omrelp, etc.
fm prefix.
pm prefix, such as pmrfc5424, pmrfc3164, etc.
sm prefix, such as smfile, smtradfile, etc.
/etc/rsyslog.conf configuration file, define both, a filter and an action, on one line and separate them with one or more spaces or tabs. For more information on filters, refer to Раздел 18.1.3.1, «Filter Conditions» and for information on actions, refer to Раздел 18.1.3.2, «Actions».
<FACILITY>.<PRIORITY>
<FACILITY> specifies the subsystem that produces a specific syslog message. For example, the mail subsystem handles all mail related syslog messages. <FACILITY> can be represented by one of these keywords: auth, authpriv, cron, daemon, kern, lpr, mail, news, syslog, user, uucp, and local0 through local7.
<PRIORITY> specifies a priority of a syslog message. <PRIORITY> can be represented by one of these keywords (listed in an ascending order): debug, info, notice, warning, err, crit, alert, and emerg.
=), you specify that only syslog messages with that priority will be selected. All other priorities will be ignored. Conversely, preceding a priority with an exclamation mark (!) selects all syslog messages but those with the defined priority. By not using either of these two extensions, you specify a selection of syslog messages with the defined or higher priority.
*) to define all facilities or priorities (depending on where you place the asterisk, before or after the dot). Specifying the keyword none serves for facilities with no given priorities.
,). To define multiple filters on one line, separate them with a semi-colon (;).
kern.* # Selects all kernel syslog messages with any priority
mail.crit # Selects all mail syslog messages with priority crit and higher.
cron.!info,!debug # Selects all cron syslog messages except those with theinfoordebugpriority.
timegenerated or syslogtag. For more information on properties, refer to Раздел 18.1.3.3.2, «Properties». Each of the properties specified in the filters lets you compare it to a specific value using one of the compare-operations listed in Таблица 18.1, «Property-based compare-operations».
| Compare-operation | Description |
|---|---|
contains
| Checks whether the provided string matches any part of the text provided by the property. |
isequal
| Compares the provided string against all of the text provided by the property. |
startswith
| Checks whether the provided string matches a prefix of the text provided by the property. |
regex
| Compares the provided POSIX BRE (Basic Regular Expression) regular expression against the text provided by the property. |
ereregex
| Compares the provided POSIX ERE (Extended Regular Expression) regular expression against the text provided by the property. |
:<PROPERTY>, [!]<COMPARE_OPERATION>, "<STRING>"
<PROPERTY> attribute specifies the desired property (for example, timegenerated, hostname, etc.).
!) negates the output of the compare-operation (if prefixing the compare-operation).
<COMPARE_OPERATION> attribute specifies one of the compare-operations listed in Таблица 18.1, «Property-based compare-operations».
<STRING> attribute specifies the value that the text provided by the property is compared to. To escape certain character (for example a quotation mark (")), use the backslash character (\).
error in their message text:
:msg, contains, "error"
host1:
:hostname, isequal, "host1"
fatal and error with any or no text between them (for example, fatal lib error):
:msg, !regex, "fatal .* error"
/usr/share/doc/rsyslog-<version-number>/rscript_abnf.html along with examples of various expression-based filters.
if<EXPRESSION>then<ACTION>
<EXPRESSION> attribute represents an expression to be evaluated, for example: $msg startswith 'DEVNAME' or $syslogfacility-text == 'local0'.
<ACTION> attribute represents an action to be performed if the expression returns the value true.
/etc/rsyslog.conf configuration file. Each block consists of rules which are preceded with a program or hostname label. Use the '!<PROGRAM>' or '-<PROGRAM>' labels to include or exclude programs, respectively. Use the '+<HOSTNAME> ' or '-<HOSTNAME> ' labels include or exclude hostnames, respectively.
!yum *.* /var/log/named.log
/var/log/cron.log log file:
cron.* /var/log/cron.log
-) as a prefix of the file path you specified if you want to omit syncing the desired log file after every syslog message is generated.
?) prefix. For more information on templates, refer to Раздел 18.1.3.3.1, «Generating dynamic file names».
/dev/console device, syslog messages are sent to standard output (using special tty-handling) or your console (using special /dev/console-handling) when using the X Window System, respectively.
@[(<OPTION>)]<HOST>:[<PORT>]
@) indicates that the syslog messages are forwarded to a host using the UDP protocol. To use the TCP protocol, use two at signs with no space between them (@@).
<OPTION> attribute can be replaced with an option such as z<NUMBER> . This option enables zlib compression for syslog messages; the <NUMBER> attribute specifies the level of compression. To define multiple options, simply separate each one of them with a comma (,).
<HOST> attribute specifies the host which receives the selected syslog messages.
<PORT> attribute specifies the host machine's port.
IPv6 address as the host, enclose the address in square brackets ([, ]).
*.* @192.168.0.1 # Forwards messages to 192.168.0.1 via the UDP protocol*.* @@example.com:18 # Forwards messages to "example.com" using port 18 and the TCP protocol
*.* @(z9)[2001::1] # Compresses messages with zlib (level 9 compression)
# and forwards them to 2001::1 using the UDP protocol$outchannel<NAME>,<FILE_NAME>,<MAX_SIZE>,<ACTION>
<NAME> attribute specifies the name of the output channel.
<FILE_NAME> attribute specifies the name of the output file.
<MAX_SIZE> attribute represents the maximum size the specified file (in <FILE_NAME>) can grow to. This value is specified in bytes.
<ACTION> attribute specifies the action that is taken when the maximum size, defined in <MAX_SIZE>, is hit.
$outchannel directive and then used in a rule which selects every syslog message with any priority and executes the previously-defined output channel on the acquired syslog messages. Once the limit (in the example 100 MB) is hit, the /home/joe/log_rotation_script is executed. This script can contain anything from moving the file into a different folder, editing specific content out of it, or simply removing it.
$outchannel log_rotation,/var/log/test_log.log, 104857600, /home/joe/log_rotation_script *.* $log_rotation
,). To send messages to every user that is currently logged on, use an asterisk (*).
system() call to execute the program in shell. To specify a program to be executed, prefix it with a caret character (^). Consequently, specify a template that formats the received message and passes it to the specified executable as a one line parameter (for more information on templates, refer to Раздел 18.1.3.3, «Templates»). In the following example, any syslog message with any priority is selected, formatted with the template template and passed as a parameter to the test-program program, which is then executed with the provided parameter:
*.* ^test-program;template
:<PLUGIN>:<DB_HOST>,<DB_NAME>,<DB_USER>,<DB_PASSWORD>;[<TEMPLATE>]
<PLUGIN> calls the specified plug-in that handles the database writing (for example, the ommysql plug-in).
<DB_HOST> attribute specifies the database hostname.
<DB_NAME> attribute specifies the name of the database.
<DB_USER> attribute specifies the database user.
<DB_PASSWORD> attribute specifies the password used with the aforementioned database user.
<TEMPLATE> attribute specifies an optional use of a template that modifies the syslog message. For more information on templates, refer to Раздел 18.1.3.3, «Templates».
MySQL (for more information, refer to /usr/share/doc/rsyslog-<version-number>/rsyslog_mysql.html) and PostgreSQL databases only. In order to use the MySQL and PostgreSQL database writer functionality, install the rsyslog-mysql and rsyslog-pgsql packages installed, respectively. Also, make sure you load the appropriate modules in your /etc/rsyslog.conf configuration file:
$ModLoad ommysql # Output module for MySQL support $ModLoad ompgsql # Output module for PostgreSQL support
omlibdb module. However, this module is currently not compiled.
~). The following rule discards any cron syslog messages:
cron.* ~
kern.=crit joe & ^test-program;temp & @192.168.0.1
crit) are send to user joe, processed by the template temp and passed on to the test-program executable, and forwarded to 192.168.0.1 via the UDP protocol.
;) and specify the name of the template.
$template<TEMPLATE_NAME>,"text %<PROPERTY>% more text", [<OPTION>]
$template is the template directive that indicates that the text following it, defines a template.
<TEMPLATE_NAME> is the name of the template. Use this name to refer to the template.
"…") is the actual template text. Within this text, you are allowed to escape characters in order to use their functionality, such as \n for new line or \r for carriage return. Other characters, such as % or ", have to be escaped in case you want to those characters literally.
%) specifies a property that is consequently replaced with the property's actual value. For more information on properties, refer to Раздел 18.1.3.3.2, «Properties»
<OPTION> attribute specifies any options that modify the template functionality. Do not mistake these for property options, which are defined inside the template text (between "…"). The currently supported template options are sql and stdsql used for formatting the text as an SQL query.
sql and stdsql options are specified in the template. If they are not, the database writer does not perform any action. This is to prevent any possible security threats, such as SQL injection.
timegenerated property to generate a unique file name for each syslog message:
$template DynamicFile,"/var/log/test_logs/%timegenerated%-test.log"
$template directive only specifies the template. You must use it inside a rule for it to take effect:
*.* ?DynamicFile
%)) allow you to access various contents of a syslog message through the use of a property replacer. To define a property inside a template (between the two quotation marks ("…")), use the following syntax:
%<PROPERTY_NAME>[:<FROM_CHAR>:<TO_CHAR>:<OPTION>]%
<PROPERTY_NAME> attribute specifies the name of a property. A comprehensible list of all available properties and their detailed description can be found in /usr/share/doc/rsyslog-<version-number>/property_replacer.html under the section Available Properties.
<FROM_CHAR> and <TO_CHAR> attributes denote a range of characters that the specified property will act upon. Alternatively, regular expressions can be used to specify a range of characters. To do so, specify the letter R as the <FROM_CHAR> attribute and specify your desired regular expression as the <TO_CHAR> attribute.
<OPTION> attribute specifies any property options. A comprehensible list of all available properties and their detailed description can be found in /usr/share/doc/rsyslog-<version-number>/property_replacer.html under the section Property Options.
%msg%
%msg:1:2%
%msg:::drop-last-lf%
%timegenerated:1:10:date-rfc3339%
$template verbose,"%syslogseverity%,%syslogfacility%,%timegenerated%,%HOSTNAME%,%syslogtag%,%msg%\n"
mesg(1) permission set to yes). This template outputs the message text, along with a hostname, message tag and a timestamp, on a new line (using \r and \n) and rings the bell (using \7).
$template wallmsg,"\r\n\7Message from syslogd@%HOSTNAME% at %timegenerated% ...\r\n %syslogtag% %msg%\n\r"
sql option at the end of the template specified as the template option. It tells the database writer to format the message as an MySQL SQL query.
$template dbFormat,"insert into SystemEvents (Message, Facility,FromHost, Priority, DeviceReportedTime, ReceivedAt, InfoUnitID, SysLogTag) values ('%msg%', %syslogfacility%, '%HOSTNAME%',%syslogpriority%, '%timereported:::date-mysql%', '%timegenerated:::date-mysql%', %iut%, '%syslogtag%')",sqlRSYSLOG_ prefix. It is advisable to not create a template using this prefix to avoid any conflicts. The following list shows these predefined templates along with their definitions.
RSYSLOG_DebugFormat"Debug line with all properties:\nFROMHOST: '%FROMHOST%', fromhost-ip: '%fromhost-ip%', HOSTNAME: '%HOSTNAME%', PRI: %PRI%,\nsyslogtag '%syslogtag%', programname: '%programname%', APP-NAME: '%APP-NAME%', PROCID: '%PROCID%', MSGID: '%MSGID%',\nTIMESTAMP: '%TIMESTAMP%', STRUCTURED-DATA: '%STRUCTURED-DATA%',\nmsg: '%msg%'\nescaped msg: '%msg:::drop-cc%'\nrawmsg: '%rawmsg%'\n\n\"
RSYSLOG_SyslogProtocol23Format"<%PRI%>1 %TIMESTAMP:::date-rfc3339% %HOSTNAME% %APP-NAME% %PROCID% %MSGID% %STRUCTURED-DATA% %msg%\n\"
RSYSLOG_FileFormat"%TIMESTAMP:::date-rfc3339% %HOSTNAME% %syslogtag%%msg:::sp-if-no-1st-sp%%msg:::drop-last-lf%\n\"
RSYSLOG_TraditionalFileFormat"%TIMESTAMP% %HOSTNAME% %syslogtag%%msg:::sp-if-no-1st-sp%%msg:::drop-last-lf%\n\"
RSYSLOG_ForwardFormat"<%PRI%>%TIMESTAMP:::date-rfc3339% %HOSTNAME% %syslogtag:1:32%%msg:::sp-if-no-1st-sp%%msg%\"
RSYSLOG_TraditionalForwardFormat"<%PRI%>%TIMESTAMP% %HOSTNAME% %syslogtag:1:32%%msg:::sp-if-no-1st-sp%%msg%\"
-c option. When no parameter is specified, rsyslog tries to be compatible with sysklogd. This is partially achieved by activating configuration directives that modify your configuration accordingly. Therefore, it is advisable to supply this option with a number that matches the major version of rsyslog that is in use and update your /etc/rsyslog.conf configuration file accordingly. If you want to, for example, use sysklogd options (which were deprecated in version 3 of rsyslog), you can specify so by executing the following command:
~]# rsyslogd -c 2
rsyslogd daemon, including the backward compatibility mode, can be specified in the /etc/sysconfig/rsyslog configuration file.
rsyslogd options, refer to man rsyslogd.
/var/log/ directory. Some applications such as httpd and samba have a directory within /var/log/ for their log files.
/var/log/ directory with numbers after them (for example, cron-20100906). These numbers represent a timestamp that has been added to a rotated log file. Log files are rotated so their file sizes do not become too large. The logrotate package contains a cron task that automatically rotates log files according to the /etc/logrotate.conf configuration file and the configuration files in the /etc/logrotate.d/ directory.
/etc/logrotate.conf configuration file:
# rotate log files weekly weekly # keep 4 weeks worth of backlogs rotate 4 # uncomment this if you want your log files compressed compress
.gz format. Any lines that begin with a hash sign (#) are comments and are not processed
/etc/logrotate.d/ directory and define any configuration options there.
/etc/logrotate.d/ directory:
/var/log/messages {
rotate 5
weekly
postrotate
/usr/bin/killall -HUP syslogd
endscript
}
/var/log/messages log file only. The settings specified here override the global settings where possible. Thus the rotated /var/log/messages log file will be kept for five weeks instead of four weeks as was defined in the global options.
weekly — Specifies the rotation of log files on a weekly basis. Similar directives include:
daily
monthly
yearly
compress — Enables compression of rotated log files. Similar directives include:
nocompress
compresscmd — Specifies the command to be used for compressing.
uncompresscmd
compressext — Specifies what extension is to be used for compressing.
compressoptions — Lets you specify any options that may be passed to the used compression program.
delaycompress — Postpones the compression of log files to the next rotation of log files.
rotate <INTEGER> — Specifies the number of rotations a log file undergoes before it is removed or mailed to a specific address. If the value 0 is specified, old log files are removed instead of rotated.
mail <ADDRESS> — This option enables mailing of log files that have been rotated as many times as is defined by the rotate directive to the specified address. Similar directives include:
nomail
mailfirst — Specifies that the just-rotated log files are to be mailed, instead of the about-to-expire log files.
maillast — Specifies that the just-rotated log files are to be mailed, instead of the about-to-expire log files. This is the default option when mail is enabled.
logrotate man page (man logrotate).
Vi or Emacs. Some log files are readable by all users on the system; however, root privileges are required to read most log files.
root:
yum install gnome-system-loggnome-system-log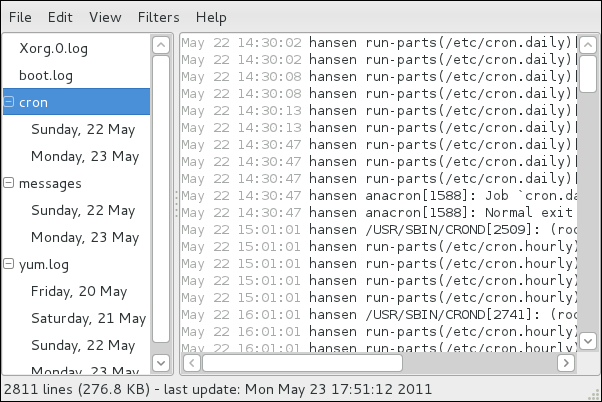
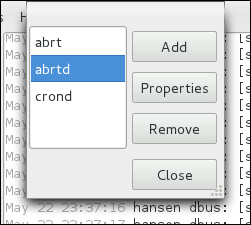
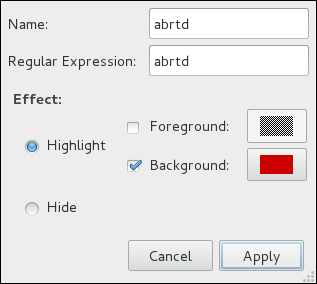
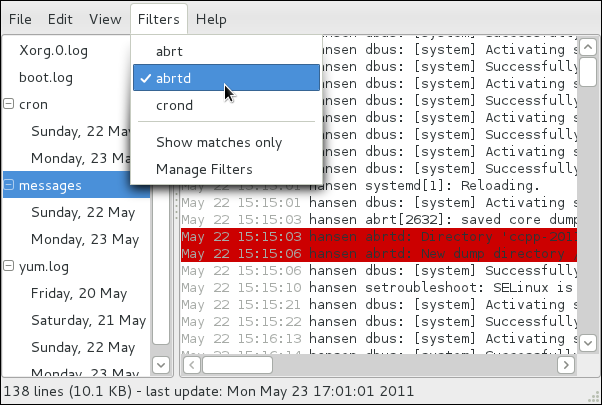
.gz format.
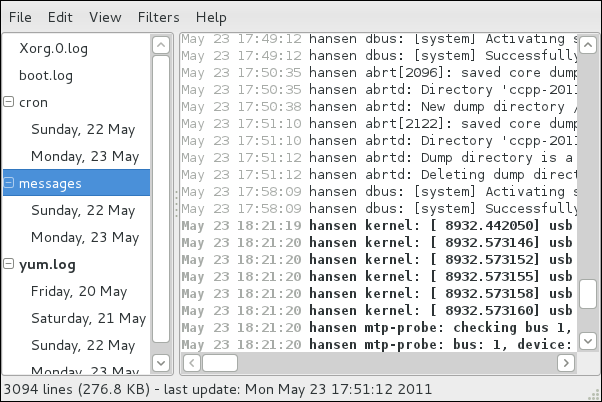
rsyslogd manual page — Type man rsyslogd to learn more about rsyslogd and its many options.
rsyslog.conf manual page — Type man rsyslog.conf to learn more about the /etc/rsyslog.conf configuration file and its many options.
/usr/share/doc/rsyslog-<version-number>/ — After installing the rsyslog package, this directory contains extensive documentation in the html format.
logrotate manual page — Type man logrotate to learn more about logrotate and its many options.
/etc/rsyslog.conf configuration examples.
locate command is updated daily. A system administrator can use automated tasks to perform periodic backups, monitor the system, run custom scripts, and more.
cron, at, and batch.
cronie RPM package must be installed and the crond service must be running. anacron is a sub-package of cronie. To determine if these packages are installed, use the rpm -q cronie cronie-anacron command.
systemctl is-active crond.serviceroot:
systemctl start crond.serviceroot:
systemctl stop crond.serviceroot:
systemctl enable crond.service/etc/anacrontab (only root is allowed to modify this file), which contains the following lines:
SHELL=/bin/sh PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root # the maximal random delay added to the base delay of the jobs RANDOM_DELAY=45 # the jobs will be started during the following hours only START_HOURS_RANGE=3-22 #period in days delay in minutes job-identifier command 1 5 cron.daily nice run-parts /etc/cron.daily 7 25 cron.weekly nice run-parts /etc/cron.weekly @monthly 45 cron.monthly nice run-parts /etc/cron.monthly
SHELL variable tells the system which shell environment to use (in this example the bash shell). The PATH variable defines the path used to execute commands. The output of the anacron jobs are emailed to the username defined with the MAILTO variable. If the MAILTO variable is not defined, (i.e. is empty, MAILTO=), email is not sent.
RANDOM_DELAY variable denotes the maximum number of minutes that will be added to the delay in minutes variable which is specified for each job. The minimum delay value is set, by default, to 6 minutes. A RANDOM_DELAY set to 12 would therefore add, randomly, between 6 and 12 minutes to the delay in minutes for each job in that particular anacrontab. RANDOM_DELAY can also be set to a value below 6, or even 0. When set to 0, no random delay is added. This proves to be useful when, for example, more computers that share one network connection need to download the same data every day. The START_HOURS_RANGE variable defines an interval (in hours) when scheduled jobs can be run. In case this time interval is missed, for example, due to a power down, then scheduled jobs are not executed that day.
/etc/anacrontab file represent scheduled jobs and have the following format:
period in days delay in minutes job-identifier command
period in days — specifies the frequency of execution of a job in days. This variable can be represented by an integer or a macro (@daily, @weekly, @monthly), where @daily denotes the same value as the integer 1, @weekly the same as 7, and @monthly specifies that the job is run once a month, independent on the length of the month.
delay in minutes — specifies the number of minutes anacron waits, if necessary, before executing a job. This variable is represented by an integer where 0 means no delay.
job-identifier — specifies a unique name of a job which is used in the log files.
command — specifies the command to execute. The command can either be a command such as ls /proc >> /tmp/proc or a command to execute a custom script.
/etc/anacrontab file:
SHELL=/bin/sh PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root # the maximal random delay added to the base delay of the jobs RANDOM_DELAY=30 # the jobs will be started during the following hours only START_HOURS_RANGE=16-20 #period in days delay in minutes job-identifier command 1 20 dailyjob nice run-parts /etc/cron.daily 7 25 weeklyjob /etc/weeklyjob.bash @monthly 45 monthlyjob ls /proc >> /tmp/proc
anacrontab file are randomly delayed by 6-30 minutes and can be executed between 16:00 and 20:00. Thus, the first defined job will run anywhere between 16:26 and 16:50 every day. The command specified for this job will execute all present programs in the /etc/cron.daily directory (using the run-parts script which takes a directory as a command-line argument and sequentially executes every program within that directory). The second specified job will be executed once a week and will execute the weeklyjob.bash script in the /etc directory. The third job is executed once a month and runs a command to write the contents of the /proc to the /tmp/proc file (e.g. ls /proc >> /tmp/proc).
cronie-anacron package. Thus, you will be able to define jobs using crontabs only.
/etc/crontab (only root is allowed to modify this file), contains the following lines:
SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root HOME=/ # For details see man 4 crontabs # Example of job definition: # .---------------- minute (0 - 59) # | .------------- hour (0 - 23) # | | .---------- day of month (1 - 31) # | | | .------- month (1 - 12) OR jan,feb,mar,apr ... # | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat # | | | | | # * * * * * user command to be executed
anacrontab file, SHELL, PATH and MAILTO. For more information about these variables, refer to Раздел 19.1.2, «Configuring Anacron Jobs». The fourth line contains the HOME variable. The HOME variable can be used to set the home directory to use when executing commands or scripts.
/etc/crontab file represent scheduled jobs and have the following format:
minute hour day month day of week user command
minute — any integer from 0 to 59
hour — any integer from 0 to 23
day — any integer from 1 to 31 (must be a valid day if a month is specified)
month — any integer from 1 to 12 (or the short name of the month such as jan or feb)
day of week — any integer from 0 to 7, where 0 or 7 represents Sunday (or the short name of the week such as sun or mon)
user — specifies the user under which the jobs are run
command — the command to execute (the command can either be a command such as ls /proc >> /tmp/proc or the command to execute a custom script)
1-4 means the integers 1, 2, 3, and 4.
3, 4, 6, 8 indicates those four specific integers.
/integer. For example, 0-59/2 can be used to define every other minute in the minute field. Step values can also be used with an asterisk. For instance, the value */3 can be used in the month field to run the task every third month.
root can configure cron tasks by using the crontab utility. All user-defined crontabs are stored in the /var/spool/cron/ directory and are executed using the usernames of the users that created them. To create a crontab as a user, login as that user and type the command crontab -e to edit the user's crontab using the editor specified by the VISUAL or EDITOR environment variable. The file uses the same format as /etc/crontab. When the changes to the crontab are saved, the crontab is stored according to username and written to the file /var/spool/cron/username . To list the contents of your own personal crontab file, use the crontab -l command.
crontab utility, there is no need to specify a user when defining a job.
/etc/cron.d/ directory contains files that have the same syntax as the /etc/crontab file. Only root is allowed to create and modify files in this directory.
/etc/anacrontab file, the /etc/crontab file, the /etc/cron.d/ directory, and the /var/spool/cron/ directory every minute for any changes. If any changes are found, they are loaded into memory. Thus, the daemon does not need to be restarted if an anacrontab or a crontab file is changed.
/etc/cron.allow and /etc/cron.deny files are used to restrict access to cron. The format of both access control files is one username on each line. Whitespace is not permitted in either file. The cron daemon (crond) does not have to be restarted if the access control files are modified. The access control files are checked each time a user tries to add or delete a cron job.
root user can always use cron, regardless of the usernames listed in the access control files.
cron.allow exists, only users listed in it are allowed to use cron, and the cron.deny file is ignored.
cron.allow does not exist, users listed in cron.deny are not allowed to use cron.
/etc/security/access.conf. For example, adding the following line in this file forbids creating crontabs for all users except the root user:
-:ALL EXCEPT root :cron
access.conf.5 (i.e. man 5 access.conf).
run-parts script on a cron folder, such as /etc/cron.daily, we can define which of the programs in this folder will not be executed by run-parts.
jobs.deny file in the folder that run-parts will be executing from. For example, if we need to omit a particular program from /etc/cron.daily, then, a file /etc/cron.daily/jobs.deny has to be created. In this file, specify the names of the omitted programs from the same directory. These will not be executed when a command, such as run-parts /etc/cron.daily, is executed by a specific job.
jobs.allow file.
jobs.deny and jobs.allow are the same as those of cron.deny and cron.allow described in section Раздел 19.1.4, «Controlling Access to Cron».
at command is used to schedule a one-time task at a specific time and the batch command is used to schedule a one-time task to be executed when the systems load average drops below 0.8.
at or batch, the at RPM package must be installed, and the atd service must be running. To determine if the package is installed, use the rpm -q at command. To determine if the service is running, use the following command:
systemctl is-active atd.serviceat time , where time time can be one of the following:
/usr/share/doc/at-version/timespec text file.
at command with the time argument, the at> prompt is displayed. Type the command to execute, press Enter, and press Ctrl+D . Multiple commands can be specified by typing each command followed by the Enter key. After typing all the commands, press Enter to go to a blank line and press Ctrl+D . Alternatively, a shell script can be entered at the prompt, pressing Enter after each line in the script, and pressing Ctrl+D on a blank line to exit. If a script is entered, the shell used is the shell set in the user's SHELL environment, the user's login shell, or /bin/sh (whichever is found first).
atq to view pending jobs. Refer to Раздел 19.2.3, «Viewing Pending Jobs» for more information.
at command can be restricted. For more information, refer to Раздел 19.2.5, «Controlling Access to At and Batch» for details.
batch command.
batch command, the at> prompt is displayed. Type the command to execute, press Enter, and press Ctrl+D . Multiple commands can be specified by typing each command followed by the Enter key. After typing all the commands, press Enter to go to a blank line and press Ctrl+D . Alternatively, a shell script can be entered at the prompt, pressing Enter after each line in the script, and pressing Ctrl+D on a blank line to exit. If a script is entered, the shell used is the shell set in the user's SHELL environment, the user's login shell, or /bin/sh (whichever is found first). As soon as the load average is below 0.8, the set of commands or script is executed.
atq to view pending jobs. Refer to Раздел 19.2.3, «Viewing Pending Jobs» for more information.
batch command can be restricted. For more information, refer to Раздел 19.2.5, «Controlling Access to At and Batch» for details.
at and batch jobs, use the atq command. The atq command displays a list of pending jobs, with each job on a line. Each line follows the job number, date, hour, job class, and username format. Users can only view their own jobs. If the root user executes the atq command, all jobs for all users are displayed.
at and batch include:
at and batch Command Line Options| Option | Description |
|---|---|
-f
| Read the commands or shell script from a file instead of specifying them at the prompt. |
-m
| Send email to the user when the job has been completed. |
-v
| Display the time that the job is executed. |
/etc/at.allow and /etc/at.deny files can be used to restrict access to the at and batch commands. The format of both access control files is one username on each line. Whitespace is not permitted in either file. The at daemon (atd) does not have to be restarted if the access control files are modified. The access control files are read each time a user tries to execute the at or batch commands.
root user can always execute at and batch commands, regardless of the access control files.
at.allow exists, only users listed in it are allowed to use at or batch, and the at.deny file is ignored.
at.allow does not exist, users listed in at.deny are not allowed to use at or batch.
at service, use the following command as root:
systemctl start atd.serviceroot, type the following at a shell prompt:
systemctl stop atd.serviceroot:
systemctl enable atd.servicecron man page — contains an overview of cron.
crontab man pages in sections 1 and 5 — The man page in section 1 contains an overview of the crontab file. The man page in section 5 contains the format for the file and some example entries.
anacron man page — contains an overview of anacron.
anacrontab man page — contains an overview of the anacrontab file.
/usr/share/doc/at-version/timespec contains more detailed information about the times that can be specified for cron jobs.
at man page — description of at and batch and their command line options.
abrtd, который большую часть времени работает в фоновом режиме. Когда происходит сбой приложения или ошибка ядра (kernel oops), то демон активируется. Затем он собирает необходимые дополнительные данные, такие как core-файл, если таковой имеется, параметры командной строки и другие данные о приложении.
FTP/SCP, отправлены по электронной почте или записаны в файл.
abrtd — демон ABRT, работающий под рутом в фоновом режиме.
abrt-ccpp — сервис ABRT, отвечающий за анализ проблем на C/C++
abrt-oops — сервис ABRT, отвечающий за обработку ошибок ядра (kernel oops).
~]# yum install abrt-desktop~]# yum install abrt-cliabrtd запущен. Обычно демон настраивается на запуск во время загрузки системы. Вы можете использовать следующую команду, чтобы проверить текущий статус:
~]# service abrtd status
abrtd (pid 1535) is running...service возвращает сообщение abrt is stopped, это означает, что демон не запущен. Вы можете запустить его в рамках текущей сессии следующей командой:
~]# service abrtd start
Starting abrt daemon: [ OK ]chkconfig, чтобы убедиться, что abrtd будет стартовать при каждом запуске системы:
~]# chkconfig abrtd onabrt-ccpp, если вы хотите, чтобы программа ABRT отслеживала ошибки на C/C++. Чтобы ABRT определяла и ошибки ядра, используйте те же рекомендации для сервиса abrt-oops. Обратите внимание, что сервис не может отслеживать ошибки ядра, приводящие к состоянию, в котором невозможно получить отклик системы или к немедленной перезагрузке.
апплет уведомлений ABRT запущен:
~]$ ps -el | grep abrt-applet
0 S 500 2036 1824 0 80 0 - 61604 poll_s ? 00:00:00 abrt-appletabrt-applet:
~]$ abrt-applet &
[1] 2261
analyzer
architecture
coredump
cmdline
executable
kernel
os_release
reason
time
uid
backtrace, могут быть созданы во время анализа в зависимости от используемого метода и настроек. Каждый из этих файлов содержит специфичную информацию о системе и ошибке. Например, в файле kernel содержится версия ядра, вызвавшего ошибку.
~]$ abrt-gui &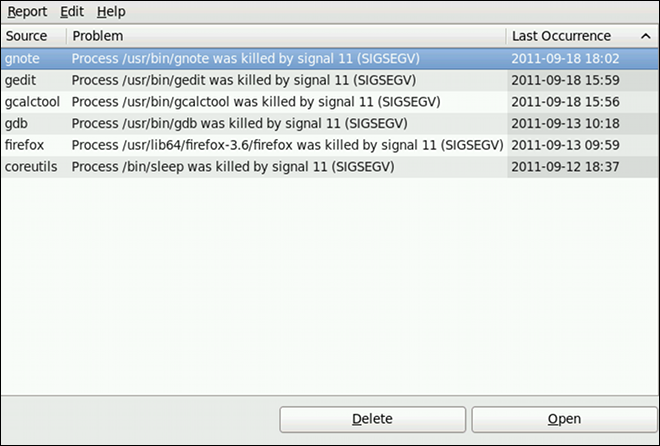
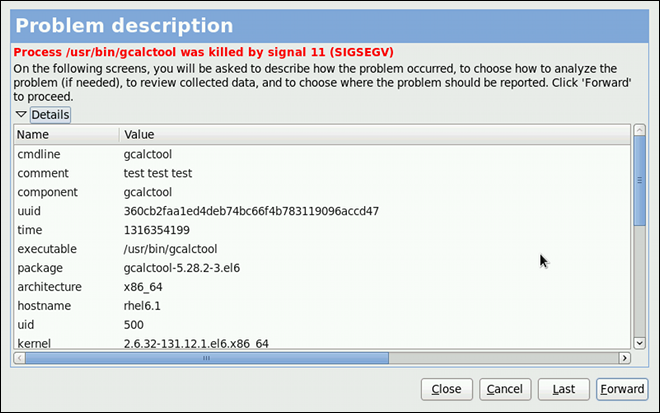
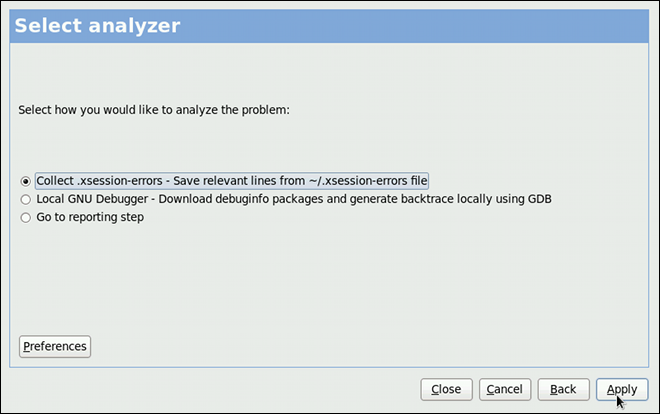
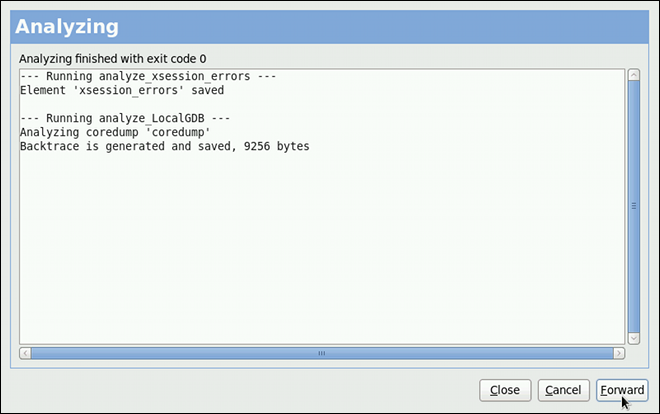
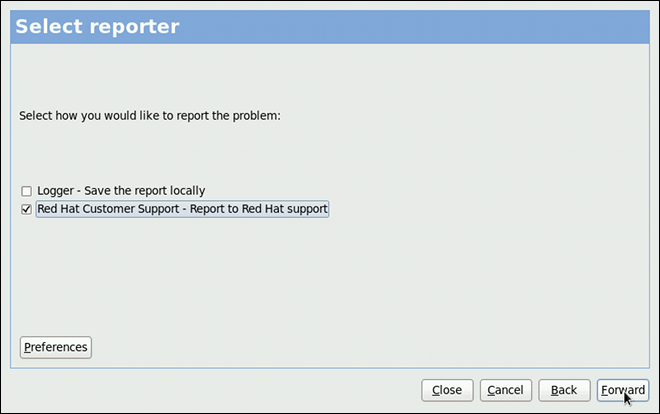
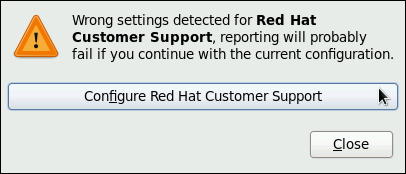
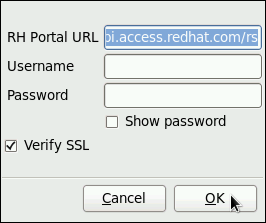
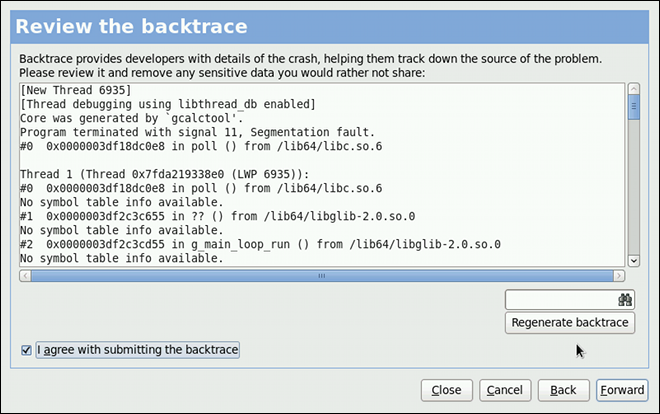
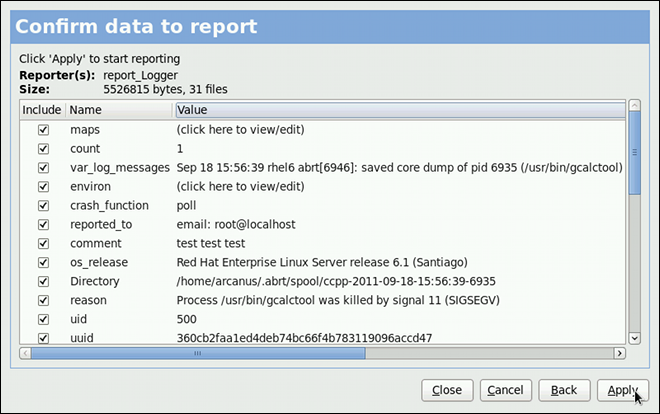
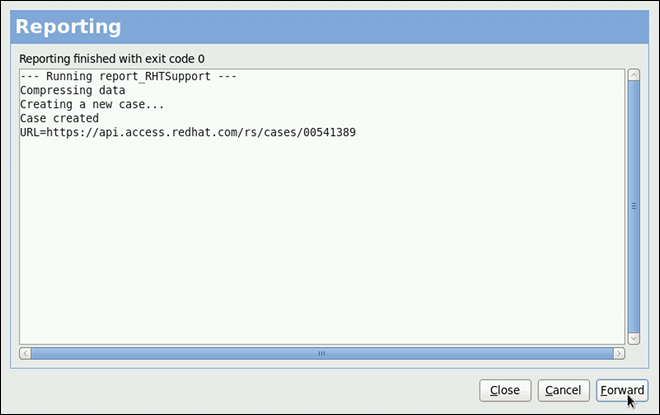
abrtd можно просматривать, сообщать и удалять в режиме командной строки.
abrt-cli[--version]<command>[<args>]
<args> означает директорию с данными по ошибке и/или опции, модифицирующие команду, а <command> является одной из следующих подкоманд:
list — отображает список ошибок и информацию по ошибкам.
report — анализирует ошибки и сообщает о них.
rm — удаляет ненужные ошибки.
info — предоставляет информацию о конкретной ошибке.
abrt-cli используйте:
abrt-cli <command> --help abrt-cli list:
~]# abrt-cli list
Directory: /var/spool/abrt/ccpp-2011-09-13-10:18:14-2895
count: 2
executable: /usr/bin/gdb
package: gdb-7.2-48.el6
time: Tue 13 Sep 2011 10:18:14 AM CEST
uid: 500
Directory: /var/spool/abrt/ccpp-2011-09-21-18:18:07-2841
count: 1
executable: /bin/bash
package: bash-4.1.2-8.el6
time: Wed 21 Sep 2011 06:18:07 PM CEST
uid: 500Directory — отображает директорию с данными по ошибке, содержающую всю информацию по проблеме.
count — показывает как много раз встречалась конкретная проблема.
executable — отображает бинарный или исполняемый файл вызвал ошибку.
package — показывает имя пакета, который содержит программу, вызвавшую ошибку.
time — показывает дату и время последнего возникновения ошибки.
uid — показывает ID пользователя, который запустил прогрмму, вызвавшую ошибку.
abrt-cli list. Все они взаимно совместимы, поэтому вы можете комбинировать их в зависимости от необходимости. Вывод команды будет наиболее всесторонним, если вы скомбинируете все опции или, наоборот, вы получите меньше всего подробностей, если вообще не будете использовать дополнительные опции.
abrt-cli list| Опция | Описание |
|---|---|
Без дополнительных опций команда abrt-cli list отображает только основную информацию по ошибкам, о которых еще не были отправлены отчеты.
| |
-d, --detailed
|
Отображает всю собранную информацию по перечисленным ошибкам, включая backtrace, если она уже была сгенерирована.
|
-f, --full
| Отображает основную информацию по всем проблемам, включая те, о которых уже были отправлены отчеты. |
-v, --verbose
| Выводит дополнительную информацию о действиях. |
abrt-cli info<DIR>
<DIR> обозначает директорию с информацией об ошибке для просмотра. В таблице ниже приведены опции, используемые с командой abrt-cli info. Все они взаимно совместимы, поэтому вы можете комбинировать их в зависимости от необходимости. Вывод команды будет наиболее всесторонним, если вы скомбинируете все опции или, наоборот, вы получите меньше всего подробностей, если вообще не будете использовать дополнительные опции.
abrt-cli info| Опция | Описание |
|---|---|
Без дополнительных опций команда abrt-cli info отображает только базовую информацию по ошибке, заданной аргументом с директорией, содержащей информацию по проблеме.
| |
-d, --detailed
|
Отображает всю собранную информацию по перечисленным ошибкам, включая backtrace, если она уже была сгенерирована.
|
-v, --verbose
|
abrt-cli info выводит дополнительную информацию о действиях.
|
abrt-cli report <DIR> <DIR> обозначает директорию с информацией об ошибке, о которой нужно сообщить. Например,:
~]$abrt-cli report/var/spool/abrt/ccpp-2011-09-13-10:18:14-2895How you would like to analyze the problem? 1) Collect .xsession-errors 2) Local GNU Debugger Select analyzer: _
abrt-cli откроет текстовый редактор с содержимым отчета. Вы можете просмотреть ту информацию, которая будет отправлена и добавить инструкции по воспроизведению ошибки или другие комментарии. Вам так же желательно проверить содержимое обратной трассировки, поскольку она может быть отправлена на публичный сервер и доступна для просмотра всем в зависимости от способа сообщения об ошибке.
abrt-cli использует редактор, определенный в переменной окружения ABRT_EDITOR. Если эта переменная не определена, программа проверяет переменные VISUAL и EDITOR. Если ни одна из переменных не определена, используется редактор vi. Вы можете указать предпочитаемый редактор в файле .bashrc. Например, если вы предпочитаете GNU Emacs, добавьте в файл следующую строку:
exportVISUAL=emacs
How would you like to report the problem? 1) Logger 2) Red Hat Customer Support Select reporter(s): _
abrt-cli report.
abrt-cli report| Опция | Описание |
|---|---|
Без дополнительных опций команда abrt-cli report выводит стандартную информацию.
| |
-v, --verbose
|
abrt-cli report выводит дополнительную информацию о действиях.
|
abrt-cli rm <DIR> <DIR> обозначает директорию с информацией об ошибке, которую нужно удалить. Например,:
~]$abrt-cli rm/var/spool/abrt/ccpp-2011-09-12-18:37:24-4413rm '/var/spool/abrt/ccpp-2011-09-12-18:37:24-4413'
abrt-cli rm.
abrt-cli rm| Опция | Описание |
|---|---|
Без дополнительных опций abrt-cli rm .
| |
-v, --verbose
|
abrt-cli rm выводит дополнительную информацию о действиях.
|
/etc/libreport/ — содержит главный конфигурационный файл report_event.conf. Больше информации об этом файле вы можете получить в Раздел 20.4.1, «События ABRT».
/etc/libreport/events/ — содержит файлы, определяющие настройки по умолчанию для предписанных событий.
/etc/libreport/events.d/ — содержит конфигурационные файлы, определяющие события.
/etc/libreport/plugins/ — содержит конфигурационные файлы для программ, участвующих в событиях.
/etc/abrt/ — содержит специфичные для ABRT конфигурационные файлы, определяющие поведение различных сервисов ABRT. Больше информации об этих файлах вы можете найти в Раздел 20.4.4, «Специфичные настройки ABRT».
/etc/abrt/plugins/ — содержит конфигурационные файлы, используемые для перезаписи настроек сервисов и программ ABRT по умолчанию. За дополнительной информацией обращайтесь к Раздел 20.4.4, «Специфичные настройки ABRT».
/etc/libreport/events.d/ directory. These configuration files are used by the main configuration file, /etc/libreport/report_event.conf.
/etc/libreport/report_event.conf состоит из включенных директив и правил. Правила обычно хранятся в других файлах в директории /etc/libreport/events.d/. В стандартной конфигурации файл /etc/libreport/report_event.conf содержит только одну включенную директиву:
include events.d/*.confspace tab рассматриваются как относящиеся к данному правилу. Каждое правило состоит из двух частей: условной части программной части. Условная часть содержит условия в одной из следующих форм:
VAR=VAL,
VAR!=VAL или
VAL~=REGEX
VAR is either the EVENT key word or a name of a problem data directory element (such as executable, package, hostname, etc.),
VAL is either a name of an event or a problem data element, and
REGEX является регулярным выражением.
EVENT=post-create date > /tmp/dt echo $HOSTNAME `uname -r`
/tmp/dt, записывая в него дату и время, и выводит имя хоста и версию ядра на стандартный выход.
~/.xsession-errors в отчет об ошибке, для обработки которой был использован сервис abrt-ccpp, а приложение, приведшее к сбою, загрузило какие-либо библиотеки X11 к моменту сбоя:
EVENT=analyze_xsession_errors analyzer=CCpp dso_list~=.*/libX11.* test -f ~/.xsession-errors || { echo "No ~/.xsession-errors"; exit 1; } test -r ~/.xsession-errors || { echo "Can't read ~/.xsession-errors"; exit 1; } executable=`cat executable` && base_executable=${executable##*/} && grep -F -e "$base_executable" ~/.xsession-errors | tail -999 >xsession_errors && echo "Element 'xsession_errors' saved"
post-createabrtd on newly created problem data directories. When the post-create event is run, abrtd checks whether the UUID identifier of the new problem data matches the UUID of any already existing problem directories. If such a problem directory exists, the new problem data is deleted.
analyze_<NAME_SUFFIX><NAME_SUFFIX> is the adjustable part of the event name. This event is used to process collected data. For example, the analyze_LocalGDB runs the GNU Debugger (GDB) utility on a core dump of an application and produces a backtrace of a program. You can view the list of analyze events and choose from it using abrt-gui.
collect_<NAME_SUFFIX><NAME_SUFFIX> is the adjustable part of the event name. This event is used to collect additional information on a problem. You can view the list of collect events and choose from it using abrt-gui.
report_<NAME_SUFFIX><NAME_SUFFIX> is the adjustable part of the event name. This event is used to report a problem. You can view the list of report events and choose from it using abrt-gui.
/etc/libreport/events/<event_name>.xml. Эти файлы используются приложениями abrt-gui и abrt-cli для улучшения ползовательского интерфейса. Не изменяйте эти файлы, если не хотите менять стандартную установку.
analyze_xsession_errors event is shown as Collect .xsession-errors in ABRT GUI. The following is a list of default analyzing, collecting and reporting events provided by the standard installation of ABRT:
backtrace of a program. It is defined in the /etc/libreport/events.d/ccpp_event.conf configuration file.
~/.xsession-errors в отчет об ошибке. Определено в конфигурационном файле /etc/libreport/events.d/ccpp_event.conf.
/etc/libreport/events.d/print_event.conf.
/etc/libreport/events.d/rhtsupport_event.conf.
/etc/libreport/events.d/mailx_event.conf.
/etc/libreport/events.d/koops_event.conf.
FTP или SCP. Определено в конфигурационном файле /etc/libreport/events.d/uploader_event.conf.
report_Logger event accepts an output file name as a parameter). Using the respective /etc/libreport/events/<event_name>.xml file, ABRT GUI determines which parameters can be specified for a selected event and allows a user to set the values for these parameters. These values are saved by ABRT GUI and reused on subsequent invocations of these events.
/etc/libreport/ directory hierarchy are world readable and are meant to be used as global settings. Thus, it is not advisable to store usernames, passwords or any other sensitive data in them. The per-user settings (set in the GUI application and readable by the owner of $HOME only) are stored in the Gnome keyring or can be stored in a text file in $HOME/.abrt/*.conf for use in abrt-cli.
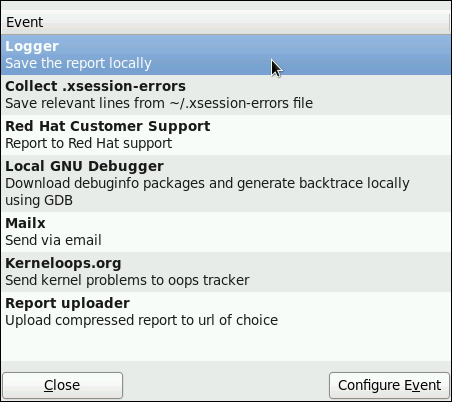
/var/log/abrt.log).
SSL.
Subject при отправке отчета по электронной почте с помощью Mailx (по умолчанию используется "[abrt] detected a crash").
From при отправке отчета по электронной почте.
FTP или SCP (по умолчанию используется ftp://localhost:/tmp/upload).
/etc/abrt/abrt.conf — позволяет вам изменить поведение сервиса abrtd.
/etc/abrt/abrt-action-save-package-data.conf — позволяет вам изменить поведениепрограммы abrt-action-save-package-data.
/etc/abrt/plugins/CCpp.conf, — allows you to modify the behavior of ABRT's core catching hook.
/etc/abrt/abrt.conf поддерживаются следующие конфигурационные директивы:
abrtd автоматически распаковывал tar-архивы (.tar.gz) с данными по сбоям, лежащие в определенной директории. В примере выше, это директория /var/spool/abrt-upload/. Какую бы директорию вы не указали в этой директиве, вы должны убедиться, что она существует и что abrtd имеет права записи в нее. Демон ABRT не создаст эту директорию автоматически.
abrt_selinux(8) manual page for more information on running ABRT in SELinux.
setsebool -P abrt_anon_write 1 <size_in_megabytes>1000 Мб. Когда выделенное место будет использовано, ABRT продолжит отслеживание проблем и при необходимости сохранения новой информации об ошибках будет удалять наиболее старые и наиболее объемные отчеты.
/var/spool/abrt. Какую бы директорию вы не задали в этой директиве, вы должны убедиться, что она существует и что abrtd имеет права записи в нее.
abrt_selinux(8) manual page for more information on running ABRT in SELinux.
setsebool -P abrt_anon_write 1 /etc/abrt/abrt-action-save-package-data.conf поддерживаются следующие конфигурационные директивы:
<yes/no>OpenGPGCheck в значение yes (значение по умолчанию)означает, что ABRT будет анализировать и обрабатывать сбои только в приложениях с пакетами, подписанными ключами GPG, местоположения которых перечисленны в файле /etc/abrt/gpg_keys. Если директива OpenGPGCheck установлена в значение no, то ABRT будет отслеживать сбои во всех программах.
<MORE_PACKAGES> ]BlackList не будет отлавливаться ABRT. Если вы хотите чтобы ABRT игнорировал и другие пакеты и файлы, перечислите их здесь через запятую.
<yes/no>/usr/share/doc/*, */example*/etc/abrt/plugins/CCpp.conf поддерживаются следующие конфигурационные директивы следующие конфигурационные директивы:
<yes/no>ulimit -c setting allows it. The directive is set to yes by default.
<yes/no>EVENT=report_Bugzilla condition with the EVENT=port-create condition in the /etc/libreport/events.d/python_event.conf file:
EVENT=post-create analyzer=Python test -f component || abrt-action-save-package-data reporter-bugzilla -c /etc/abrt/plugins/Bugzilla.conf
post-create запускается с привилегиями суперпользователяpost-create запускается приложением abrtd, которое обычно функционирует с правами суперпользователя.
http_proxy and the ftp_proxy environment variables. When you use environment variables as a part of a reporting event, they inherit their values from the process which performs reporting, usually abrt-gui or abrt-cli. Therefore, you can specify HTTP or FTP proxy servers by using these variables in your working environment.
post-create event, they will run as children of the abrtd process. You should either adjust the environment of abrtd or modify the rules to set these variables. For example:
EVENT=post-create analyzer=Python test -f component || abrt-action-save-package-data export http_proxy=http://proxy.server:8888/ reporter-bugzilla -c /etc/abrt/plugins/Bugzilla.conf
yum install libreport-plugin-reportuploader). See the following sections on how to configure systems to use ABRT's centralized crash collection.
/var/spool/abrt-upload/ is used (the rest of the document assumes you are using this directory). Make sure this directory is writable by the abrt user.
abrt. This user is used by the abrtd daemon, for example, as the owner:group of /var/spool/abrt/* directories.
/etc/abrt/abrt.conf установить директиву WatchCrashdumpArchiveDir как указано ниже:
WatchCrashdumpArchiveDir = /var/spool/abrt-upload/
FTP or SCP. For more information on how to configure FTP, refer to Раздел 16.2, «FTP». For more information on how to configure SCP, refer to Раздел 10.3.2, «Using the scp Utility».
FTP, upload a file using an interactive FTP client:
~]$ftpftp>open SERVERNAMEName:USERNAMEPassword:PASSWORDftp>cd /var/spool/abrt-upload250 Operation successful ftp>put TESTFILEftp>quit
TESTFILE в нужной директории на сервере.
MaxCrashReportsSize (в файле /etc/abrt/abrt.conf) была установлена на большее значение, если ожидаемый размер данных об ошибках превышает значение по умолчанию в 1000 Мб.
/etc/libreport/events.d/ccpp_events.conf configuration file:
EVENT=analyze_LocalGDB analyzer=CCpp abrt-action-analyze-core.py --core=coredump -o build_ids && abrt-action-install-debuginfo-to-abrt-cache --size_mb=4096 && abrt-action-generate-backtrace && abrt-action-analyze-backtrace
remote!=1.
package and the component elements) in the problem data. Refer to Раздел 20.5.3, «Сохранение информации о пакете» to find out whether you need to collect package information in your centralized crash collection configuration and how to configure it properly.
/etc/libreport/events.d/ccpp_events.conf file. Refer to Раздел 20.5.1, «Шаги по настройке, необходимые на выделенной системе» for an example of such a example.
/etc/libreport/events.d/abrt_event.conf file. Refer to Раздел 20.5.3, «Сохранение информации о пакете» to find out whether you need to collect package information in your centralized crash collection configuration and how to configure it properly.
/etc/libreport/events.d/abrt_event.conf:
report_SFX, если вы хотите, чтобы данные об ошибках хранились на клиентских машинах, а вы загружали их позже с помощью ABRT GUI/CLI. Ниже приведен пример подобного события:
post-create event runs the abrt-action-save-package-data tool (among other steps) in order to provide this information in the standard ABRT installation.
/etc/libreport/events.d/abrt_event.conf:
/etc/abrt/abrt-action-save-package-data.conf file:
ProcessUnpackaged = yes
remote!=1 condition in the /etc/libreport/events.d/abrt_event.conf file:
/etc/abrt/abrt-action-save-package-data.conf:
ProcessUnpackaged = yes
kill -s SEGV PID , чтобы прекратить процесс на клиентской системе. Например, запустите процесс сна (sleep) и остановите его при помощи команды kill следующим образом:
~]$sleep 100 &[1] 2823 ~]$kill -s SEGV 2823
kill command. Check that the crash was detected by ABRT on the client system (this can be checked by examining the appropriate syslog file, by running the abrt-cli list --full command, or by examining the crash dump created in the /var/spool/abrt directory), copied to the server system, unpacked on the server system and can be seen and acted upon using abrt-cli or abrt-gui on the server system.
oprofile package must be installed to use this tool.
--separate=library option is used.
opreport does not associate samples for inline functions properly — opreport uses a simple address range mechanism to determine which function an address is in. Inline function samples are not attributed to the inline function but rather to the function the inline function was inserted into.
opcontrol --reset to clear out the samples from previous runs.
timer mode. Run the command opcontrol --deinit, and then execute modprobe oprofile timer=1 to enable the timer mode.
oprofile package.
| Command | Description |
|---|---|
ophelp
|
Displays available events for the system's processor along with a brief description of each.
|
opimport
|
Converts sample database files from a foreign binary format to the native format for the system. Only use this option when analyzing a sample database from a different architecture.
|
opannotate
|
Creates annotated source for an executable if the application was compiled with debugging symbols. Refer to Раздел 21.5.4, «Using opannotate » for details.
|
opcontrol
|
Configures what data is collected. Refer to Раздел 21.2, «Configuring OProfile» for details.
|
opreport
|
Retrieves profile data. Refer to Раздел 21.5.1, «Using
opreport » for details.
|
oprofiled
|
Runs as a daemon to periodically write sample data to disk.
|
opcontrol utility to configure OProfile. As the opcontrol commands are executed, the setup options are saved to the /root/.oprofile/daemonrc file.
~]# opcontrol --setup --vmlinux=/usr/lib/debug/lib/modules/`uname -r`/vmlinux~]# opcontrol --setup --no-vmlinuxoprofile kernel module, if it is not already loaded, and creates the /dev/oprofile/ directory, if it does not already exist. Refer to Раздел 21.6, «Understanding /dev/oprofile/ » for details about this directory.
| Processor |
cpu_type
| Number of Counters |
|---|---|---|
| AMD64 | x86-64/hammer | 4 |
| AMD Athlon | i386/athlon | 4 |
| AMD Family 10h | x86-64/family10 | 4 |
| AMD Family 11h | x86-64/family11 | 4 |
| AMD Family 12h | x86-64/family12 | 4 |
| AMD Family 14h | x86-64/family14 | 4 |
| AMD Family 15h | x86-64/family15 | 6 |
| IBM eServer System i and IBM eServer System p | timer | 1 |
| IBM POWER4 | ppc64/power4 | 8 |
| IBM POWER5 | ppc64/power5 | 6 |
| IBM PowerPC 970 | ppc64/970 | 8 |
| IBM S/390 and IBM System z | timer | 1 |
| Intel Core i7 | i386/core_i7 | 4 |
| Intel Nehalem microarchitecture | i386/nehalem | 4 |
| Intel Pentium 4 (non-hyper-threaded) | i386/p4 | 8 |
| Intel Pentium 4 (hyper-threaded) | i386/p4-ht | 4 |
| Intel Westmere microarchitecture | i386/westmere | 4 |
| TIMER_INT | timer | 1 |
timer is used as the processor type if the processor does not have supported performance monitoring hardware.
timer is used, events cannot be set for any processor because the hardware does not have support for hardware performance counters. Instead, the timer interrupt is used for profiling.
timer is not used as the processor type, the events monitored can be changed, and counter 0 for the processor is set to a time-based event by default. If more than one counter exists on the processor, the counters other than counter 0 are not set to an event by default. The default events monitored are shown in Таблица 21.3, «Default Events».
| Processor | Default Event for Counter | Description |
|---|---|---|
| AMD Athlon and AMD64 | CPU_CLK_UNHALTED | The processor's clock is not halted |
| AMD Family 10h, AMD Family 11h, AMD Family 12h | CPU_CLK_UNHALTED | The processor's clock is not halted |
| AMD Family 14h, AMD Family 15h | CPU_CLK_UNHALTED | The processor's clock is not halted |
| IBM POWER4 | CYCLES | Processor Cycles |
| IBM POWER5 | CYCLES | Processor Cycles |
| IBM PowerPC 970 | CYCLES | Processor Cycles |
| Intel Core i7 | CPU_CLK_UNHALTED | The processor's clock is not halted |
| Intel Nehalem microarchitecture | CPU_CLK_UNHALTED | The processor's clock is not halted |
| Intel Pentium 4 (hyper-threaded and non-hyper-threaded) | GLOBAL_POWER_EVENTS | The time during which the processor is not stopped |
| Intel Westmere microarchitecture | CPU_CLK_UNHALTED | The processor's clock is not halted |
| TIMER_INT | (none) | Sample for each timer interrupt |
~]# ls -d /dev/oprofile/[0-9]*~]# ophelpopcontrol:
~]# opcontrol --event=event-name:sample-rateevent-name with the exact name of the event from ophelp, and replace sample-rate with the number of events between samples.
cpu_type is not timer, each event can have a sampling rate set for it. The sampling rate is the number of events between each sample snapshot.
~]# opcontrol --event=event-name:sample-ratesample-rate with the number of events to wait before sampling again. The smaller the count, the more frequent the samples. For events that do not happen frequently, a lower count may be needed to capture the event instances.
ophelp command. The values for each unit mask are listed in hexadecimal format. To specify more than one unit mask, the hexadecimal values must be combined using a bitwise or operation.
~]# opcontrol --event=event-name:sample-rate:unit-mask~]# opcontrol --event=event-name:sample-rate:unit-mask:0~]# opcontrol --event=event-name:sample-rate:unit-mask:1~]# opcontrol --event=event-name:sample-rate:unit-mask:kernel:0~]# opcontrol --event=event-name:sample-rate:unit-mask:kernel:1~]# opcontrol --separate=choicechoice can be one of the following:
none — do not separate the profiles (default)
library — generate per-application profiles for libraries
kernel — generate per-application profiles for the kernel and kernel modules
all — generate per-application profiles for libraries and per-application profiles for the kernel and kernel modules
--separate=library is used, the sample file name includes the name of the executable as well as the name of the library.
~]# opcontrol --startUsing log file /var/lib/oprofile/oprofiled.log Daemon started. Profiler running.
/root/.oprofile/daemonrc are used.
oprofiled, is started; it periodically writes the sample data to the /var/lib/oprofile/samples/ directory. The log file for the daemon is located at /var/lib/oprofile/oprofiled.log.
nmi_watchdog registers with the perf subsystem. Due to this, the perf subsystem grabs control of the performance counter registers at boot time, blocking OProfile from working.
nmi_watchdog=0 kernel parameter set, or run the following command to disable nmi_watchdog at run time:
~]# echo 0 > /proc/sys/kernel/nmi_watchdognmi_watchdog, use the following command:
~]# echo 1 > /proc/sys/kernel/nmi_watchdog~]# opcontrol --shutdownname with a unique descriptive name for the current session.
~]# opcontrol --save=name/var/lib/oprofile/samples/name/ is created and the current sample files are copied to it.
oprofiled, collects the samples and writes them to the /var/lib/oprofile/samples/ directory. Before reading the data, make sure all data has been written to this directory by executing the following command as root:
~]# opcontrol --dump/bin/bash becomes:
\{root\}/bin/bash/\{dep\}/\{root\}/bin/bash/CPU_CLK_UNHALTED.100000opreport
opannotate
oparchive can be used to address this problem.
opreport opreport tool provides an overview of all the executables being profiled.
Profiling through timer interrupt TIMER:0| samples| %| ------------------ 25926 97.5212 no-vmlinux 359 1.3504 pi 65 0.2445 Xorg 62 0.2332 libvte.so.4.4.0 56 0.2106 libc-2.3.4.so 34 0.1279 libglib-2.0.so.0.400.7 19 0.0715 libXft.so.2.1.2 17 0.0639 bash 8 0.0301 ld-2.3.4.so 8 0.0301 libgdk-x11-2.0.so.0.400.13 6 0.0226 libgobject-2.0.so.0.400.7 5 0.0188 oprofiled 4 0.0150 libpthread-2.3.4.so 4 0.0150 libgtk-x11-2.0.so.0.400.13 3 0.0113 libXrender.so.1.2.2 3 0.0113 du 1 0.0038 libcrypto.so.0.9.7a 1 0.0038 libpam.so.0.77 1 0.0038 libtermcap.so.2.0.8 1 0.0038 libX11.so.6.2 1 0.0038 libgthread-2.0.so.0.400.7 1 0.0038 libwnck-1.so.4.9.0
opreport man page for a list of available command line options, such as the -r option used to sort the output from the executable with the smallest number of samples to the one with the largest number of samples.
opreport:
~]# opreport mode executableexecutable must be the full path to the executable to be analyzed. mode must be one of the following:
-l opreport -l /lib/tls/libc-version.so:
samples % symbol name 12 21.4286 __gconv_transform_utf8_internal 5 8.9286 _int_malloc 4 7.1429 malloc 3 5.3571 __i686.get_pc_thunk.bx 3 5.3571 _dl_mcount_wrapper_check 3 5.3571 mbrtowc 3 5.3571 memcpy 2 3.5714 _int_realloc 2 3.5714 _nl_intern_locale_data 2 3.5714 free 2 3.5714 strcmp 1 1.7857 __ctype_get_mb_cur_max 1 1.7857 __unregister_atfork 1 1.7857 __write_nocancel 1 1.7857 _dl_addr 1 1.7857 _int_free 1 1.7857 _itoa_word 1 1.7857 calc_eclosure_iter 1 1.7857 fopen@@GLIBC_2.1 1 1.7857 getpid 1 1.7857 memmove 1 1.7857 msort_with_tmp 1 1.7857 strcpy 1 1.7857 strlen 1 1.7857 vfprintf 1 1.7857 write
-r in conjunction with the -l option.
-i symbol-name opreport -l -i __gconv_transform_utf8_internal /lib/tls/libc-version.so:
samples % symbol name 12 100.000 __gconv_transform_utf8_internal
-d -l. For example, the following output is from the command opreport -l -d __gconv_transform_utf8_internal /lib/tls/libc-version.so:
vma samples % symbol name 00a98640 12 100.000 __gconv_transform_utf8_internal 00a98640 1 8.3333 00a9868c 2 16.6667 00a9869a 1 8.3333 00a986c1 1 8.3333 00a98720 1 8.3333 00a98749 1 8.3333 00a98753 1 8.3333 00a98789 1 8.3333 00a98864 1 8.3333 00a98869 1 8.3333 00a98b08 1 8.3333
-l option except that for each symbol, each virtual memory address used is shown. For each virtual memory address, the number of samples and percentage of samples relative to the number of samples for the symbol is displayed.
-x symbol-name session:name /var/lib/oprofile/samples/ directory.
initrd file on boot up, the directory with the various kernel modules, or a locally created kernel module. As a result, when OProfile records sample for a module, it just lists the samples for the modules for an executable in the root directory, but this is unlikely to be the place with the actual code for the module. You will need to take some steps to make sure that analysis tools get the executable.
uname -a command, obtain the appropriate debuginfo package and install it on the machine.
~]# opcontrol --reset~]#opcontrol --setup --vmlinux=/usr/lib/debug/lib/modules/`uname -r`/vmlinux \--event=CPU_CLK_UNHALTED:500000
~]# opreport /ext4 -l --image-path /lib/modules/`uname -r`/kernel
CPU: Intel Westmere microarchitecture, speed 2.667e+06 MHz (estimated)
Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (No unit mask) count 500000
warning: could not check that the binary file /lib/modules/2.6.32-191.el6.x86_64/kernel/fs/ext4/ext4.ko has not been modified since the profile was taken. Results may be inaccurate.
samples % symbol name
1622 9.8381 ext4_iget
1591 9.6500 ext4_find_entry
1231 7.4665 __ext4_get_inode_loc
783 4.7492 ext4_ext_get_blocks
752 4.5612 ext4_check_dir_entry
644 3.9061 ext4_mark_iloc_dirty
583 3.5361 ext4_get_blocks
583 3.5361 ext4_xattr_get
479 2.9053 ext4_htree_store_dirent
469 2.8447 ext4_get_group_desc
414 2.5111 ext4_dx_find_entryopannotate opannotate tool tries to match the samples for particular instructions to the corresponding lines in the source code. The resulting files generated should have the samples for the lines at the left. It also puts in a comment at the beginning of each function listing the total samples for the function.
opannotate is as follows:
~]# opannotate --search-dirs src-dir --source executableopannotate man page for a list of additional command line options.
/dev/oprofile/ /dev/oprofile/ directory contains the file system for OProfile. Use the cat command to display the values of the virtual files in this file system. For example, the following command displays the type of processor OProfile detected:
~]# cat /dev/oprofile/cpu_type/dev/oprofile/ for each counter. For example, if there are 2 counters, the directories /dev/oprofile/0/ and dev/oprofile/1/ exist.
count — The interval between samples.
enabled — If 0, the counter is off and no samples are collected for it; if 1, the counter is on and samples are being collected for it.
event — The event to monitor.
extra — Used on machines with Nehalem processors to further specify the event to monitor.
kernel — If 0, samples are not collected for this counter event when the processor is in kernel-space; if 1, samples are collected even if the processor is in kernel-space.
unit_mask — Defines which unit masks are enabled for the counter.
user — If 0, samples are not collected for the counter event when the processor is in user-space; if 1, samples are collected even if the processor is in user-space.
cat command. For example:
~]# cat /dev/oprofile/0/countopreport can be used to determine how much processor time an application or service uses. If the system is used for multiple services but is under performing, the services consuming the most processor time can be moved to dedicated systems.
CPU_CLK_UNHALTED event can be monitored to determine the processor load over a given period of time. This data can then be used to determine if additional processors or a faster processor might improve system performance.
-agentlib:jvmti_oprofileoprof_start command as root at a shell prompt. To use the graphical interface, you will need to have the oprofile-gui package installed.
/root/.oprofile/daemonrc, and the application exits. Exiting the application does not stop OProfile from sampling.
oprof_start interface
vmlinux file for the kernel to monitor in the Kernel image file text field. To configure OProfile not to monitor the kernel, select No kernel image.
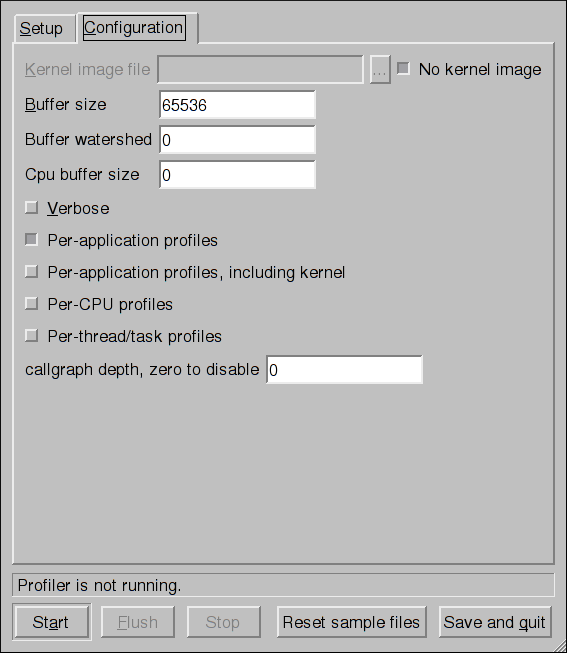
oprofiled daemon log includes more information.
opcontrol --separate=library command. If Per-application profiles, including kernel is selected, OProfile generates per-application profiles for the kernel and kernel modules as discussed in Раздел 21.2.3, «Separating Kernel and User-space Profiles». This is equivalent to the opcontrol --separate=kernel command.
opcontrol --dump command.
netstat, ps, top, and iostat; however, SystemTap is designed to provide more filtering and analysis options for collected information.
/usr/share/doc/oprofile-version/oprofile.html — OProfile Manual
oprofile man page — Discusses opcontrol, opreport, opannotate, and ophelp
Содержание
rpm command instead of yum.
/usr/share/doc/kernel-doc-kernel_version/ directory.
VFAT file system. You can create bootable USB media on media formatted as ext2, ext3, ext4, or VFAT.
4 GB is required for a distribution DVD image, around 700 MB for a distribution CD image, or around 10 MB for a minimal boot media image.
boot.iso file from a Fedora installation DVD, or installation CD-ROM#1, and you need a USB storage device formatted with the VFAT file system and around 16 MB of free space. The following procedure will not affect existing files on the USB storage device unless they have the same path names as the files that you copy onto it. To create USB boot media, perform the following commands as the root user:
syslinux /dev/sdX1sdX is the device name.
boot.iso and the USB storage device:
mkdir /mnt/isoboot /mnt/diskbootboot.iso:
mount -o loop boot.iso /mnt/isobootmount /dev/sdX1 /mnt/diskbootboot.iso to the USB storage device:
cp /mnt/isoboot/isolinux/* /mnt/diskbootisolinux.cfg file from boot.iso as the syslinux.cfg file for the USB device:
grep -v local /mnt/isoboot/isolinux/isolinux.cfg > /mnt/diskboot/syslinux.cfgboot.iso and the USB storage device:
umount /mnt/isoboot /mnt/diskbootmkbootdisk command as root. Refer to man mkbootdisk man page after installing the package for usage information.
yum list installed "kernel-*" at a shell prompt. The output will comprise some or all of the following packages, depending on the system's architecture, and the version numbers may differ:
~]# yum list installed "kernel-*"
Loaded plugins: langpacks, presto, refresh-packagekit
Installed Packages
kernel.x86_64 3.1.0-0.rc6.git0.3.fc16 @updates-testing
kernel.x86_64 3.1.0-0.rc9.git0.0.fc16 @updates-testing
kernel-doc.x86_64 3.1.0-0.rc6.git0.3.fc16 @updates-testing
kernel-doc.x86_64 3.1.0-0.rc9.git0.0.fc16 @updates-testing
kernel-headers.x86_64 3.1.0-0.rc6.git0.3.fc16 @updates-testing
kernel-headers.x86_64 3.1.0-0.rc9.git0.0.fc16 @updates-testing-i argument with the rpm command to keep the old kernel. Do not use the -U option, since it overwrites the currently installed kernel, which creates boot loader problems. For example:
rpm -ivh kernel-kernel_version.arch.rpm initramfs by running the dracut command. However, you usually don't need to create an initramfs manually: this step is automatically performed if the kernel and its associated packages are installed or upgraded from RPM packages distributed by The Fedora Project.
initramfs corresponding to your current kernel version exists and is specified correctly in the /boot/grub2/grub.cfg configuration file by following this procedure:
root, list the contents in the /boot directory and find the kernel (vmlinuz-kernel_version) and initramfs-kernel_version with the latest (most recent) version number:
~]# ls /boot
config-3.1.0-0.rc6.git0.3.fc16.x86_64
config-3.1.0-0.rc9.git0.0.fc16.x86_64
elf-memtest86+-4.20
grub
grub2
initramfs-3.1.0-0.rc6.git0.3.fc16.x86_64.img
initramfs-3.1.0-0.rc9.git0.0.fc16.x86_64.img
initrd-plymouth.img
memtest86+-4.20
System.map-3.1.0-0.rc6.git0.3.fc16.x86_64
System.map-3.1.0-0.rc9.git0.0.fc16.x86_64
vmlinuz-3.1.0-0.rc6.git0.3.fc16.x86_64
vmlinuz-3.1.0-0.rc9.git0.0.fc16.x86_64/boot directory),
vmlinuz-vmlinuz-3.1.0-0.rc9.git0.0.fc16.x86_64, and
initramfs file matching our kernel version, initramfs-3.1.0-0.rc9.git0.0.fc16.x86_64.img, also exists.
/boot directory you may find several initrd-<kernel_version>kdump.img files. These are special files created by the kdump mechanism for kernel debugging purposes, are not used to boot the system, and can safely be ignored. For more information on kdump, refer to Глава 24, The kdump Crash Recovery Service.
initramfs-kernel_version file does not match the version of the latest kernel in /boot, or, in certain other situations, you may need to generate an initramfs file with the Dracut utility. Simply invoking dracut as root without options causes it to generate an initramfs file in the /boot directory for the latest kernel present in that directory:
~]# dracut--force option if you want dracut to overwrite an existing initramfs (for example, if your initramfs has become corrupt). Otherwise dracut will refuse to overwrite the existing initramfs file:
~]# dracut
F: Will not override existing initramfs (/boot/initramfs-3.1.0-0.rc9.git0.0.fc16.x86_64.img) without --forcedracut initramfs_name kernel_version, for example:
~]# dracut "initramfs-$(uname -r).img" $(uname -r).ko) inside the parentheses of the add_dracutmodules="module [more_modules]" directive of the /etc/dracut.conf configuration file. You can list the file contents of an initramfs image file created by dracut by using the lsinitrd initramfs_file command:
~]# lsinitrd /boot/initramfs-3.1.0-0.rc9.git0.0.fc16.x86_64.img
/boot/initramfs-3.1.0-0.rc9.git0.0.fc16.x86_64.img: 16M
========================================================================
dracut-013-15.fc16
========================================================================
drwxr-xr-x 8 root root 0 Oct 11 20:36 .
lrwxrwxrwx 1 root root 17 Oct 11 20:36 lib -> run/initramfs/lib
drwxr-xr-x 2 root root 0 Oct 11 20:36 sys
drwxr-xr-x 2 root root 0 Oct 11 20:36 proc
lrwxrwxrwx 1 root root 17 Oct 11 20:36 etc -> run/initramfs/etc
[output truncated]man dracut and man dracut.conf for more information on options and usage.
/boot/grub2/grub.cfg configuration file to ensure that an initrd /path/initramfs-kernel_version.img exists for the kernel version you are booting. For example:
~]# grep initrd /boot/grub2/grub.cfg
initrd /initramfs-3.1.0-0.rc6.git0.3.fc16.x86_64.img
initrd /initramfs-3.1.0-0.rc9.git0.0.fc16.x86_64.img/boot/grub2/grub.cfg file.
addRamDisk command. This step is performed automatically if the kernel and its associated packages are installed or upgraded from the RPM packages distributed by The Fedora Project; thus, it does not need to be executed manually. To verify that it was created, run the following command as root to make sure the /boot/vmlinitrd-kernel_version file already exists:
ls -l /bootkernel_version should match the version of the kernel just installed.
rpm, the kernel package creates an entry in the boot loader configuration file for that new kernel. However, rpm does not configure the new kernel to boot as the default kernel. You must do this manually when installing a new kernel with rpm.
rpm to ensure that the configuration is correct. Otherwise, the system may not be able to boot into Fedora properly. If this happens, boot the system with the boot media created earlier and re-configure the boot loader.
| Architecture | Boot Loader | Refer to |
|---|---|---|
| x86 | GRUB 2 | Раздел 22.6.1, «Configuring the GRUB 2 Boot Loader» |
| AMD AMD64 or Intel 64 | GRUB 2 | Раздел 22.6.1, «Configuring the GRUB 2 Boot Loader» |
| IBM eServer System i | OS/400 | Раздел 22.6.2, «Configuring the OS/400 Boot Loader» |
| IBM eServer System p | YABOOT | Раздел 22.6.3, «Configuring the YABOOT Boot Loader» |
| IBM System z | z/IPL | — |
/boot/grub2/grub.cfg file. This file is generated by the grub2-mkconfig utility based on Linux kernels located in the /boot directory, template files located in /etc/grub.d/, and custom settings in the /etc/default/grub file and is automatically updated each time you install a new kernel from an RPM package. To update this configuration file manually, type the following at a shell prompt as root:
grub2-mkconfig-o/boot/grub2/grub.cfg
/boot/grub2/grub.cfg configuration file contains one or more menuentry blocks, each representing a single GRUB 2 boot menu entry. These blocks always start with the menuentry keyword followed by a title, list of options, and opening curly bracket, and end with a closing curly bracket. Anything between the opening and closing bracket should be indented. For example, the following is a sample menuentry block for Fedora 17 with Linux kernel 3.4.0-1.fc17.x86_64:
menuentry 'Fedora (3.4.0-1.fc17.x86_64)' --class fedora --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-77ba9149-751a-48e0-974f-ad94911734b9' {
load_video
set gfxpayload=keep
insmod gzio
insmod part_msdos
insmod ext2
set root='hd0,msdos1'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint='hd0,msdos1' 4ea24c68-ab10-47d4-8a6b-b8d3a002acba
else
search --no-floppy --fs-uuid --set=root 4ea24c68-ab10-47d4-8a6b-b8d3a002acba
fi
echo 'Loading Fedora (3.4.0-1.fc17.x86_64)'
linux /vmlinuz-3.4.0-1.fc17.x86_64 root=/dev/mapper/vg_fedora-lv_root ro rd.md=0 rd.dm=0 SYSFONT=True rd.lvm.lv=vg_fedora/lv_swap KEYTABLE=us rd.lvm.lv=vg_fedora/lv_root rd.luks=0 LANG=en_US.UTF-8 rhgb quiet
echo 'Loading initial ramdisk ...'
initrd /initramfs-3.4.0-1.fc17.x86_64.img
}menuentry block that represents an installed Linux kernel contains linux and initrd directives followed by the path to the kernel and the initramfs image respectively. If a separate /boot partition was created, the paths to the kernel and the initramfs image are relative to /boot. In the example above, the initrd /initramfs-3.4.0-1.fc17.x86_64.img line means that the initramfs image is actually located at /boot/initramfs-3.4.0-1.fc17.x86_64.img when the root file system is mounted, and likewise for the kernel path.
linux /vmlinuz-kernel_version line must match the version number of the initramfs image given on the initrd /initramfs-kernel_version.img line of each menuentry block. For more information on how to verify the initial RAM disk image, refer to Процедура 22.1, «Verifying the Initial RAM Disk Image».
menuentry blocks, the initrd directive must point to the location (relative to the /boot directory if it is on a separate partition) of the initramfs file corresponding to the same kernel version. This directive is called initrd because the previous tool which created initial RAM disk images, mkinitrd, created what were known as initrd files. The grub.cfg directive remains initrd to maintain compatibility with other tools. The file-naming convention of systems using the dracut utility to create the initial RAM disk image is initramfs-kernel_version.img.
rpm, verify that /boot/grub2/grub.cfg is correct and reboot the computer into the new kernel. Ensure your hardware is detected by watching the boot process output. If GRUB 2 presents an error and is unable to boot into the new kernel, it is often easiest to try to boot into an alternative or older kernel so that you can fix the problem. Alternatively, use the boot media you created earlier to boot the system.
GRUB_TIMEOUT option in the /etc/default/grub file to 0, GRUB 2 will not display its list of bootable kernels when the system starts up. In order to display this list when booting, press and hold any alphanumeric key while and immediately after BIOS information is displayed, and GRUB 2 will present you with the GRUB menu.
/boot/vmlinitrd-kernel-version file is installed when you upgrade the kernel. However, you must use the dd command to configure the system to boot the new kernel.
root, issue the command cat /proc/iSeries/mf/side to determine the default side (either A, B, or C).
root, issue the following command, where kernel-version is the version of the new kernel and side is the side from the previous command:
dd if=/boot/vmlinitrd-kernel-version of=/proc/iSeries/mf/side/vmlinux bs=8k/etc/aboot.conf as its configuration file. Confirm that the file contains an image section with the same version as the kernel package just installed, and likewise for the initramfs image:
boot=/dev/sda1 init-message=Welcome to Fedora! Hit <TAB> for boot options partition=2 timeout=30 install=/usr/lib/yaboot/yaboot delay=10 nonvram image=/vmlinuz-2.6.32-17.EL label=old read-only initrd=/initramfs-2.6.32-17.EL.img append="root=LABEL=/" image=/vmlinuz-2.6.32-19.EL label=linux read-only initrd=/initramfs-2.6.32-19.EL.img append="root=LABEL=/"
default and set it to the label of the image stanza that contains the new kernel.
btrfs or NFS.
root:
yum install module-init-tools
lsmod command, for example:
~]$ lsmod
Module Size Used by
xfs 803635 1
exportfs 3424 1 xfs
vfat 8216 1
fat 43410 1 vfat
tun 13014 2
fuse 54749 2
ip6table_filter 2743 0
ip6_tables 16558 1 ip6table_filter
ebtable_nat 1895 0
ebtables 15186 1 ebtable_nat
ipt_MASQUERADE 2208 6
iptable_nat 5420 1
nf_nat 19059 2 ipt_MASQUERADE,iptable_nat
rfcomm 65122 4
ipv6 267017 33
sco 16204 2
bridge 45753 0
stp 1887 1 bridge
llc 4557 2 bridge,stp
bnep 15121 2
l2cap 45185 16 rfcomm,bnep
cpufreq_ondemand 8420 2
acpi_cpufreq 7493 1
freq_table 3851 2 cpufreq_ondemand,acpi_cpufreq
usb_storage 44536 1
sha256_generic 10023 2
aes_x86_64 7654 5
aes_generic 27012 1 aes_x86_64
cbc 2793 1
dm_crypt 10930 1
kvm_intel 40311 0
kvm 253162 1 kvm_intel
[output truncated]lsmod output specifies:
lsmod output is less verbose and considerably easier to read than the content of the /proc/modules pseudo-file.
modinfo module_name command.
.ko extension to the end of the name. Kernel module names do not have extensions: their corresponding files do.
e1000e module, which is the Intel PRO/1000 network driver, run:
~]#modinfo e1000efilename: /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/net/e1000e/e1000e.ko version: 1.2.7-k2 license: GPL description: Intel(R) PRO/1000 Network Driver author: Intel Corporation, <linux.nics@intel.com> srcversion: 93CB73D3995B501872B2982 alias: pci:v00008086d00001503sv*sd*bc*sc*i* alias: pci:v00008086d00001502sv*sd*bc*sc*i* [somealiaslines omitted] alias: pci:v00008086d0000105Esv*sd*bc*sc*i* depends: vermagic: 2.6.32-71.el6.x86_64 SMP mod_unload modversions parm: copybreak:Maximum size of packet that is copied to a new buffer on receive (uint) parm: TxIntDelay:Transmit Interrupt Delay (array of int) parm: TxAbsIntDelay:Transmit Absolute Interrupt Delay (array of int) parm: RxIntDelay:Receive Interrupt Delay (array of int) parm: RxAbsIntDelay:Receive Absolute Interrupt Delay (array of int) parm: InterruptThrottleRate:Interrupt Throttling Rate (array of int) parm: IntMode:Interrupt Mode (array of int) parm: SmartPowerDownEnable:Enable PHY smart power down (array of int) parm: KumeranLockLoss:Enable Kumeran lock loss workaround (array of int) parm: WriteProtectNVM:Write-protect NVM [WARNING: disabling this can lead to corrupted NVM] (array of int) parm: CrcStripping:Enable CRC Stripping, disable if your BMC needs the CRC (array of int) parm: EEE:Enable/disable on parts that support the feature (array of int)
modinfo output:
.ko kernel object file. You can use modinfo -n as a shortcut command for printing only the filename field.
modinfo -d as a shortcut command for printing only the description field.
alias field appears as many times as there are aliases for a module, or is omitted entirely if there are none.
depends field may be omitted from the output.
parm field presents one module parameter in the form parameter_name:descriptionparameter_name is the exact syntax you should use when using it as a module parameter on the command line, or in an option line in a .conf file in the /etc/modprobe.d/ directory; and,
description is a brief explanation of what the parameter does, along with an expectation for the type of value the parameter accepts (such as int, unit or array of int) in parentheses.
-p option. However, because useful value type information is omitted from modinfo -p output, it is more useful to run:
~]# modinfo e1000e | grep "^parm" | sort
parm: copybreak:Maximum size of packet that is copied to a new buffer on receive (uint)
parm: CrcStripping:Enable CRC Stripping, disable if your BMC needs the CRC (array of int)
parm: EEE:Enable/disable on parts that support the feature (array of int)
parm: InterruptThrottleRate:Interrupt Throttling Rate (array of int)
parm: IntMode:Interrupt Mode (array of int)
parm: KumeranLockLoss:Enable Kumeran lock loss workaround (array of int)
parm: RxAbsIntDelay:Receive Absolute Interrupt Delay (array of int)
parm: RxIntDelay:Receive Interrupt Delay (array of int)
parm: SmartPowerDownEnable:Enable PHY smart power down (array of int)
parm: TxAbsIntDelay:Transmit Absolute Interrupt Delay (array of int)
parm: TxIntDelay:Transmit Interrupt Delay (array of int)
parm: WriteProtectNVM:Write-protect NVM [WARNING: disabling this can lead to corrupted NVM] (array of int)modprobe module_name as root. For example, to load the wacom module, run:
~]# modprobe wacom
modprobe attempts to load the module from /lib/modules/kernel_version/kernel/drivers/. In this directory, each type of module has its own subdirectory, such as net/ and scsi/, for network and SCSI interface drivers respectively.
modprobe command always takes dependencies into account when performing operations. When you ask modprobe to load a specific kernel module, it first examines the dependencies of that module, if there are any, and loads them if they are not already loaded into the kernel. modprobe resolves dependencies recursively: it will load all dependencies of dependencies, and so on, if necessary, thus ensuring that all dependencies are always met.
-v (or --verbose) option to cause modprobe to display detailed information about what it is doing, which may include loading module dependencies.
Fibre Channel over Ethernet module verbosely by typing the following at a shell prompt:
~]# modprobe -v fcoe
insmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/scsi/scsi_tgt.ko
insmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/scsi/scsi_transport_fc.ko
insmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/scsi/libfc/libfc.ko
insmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/scsi/fcoe/libfcoe.ko
insmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/scsi/fcoe/fcoe.komodprobe loaded the scsi_tgt, scsi_transport_fc, libfc and libfcoe modules as dependencies before finally loading fcoe. Also note that modprobe used the more «primitive» insmod command to insert the modules into the running kernel.
insmod command can also be used to load kernel modules, it does not resolve dependencies. Because of this, you should always load modules using modprobe instead.
modprobe -r module_name as root. For example, assuming that the wacom module is already loaded into the kernel, you can unload it by running:
~]# modprobe -r wacom
wacom module,
wacom directly depends on, or,
wacom—through the dependency tree—depends on indirectly.
lsmod to obtain the names of the modules which are preventing you from unloading a certain module.
firewire_ohci module (because you believe there is a bug in it that is affecting system stability, for example), your terminal session might look similar to this:
~]#modinfo -F depends firewire_ohcidepends: firewire-core ~]#modinfo -F depends firewire_coredepends: crc-itu-t ~]#modinfo -F depends crc-itu-tdepends:
firewire_ohci depends on firewire_core, which itself depends on crc-itu-t.
firewire_ohci using the modprobe -v -r module_name command, where -r is short for --remove and -v for --verbose:
~]# modprobe -r -v firewire_ohci
rmmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/firewire/firewire-ohci.ko
rmmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/firewire/firewire-core.ko
rmmod /lib/modules/2.6.32-71.el6.x86_64/kernel/lib/crc-itu-t.kormmod command can be used to unload kernel modules, it is recommended to use modprobe -r instead.
modprobe -r, and then load it with modprobe along with a list of customized parameters. This method is often used when the module does not have many dependencies, or to test different combinations of parameters without making them persistent, and is the method covered in this section.
/etc/modprobe.d/ directory. This method makes the module parameters persistent by ensuring that they are set each time the module is loaded, such as after every reboot or modprobe command. This method is covered in Раздел 23.6, «Persistent Module Loading», though the following information is a prerequisite.
modprobe to load a kernel module with custom parameters using the following command line format:
modprobe module_name [parameter=value]modprobe will incorrectly interpret the values following spaces as additional parameters.
modprobe command silently succeeds with an exit status of 0 if:
modprobe command does not automatically reload the module, or alert you that it is already loaded.
e1000e module, which is the network driver for Intel PRO/1000 network adapters, as an example:
~]# lsmod | grep e1000e
~]# root:
~]# modprobe e1000e InterruptThrottleRate=3000,3000,3000 EEE=1file_name.modules/etc/sysconfig/modules/ directory, where file_name is any descriptive name of your choice. Your file_name.modules#!/bin/shfile_name.modulesmodules]# chmod +x file_name.modules
bluez-uinput.modules script loads the uinput module:
#!/bin/sh if [ ! -c /dev/input/uinput ] ; then exec /sbin/modprobe uinput >/dev/null 2>&1 fi
if-conditional statement on the third line ensures that the /dev/input/uinput file does not already exist (the ! symbol negates the condition), and, if that is the case, loads the uinput module by calling exec /sbin/modprobe uinput. Note that the uinput module creates the /dev/input/uinput file, so testing to see if that file exists serves as verification of whether the uinput module is loaded into the kernel.
>/dev/null 2>&1 clause at the end of that line redirects any output to /dev/null so that the modprobe command remains quiet.
alias and, possibly, options lines for each card in a user-created module_name.conf/etc/modprobe.d/ directory.
bonding kernel module and a special network interface, called a channel bonding interface. Channel bonding enables two or more network interfaces to act as one, simultaneously increasing the bandwidth and providing redundancy.
root, create a new file named bonding.conf/etc/modprobe.d/ directory. Note that you can name this file anything you like as long as it ends with a .conf extension. Insert the following line in this new file:
alias bondN bondingN with the interface number, such as 0. For each configured channel bonding interface, there must be a corresponding entry in your new /etc/modprobe.d/bonding.conf file.
miimon or arp_interval and the arp_ip_target parameters. Refer to Раздел 23.7.2.1, «Bonding Module Directives» for a list of available options and how to quickly determine the best ones for your bonded interface.
BONDING_OPTS="bonding parameters" directive in your bonding interface configuration file (ifcfg-bond0 for example). Parameters to bonded interfaces can be configured without unloading (and reloading) the bonding module by manipulating files in the sysfs file system.
sysfs is a virtual file system that represents kernel objects as directories, files and symbolic links. sysfs can be used to query for information about kernel objects, and can also manipulate those objects through the use of normal file system commands. The sysfs virtual file system has a line in /etc/fstab, and is mounted under the /sys/ directory. All bonding interfaces can be configured dynamically by interacting with and manipulating files under the /sys/class/net/ directory.
ifcfg-bond0 by following the instructions in Раздел 7.2.2, «Интерфейсы объединения каналов». Insert the SLAVE=yes and MASTER=bond0 directives in the configuration files for each interface bonded to bond0. Once this is completed, you can proceed to testing the parameters.
ifconfig bondN up as root:
~]# ifconfig bond0 up
ifcfg-bond0 bonding interface file, you will be able to see bond0 listed in the output of running ifconfig (without any options):
~]# ifconfig
bond0 Link encap:Ethernet HWaddr 00:00:00:00:00:00
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
eth0 Link encap:Ethernet HWaddr 52:54:00:26:9E:F1
inet addr:192.168.122.251 Bcast:192.168.122.255 Mask:255.255.255.0
inet6 addr: fe80::5054:ff:fe26:9ef1/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:207 errors:0 dropped:0 overruns:0 frame:0
TX packets:205 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:70374 (68.7 KiB) TX bytes:25298 (24.7 KiB)
[output truncated]
~]# cat /sys/class/net/bonding_masters
bond0/sys/class/net/bondN/bonding/ directory. First, the bond you are configuring must be taken down:
~]# ifconfig bond0 down
root):
~]# echo 1000 > /sys/class/net/bond0/bonding/miimon
balance-alb mode, you could run either:
~]# echo 6 > /sys/class/net/bond0/bonding/mode
~]# echo balance-alb > /sys/class/net/bond0/bonding/mode
ifconfig bondN up . If you decide to change the options, take the interface down, modify its parameters using sysfs, bring it back up, and re-test.
BONDING_OPTS= directive of the /etc/sysconfig/network-scripts/ifcfg-bondN file for the bonding interface you are configuring. Whenever that bond is brought up (for example, by the system during the boot sequence if the ONBOOT=yes directive is set), the bonding options specified in the BONDING_OPTS will take effect for that bond. For more information on configuring bonding interfaces (and BONDING_OPTS), refer to Раздел 7.2.2, «Интерфейсы объединения каналов».
parm in modinfo bonding output, or the exhaustive descriptions in the bonding.txt file in the kernel-doc package (see Раздел 23.8, «Additional Resources»).
arp_interval=time_in_milliseconds arp_interval and arp_ip_target parameters are specified, or, alternatively, the miimon parameter is specified. Failure to do so can cause degradation of network performance in the event that a link fails.
mode=0 or mode=1 (the two load-balancing modes), the network switch must be configured to distribute packets evenly across the NICs. For more information on how to accomplish this, refer to /usr/share/doc/kernel-doc-kernel_version/Documentation/networking/bonding.txt
0 by default, which disables it.
arp_ip_target=ip_address[,ip_address_2,…ip_address_16] arp_interval parameter is enabled. Up to 16 IP addresses can be specified in a comma separated list.
arp_validate=value none. Other valid values are active, backup, and all.
debug=number 0 — Debug messages are disabled. This is the default.
1 — Debug messages are enabled.
downdelay=time_in_milliseconds miimon parameter. The value is set to 0 by default, which disables it.
value slow or 0 — Default setting. This specifies that partners should transmit LACPDUs every 30 seconds.
fast or 1 — Specifies that partners should transmit LACPDUs every 1 second.
miimon=time_in_milliseconds root:
~]# ethtool interface_name | grep "Link detected:"
interface_name with the name of the device interface, such as eth0, not the bond interface. If MII is supported, the command returns:
Link detected: yes
0 (the default), turns this feature off. When configuring this setting, a good starting point for this parameter is 100.
arp_interval and arp_ip_target parameters are specified, or, alternatively, the miimon parameter is specified. Failure to do so can cause degradation of network performance in the event that a link fails.
mode=value value can be one of:
balance-rr or 0 — Sets a round-robin policy for fault tolerance and load balancing. Transmissions are received and sent out sequentially on each bonded slave interface beginning with the first one available.
active-backup or 1 — Sets an active-backup policy for fault tolerance. Transmissions are received and sent out via the first available bonded slave interface. Another bonded slave interface is only used if the active bonded slave interface fails.
balance-xor or 2 — Sets an XOR (exclusive-or) policy for fault tolerance and load balancing. Using this method, the interface matches up the incoming request's MAC address with the MAC address for one of the slave NICs. Once this link is established, transmissions are sent out sequentially beginning with the first available interface.
broadcast or 3 — Sets a broadcast policy for fault tolerance. All transmissions are sent on all slave interfaces.
802.3ad or 4 — Sets an IEEE 802.3ad dynamic link aggregation policy. Creates aggregation groups that share the same speed and duplex settings. Transmits and receives on all slaves in the active aggregator. Requires a switch that is 802.3ad compliant.
balance-tlb or 5 — Sets a Transmit Load Balancing (TLB) policy for fault tolerance and load balancing. The outgoing traffic is distributed according to the current load on each slave interface. Incoming traffic is received by the current slave. If the receiving slave fails, another slave takes over the MAC address of the failed slave.
balance-alb or 6 — Sets an Active Load Balancing (ALB) policy for fault tolerance and load balancing. Includes transmit and receive load balancing for IPV4 traffic. Receive load balancing is achieved through ARP negotiation.
num_unsol_na=number 0 - 255; the default value is 1. This parameter affects only the active-backup mode.
primary=interface_name eth0, of the primary device. The primary device is the first of the bonding interfaces to be used and is not abandoned unless it fails. This setting is particularly useful when one NIC in the bonding interface is faster and, therefore, able to handle a bigger load.
active-backup mode. Refer to /usr/share/doc/kernel-doc-kernel-version/Documentation/networking/bonding.txt for more information.
primary_reselect=value always or 0 (default) — The primary slave becomes the active slave whenever it comes back up.
better or 1 — The primary slave becomes the active slave when it comes back up, if the speed and duplex of the primary slave is better than the speed and duplex of the current active slave.
failure or 2 — The primary slave becomes the active slave only if the current active slave fails and the primary slave is up.
primary_reselect setting is ignored in two cases:
primary_reselect policy via sysfs will cause an immediate selection of the best active slave according to the new policy. This may or may not result in a change of the active slave, depending upon the circumstances
updelay=time_in_milliseconds miimon parameter. The value is set to 0 by default, which disables it.
use_carrier=number miimon should use MII/ETHTOOL ioctls or netif_carrier_ok() to determine the link state. The netif_carrier_ok() function relies on the device driver to maintains its state with netif_carrier_on/off ; most device drivers support this function.
netif_carrier_on/off .
1 — Default setting. Enables the use of netif_carrier_ok().
0 — Enables the use of MII/ETHTOOL ioctls.
netif_carrier_on/off.
xmit_hash_policy=value balance-xor and 802.3ad modes. Possible values are:
0 or layer2 — Default setting. This parameter uses the XOR of hardware MAC addresses to generate the hash. The formula used is:
(source_MAC_addressXORdestination_MAC) MODULOslave_count
1 or layer3+4 — Uses upper layer protocol information (when available) to generate the hash. This allows for traffic to a particular network peer to span multiple slaves, although a single connection will not span multiple slaves.
((source_portXORdest_port) XOR ((source_IPXORdest_IP) AND0xffff) MODULOslave_count
layer2 transmit hash policy.
2 or layer2+3 — Uses a combination of layer2 and layer3 protocol information to generate the hash.
(((source_IPXORdest_IP) AND0xffff) XOR (source_MACXORdestination_MAC)) MODULOslave_count
man lsmodlsmod command.
man modinfomodinfo command.
man modprobemodprobe command.
man rmmodrmmod command.
man ethtoolethtool command.
man mii-toolmii-tool command.
/usr/share/doc/kernel-doc-kernel_version/Documentation/root:
yum install kernel-doce1000e driver.
kdump crash dumping mechanism is enabled, the system is booted from the context of another kernel. This second kernel reserves a small amount of memory and its only purpose is to capture the core dump image in case the system crashes.
kdump service in Fedora, and provides a brief overview of how to analyze the resulting core dump using the crash debugging utility.
kdump service on your system, make sure you have the kexec-tools package installed. To do so, type the following at a shell prompt as root:
yum install kexec-toolskdump service: at the first boot, using the Kernel Dump Configuration graphical utility, and doing so manually on the command line.
Intel IOMMU driver can occasionally prevent the kdump service from capturing the core dump image. To use kdump on Intel architectures reliably, it is advised that the IOMMU support is disabled.
kdump, navigate to the Kdump section and follow the instructions below.
kdump crash recovery is enabled, the minimum memory requirements increase by the amount of memory reserved for it. This value is determined by the user, and defaults to 128 MB plus 64 MB for each TB of physical memory (that is, a total of 192 MB for a system with 1 TB of physical memory).
kdump daemon to start at boot time, select the Enable kdump? checkbox. This will enable the service and start it for the current session. Similarly, unselecting the checkbox will disable it for and stop the service immediately.
kdump kernel, click the up and down arrow buttons next to the Kdump Memory field to increase or decrease the value. Notice that the Usable System Memory field changes accordingly showing you the remaining memory that will be available to the system.
system-config-kdump at a shell prompt. You will be presented with a window as shown in Рисунок 24.1, «Basic Settings».
kdump as well as to enable or disable starting the service at boot time. When you are done, click to save the changes. The system reboot will be requested, and unless you are already authenticated, you will be prompted to enter the superuser password.
kdump crash recovery is enabled, the minimum memory requirements increase by the amount of memory reserved for it. This value is determined by the user, and defaults to 128 MB plus 64 MB for each TB of physical memory (that is, a total of 192 MB for a system with 1 TB of physical memory).
kdump daemon at boot time, click the button on the toolbar. This will enable the service and start it for the current session. Similarly, clicking the button will disable it and stop the service immediately.
kdump kernel. To do so, select the Manual kdump memory settings radio button, and click the up and down arrow buttons next to the New kdump Memory field to increase or decrease the value. Notice that the Usable Memory field changes accordingly showing you the remaining memory that will be available to the system.
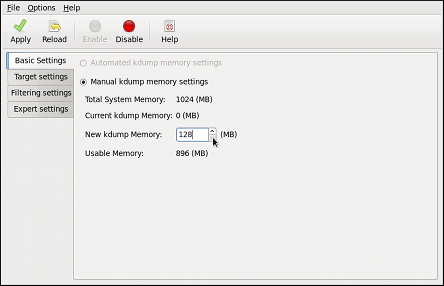
vmcore dump. It can be either stored as a file in a local file system, written directly to a device, or sent over a network using the NFS (Network File System) or SSH (Secure Shell) protocol.
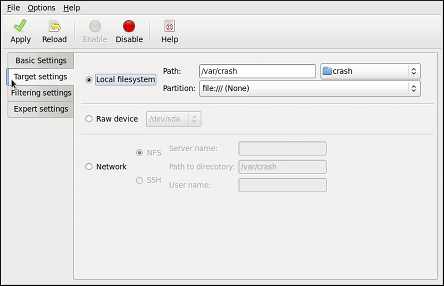
| Type | Supported Targets | Unsupported Targets |
|---|---|---|
| Raw device | All locally attached raw disks and partitions. | — |
| Local file system |
ext2, ext3, ext4, minix file systems on directly attached disk drives, hardware RAID logical drives, LVM devices, and mdraid arrays.
|
The eCryptfs file system.
|
| Remote directory |
Remote directories accessed using the NFS or SSH protocol over IPv4.
|
Remote directories on the rootfs file system accessed using the NFS protocol.
|
Remote directories accessed using the iSCSI protocol over hardware initiators.
|
Remote directories accessed using the iSCSI protocol over software initiators.
| |
| — |
Remote directories accessed over IPv6.
| |
Remote directories accessed using the SMB/CIFS protocol.
| ||
Remote directories accessed using the FCoE (Fibre Channel over Ethernet) protocol.
| ||
| Remote directories accessed using wireless network interfaces. | ||
| Multipath-based storages. |
vmcore dump.
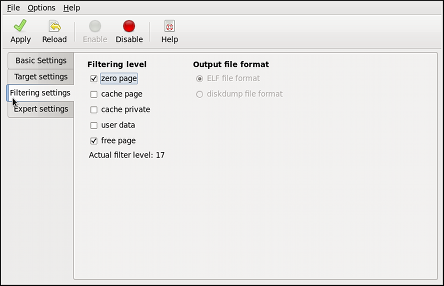
kdump fails to create a core dump, select an appropriate option from the Default action pulldown list. Available options are (the default action), (to reboot the system), (to present a user with an interactive shell prompt), (to halt the system), and (to power the system off).
makedumpfile core collector, edit the Core collector text field; see Раздел 24.2.3.3, «Configuring the Core Collector» for more information.
kdump kernel, as root, edit the /etc/default/grub file and add the crashkernel=<size>M (or crashkernel=auto) parameter to the list of kernel options (the GRUB_CMDLINE_LINUX line). For example, to reserve 128 MB of memory, use:
GRUB_CMDLINE_LINUX="crashkernel=128M quiet rhgb"root:
grub2-mkconfig-o/boot/grub2/grub.cfg
kdump crash recovery is enabled, the minimum memory requirements increase by the amount of memory reserved for it. This value is determined by the user, and defaults to 128 MB plus 64 MB for each TB of physical memory (that is, a total of 192 MB for a system with 1 TB of physical memory).
crashkernel=auto only reserves memory if the system has 4 GB of physical memory or more.
vmcore file in the /var/crash/ directory of the local file system. To change this, as root, open the /etc/kdump.conf configuration file in a text editor and edit the options as described below.
#path /var/crash line, and replace the value with a desired directory path. Optionally, if you wish to write the file to a different partition, follow the same procedure with the #ext4 /dev/sda3 line as well, and change both the file system type and the device (a device name, a file system label, and UUID are all supported) accordingly. For example:
ext3 /dev/sda4 path /usr/local/cores
#raw /dev/sda5 line, and replace the value with a desired device name. For example:
raw /dev/sdb1
#net my.server.com:/export/tmp line, and replace the value with a valid hostname and directory path. For example:
net penguin.example.com:/export/cores
#net user@my.server.com line, and replace the value with a valid username and hostname. For example:
net john@penguin.example.com
vmcore dump file, kdump allows you to specify an external application (that is, a core collector) to compress the data, and optionally leave out all irrelevant information. Currently, the only fully supported core collector is makedumpfile.
root, open the /etc/kdump.conf configuration file in a text editor, remove the hash sign («#») from the beginning of the #core_collector makedumpfile -c --message-level 1 -d 31 line, and edit the command line options as described below.
-c parameter. For example:
core_collector makedumpfile -c
-d value parameter, where value is a sum of values of pages you want to omit as described in Таблица 24.2, «Supported filtering levels». For example, to remove both zero and free pages, use the following:
core_collector makedumpfile -d 17 -c
makedumpfile for a complete list of available options.
| Option | Description |
|---|---|
1
| Zero pages |
2
| Cache pages |
4
| Cache private |
8
| User pages |
16
| Free pages |
kdump fails to create a core dump, the root file system is mounted and /sbin/init is run. To change this behavior, as root, open the /etc/kdump.conf configuration file in a text editor, remove the hash sign («#») from the beginning of the #default shell line, and replace the value with a desired action as described in Таблица 24.3, «Supported actions».
| Option | Description |
|---|---|
reboot
| Reboot the system, losing the core in the process. |
halt
| Halt the system. |
poweroff
| Power off the system. |
shell
| Run the msh session from within the initramfs, allowing a user to record the core manually. |
default halt
kdump daemon at boot time, type the following at a shell prompt as root:
systemctlenablekdump.service
systemctl disable kdump.service will disable it. To start the service in the current session, use the following command as root:
systemctlstartkdump.service
kdump enabled, and make sure that the service is running (refer to Раздел 8.2, «Running Services» for more information on how to run a service in Fedora):
systemctl is-active kdump.serviceecho 1 > /proc/sys/kernel/sysrqecho c > /proc/sysrq-trigger
address-YYYY-MM-DD-HH:MM:SS/vmcore/var/crash/ by default).
netdump, diskdump, xendump, or kdump.
vmcore dump file, you must have the crash and kernel-debuginfo packages installed. To install these packages, type the following at a shell prompt as root:
yum install crashdebuginfo-install kernel
crash/var/crash/timestamp/vmcore/usr/lib/debug/lib/modules/kernel/vmlinux
kernel version should be the same that was captured by kdump. To find out which kernel you are currently running, use the uname -r command.
~]#crash /usr/lib/debug/lib/modules/2.6.32-69.el6.i686/vmlinux \/var/crash/127.0.0.1-2010-08-25-08:45:02/vmcorecrash 5.0.0-23.el6 Copyright (C) 2002-2010 Red Hat, Inc. Copyright (C) 2004, 2005, 2006 IBM Corporation Copyright (C) 1999-2006 Hewlett-Packard Co Copyright (C) 2005, 2006 Fujitsu Limited Copyright (C) 2006, 2007 VA Linux Systems Japan K.K. Copyright (C) 2005 NEC Corporation Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc. Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc. This program is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Enter "help copying" to see the conditions. This program has absolutely no warranty. Enter "help warranty" for details. GNU gdb (GDB) 7.0 Copyright (C) 2009 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "i686-pc-linux-gnu"... KERNEL: /usr/lib/debug/lib/modules/2.6.32-69.el6.i686/vmlinux DUMPFILE: /var/crash/127.0.0.1-2010-08-25-08:45:02/vmcore [PARTIAL DUMP] CPUS: 4 DATE: Wed Aug 25 08:44:47 2010 UPTIME: 00:09:02 LOAD AVERAGE: 0.00, 0.01, 0.00 TASKS: 140 NODENAME: hp-dl320g5-02.lab.bos.redhat.com RELEASE: 2.6.32-69.el6.i686 VERSION: #1 SMP Tue Aug 24 10:31:45 EDT 2010 MACHINE: i686 (2394 Mhz) MEMORY: 8 GB PANIC: "Oops: 0002 [#1] SMP " (check log for details) PID: 5591 COMMAND: "bash" TASK: f196d560 [THREAD_INFO: ef4da000] CPU: 2 STATE: TASK_RUNNING (PANIC) crash>
log command at the interactive prompt.
crash> log
... several lines omitted ...
EIP: 0060:[<c068124f>] EFLAGS: 00010096 CPU: 2
EIP is at sysrq_handle_crash+0xf/0x20
EAX: 00000063 EBX: 00000063 ECX: c09e1c8c EDX: 00000000
ESI: c0a09ca0 EDI: 00000286 EBP: 00000000 ESP: ef4dbf24
DS: 007b ES: 007b FS: 00d8 GS: 00e0 SS: 0068
Process bash (pid: 5591, ti=ef4da000 task=f196d560 task.ti=ef4da000)
Stack:
c068146b c0960891 c0968653 00000003 00000000 00000002 efade5c0 c06814d0
<0> fffffffb c068150f b7776000 f2600c40 c0569ec4 ef4dbf9c 00000002 b7776000
<0> efade5c0 00000002 b7776000 c0569e60 c051de50 ef4dbf9c f196d560 ef4dbfb4
Call Trace:
[<c068146b>] ? __handle_sysrq+0xfb/0x160
[<c06814d0>] ? write_sysrq_trigger+0x0/0x50
[<c068150f>] ? write_sysrq_trigger+0x3f/0x50
[<c0569ec4>] ? proc_reg_write+0x64/0xa0
[<c0569e60>] ? proc_reg_write+0x0/0xa0
[<c051de50>] ? vfs_write+0xa0/0x190
[<c051e8d1>] ? sys_write+0x41/0x70
[<c0409adc>] ? syscall_call+0x7/0xb
Code: a0 c0 01 0f b6 41 03 19 d2 f7 d2 83 e2 03 83 e0 cf c1 e2 04 09 d0 88 41 03 f3 c3 90 c7 05 c8 1b 9e c0 01 00 00 00 0f ae f8 89 f6 <c6> 05 00 00 00 00 01 c3 89 f6 8d bc 27 00 00 00 00 8d 50 d0 83
EIP: [<c068124f>] sysrq_handle_crash+0xf/0x20 SS:ESP 0068:ef4dbf24
CR2: 0000000000000000help log for more information on the command usage.
bt command at the interactive prompt. You can use bt pid to display the backtrace of the selected process.
crash> bt
PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash"
#0 [ef4dbdcc] crash_kexec at c0494922
#1 [ef4dbe20] oops_end at c080e402
#2 [ef4dbe34] no_context at c043089d
#3 [ef4dbe58] bad_area at c0430b26
#4 [ef4dbe6c] do_page_fault at c080fb9b
#5 [ef4dbee4] error_code (via page_fault) at c080d809
EAX: 00000063 EBX: 00000063 ECX: c09e1c8c EDX: 00000000 EBP: 00000000
DS: 007b ESI: c0a09ca0 ES: 007b EDI: 00000286 GS: 00e0
CS: 0060 EIP: c068124f ERR: ffffffff EFLAGS: 00010096
#6 [ef4dbf18] sysrq_handle_crash at c068124f
#7 [ef4dbf24] __handle_sysrq at c0681469
#8 [ef4dbf48] write_sysrq_trigger at c068150a
#9 [ef4dbf54] proc_reg_write at c0569ec2
#10 [ef4dbf74] vfs_write at c051de4e
#11 [ef4dbf94] sys_write at c051e8cc
#12 [ef4dbfb0] system_call at c0409ad5
EAX: ffffffda EBX: 00000001 ECX: b7776000 EDX: 00000002
DS: 007b ESI: 00000002 ES: 007b EDI: b7776000
SS: 007b ESP: bfcb2088 EBP: bfcb20b4 GS: 0033
CS: 0073 EIP: 00edc416 ERR: 00000004 EFLAGS: 00000246help bt for more information on the command usage.
ps command at the interactive prompt. You can use ps pid to display the status of the selected process.
crash> ps
PID PPID CPU TASK ST %MEM VSZ RSS COMM
> 0 0 0 c09dc560 RU 0.0 0 0 [swapper]
> 0 0 1 f7072030 RU 0.0 0 0 [swapper]
0 0 2 f70a3a90 RU 0.0 0 0 [swapper]
> 0 0 3 f70ac560 RU 0.0 0 0 [swapper]
1 0 1 f705ba90 IN 0.0 2828 1424 init
... several lines omitted ...
5566 1 1 f2592560 IN 0.0 12876 784 auditd
5567 1 2 ef427560 IN 0.0 12876 784 auditd
5587 5132 0 f196d030 IN 0.0 11064 3184 sshd
> 5591 5587 2 f196d560 RU 0.0 5084 1648 bashhelp ps for more information on the command usage.
vm command at the interactive prompt. You can use vm pid to display information on the selected process.
crash> vm
PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash"
MM PGD RSS TOTAL_VM
f19b5900 ef9c6000 1648k 5084k
VMA START END FLAGS FILE
f1bb0310 242000 260000 8000875 /lib/ld-2.12.so
f26af0b8 260000 261000 8100871 /lib/ld-2.12.so
efbc275c 261000 262000 8100873 /lib/ld-2.12.so
efbc2a18 268000 3ed000 8000075 /lib/libc-2.12.so
efbc23d8 3ed000 3ee000 8000070 /lib/libc-2.12.so
efbc2888 3ee000 3f0000 8100071 /lib/libc-2.12.so
efbc2cd4 3f0000 3f1000 8100073 /lib/libc-2.12.so
efbc243c 3f1000 3f4000 100073
efbc28ec 3f6000 3f9000 8000075 /lib/libdl-2.12.so
efbc2568 3f9000 3fa000 8100071 /lib/libdl-2.12.so
efbc2f2c 3fa000 3fb000 8100073 /lib/libdl-2.12.so
f26af888 7e6000 7fc000 8000075 /lib/libtinfo.so.5.7
f26aff2c 7fc000 7ff000 8100073 /lib/libtinfo.so.5.7
efbc211c d83000 d8f000 8000075 /lib/libnss_files-2.12.so
efbc2504 d8f000 d90000 8100071 /lib/libnss_files-2.12.so
efbc2950 d90000 d91000 8100073 /lib/libnss_files-2.12.so
f26afe00 edc000 edd000 4040075
f1bb0a18 8047000 8118000 8001875 /bin/bash
f1bb01e4 8118000 811d000 8101873 /bin/bash
f1bb0c70 811d000 8122000 100073
f26afae0 9fd9000 9ffa000 100073
... several lines omitted ...help vm for more information on the command usage.
files command at the interactive prompt. You can use files pid to display files opened by the selected process.
crash> files
PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash"
ROOT: / CWD: /root
FD FILE DENTRY INODE TYPE PATH
0 f734f640 eedc2c6c eecd6048 CHR /pts/0
1 efade5c0 eee14090 f00431d4 REG /proc/sysrq-trigger
2 f734f640 eedc2c6c eecd6048 CHR /pts/0
10 f734f640 eedc2c6c eecd6048 CHR /pts/0
255 f734f640 eedc2c6c eecd6048 CHR /pts/0help files for more information on the command usage.
exit or q.
crash> exit
~]#/etc/kdump.conf configuration file containing the full documentation of available options.
makedumpfile core collector.
/usr/share/doc/kexec-tools-version/kexec-kdump-howto.txt — an overview of the kdump and kexec installation and usage.
kexec and kdump configuration.
kdump targets.
eth[0123…], but these names do not necessarily correspond to actual labels on the chassis. Modern server platforms with multiple network adapters can encounter non-deterministic and counter-intuitive naming of these interfaces. This affects both network adapters embedded on the motherboard (Lan-on-Motherboard, or LOM) and add-in (single and multiport) adapters.
eth[0123…] to the new naming convention as shown in Таблица A.1, «The new naming convention».
| Устройство | Old Name | New Name |
|---|---|---|
| Embedded network interface (LOM) |
eth[0123…]
|
em[1234…][a]
|
| PCI card network interface |
eth[0123…]
|
p<[b]
|
| Virtual function |
eth[0123…]
|
p<[c]
|
[a]
New enumeration starts at 1.
[b]
For example: p3p4
[c]
For example: p3p4_1
| ||
/etc/udev/rules.d/70-persistent-net.rules to change the device names to anything desired; those will take precedence over this physical location naming convention.
base package group in Fedora 17. All install options, except for , include this package.
biosdevname=0biosdevname=1biosdevname install option is specified, it must remain as a boot option for the lifetime of the system.
ksdevice parameter; these kickstart files will need to be updated to use the network device's MAC address or the network device's new name.
/etc/udev/rules.d/70-persistent-net.rules file and the HWADDR lines from all /etc/sysconfig/network-scripts/ifcfg-* files. In addition, rename those ifcfg-* files to use this new naming convention. The new names will be in effect after reboot. Remember to update any custom scripts, iptables rules, and service configuration files that might include network interface names.
x86_64.rpm.
.tar.gz files.
rpm --help or man rpm. You can also refer to Раздел B.5, «Дополнительные ресурсы» for more information on RPM.
tree-1.5.3-2.fc17.x86_64.rpm. The file name includes the package name (tree), version (1.5.3), release (2), operating system major version (fc17) and CPU architecture (x86_64).
rpm's -U option to:
rpm -U <rpm_file> is able to perform the function of either upgrading or installing as is appropriate for the package.
tree-1.5.3-2.fc17.x86_64.rpm package is in the current directory, log in as root and type the following command at a shell prompt to either upgrade or install the tree package as determined by rpm:
rpm -Uvh tree-1.5.3-2.fc17.x86_64.rpm
-v and -h options (which are combined with -U) cause rpm to print more verbose output and display a progress meter using hash signs.
Preparing... ########################################### [100%] 1:tree ########################################### [100%]
rpm provides two different options for installing packages: the aforementioned -U option (which historically stands for upgrade), and the -i option, historically standing for install. Because the -U option subsumes both install and upgrade functions, we recommend to use rpm -Uvh with all packages except kernel packages.
-i option to simply install a new kernel package instead of upgrading it. This is because using the -U option to upgrade a kernel package removes the previous (older) kernel package, which could render the system unable to boot if there is a problem with the new kernel. Therefore, use the rpm -i <kernel_package> command to install a new kernel without replacing any older kernel packages. For more information on installing kernel packages, refer to Глава 22, Ручное обновление ядра.
error: tree-1.5.2.2-4.fc17.x86_64.rpm: Header V3 RSA/SHA256 signature: BAD, key ID d22e77f2
error: tree-1.5.2.2-4.fc17.x86_64.rpm: Header V3 RSA/SHA256 signature: BAD, key ID d22e77f2
NOKEY:
warning: tree-1.5.2.2-4.fc17.x86_64.rpm: Header V3 RSA/SHA1 signature: NOKEY, key ID 57bbccba
Preparing... ########################################### [100%] package tree-1.5.3-2.fc17.x86_64 is already installed
--replacepkgs option, which tells RPM to ignore the error:
rpm -Uvh --replacepkgs tree-1.5.3-2.fc17.x86_64.rpm
Preparing... ################################################## file /usr/bin/foobar from install of foo-1.0-1.fc17.x86_64 conflicts with file from package bar-3.1.1.fc17.x86_64
--replacefiles option:
rpm -Uvh --replacefiles foo-1.0-1.fc17.x86_64.rpm
error: Failed dependencies: bar.so.3()(64bit) is needed by foo-1.0-1.fc17.x86_64
rpm -Uvh foo-1.0-1.fc17.x86_64.rpm bar-3.1.1.fc17.x86_64.rpm
Preparing... ########################################### [100%] 1:foo ########################################### [ 50%] 2:bar ########################################### [100%]
--whatprovides option to determine which package contains the required file.
rpm -q --whatprovides "bar.so.3"
bar.so.3 is in the RPM database, the name of the package is displayed:
bar-3.1.1.fc17.i586.rpm
rpm to install a package that gives us a Failed dependencies error (using the --nodeps option), this is not recommended, and will usually result in the installed package failing to run. Installing or removing packages with rpm --nodeps can cause applications to misbehave and/or crash, and can cause serious package management problems or, possibly, system failure. For these reasons, it is best to heed such warnings; the package manager—whether RPM, Yum or PackageKit—shows us these warnings and suggests possible fixes because accounting for dependencies is critical. The Yum package manager can perform dependency resolution and fetch dependencies from online repositories, making it safer, easier and smarter than forcing rpm to carry out actions without regard to resolving dependencies.
saving /etc/foo.conf as /etc/foo.conf.rpmsave
foo.conf.rpmnew, and leave the configuration file you modified untouched. You should still resolve any conflicts between your modified configuration file and the new one, usually by merging changes from the old one to the new one with a diff program.
package foo-2.0-1.fc17.x86_64.rpm (which is newer than foo-1.0-1) is already installed
--oldpackage option:
rpm -Uvh --oldpackage foo-1.0-1.fc17.x86_64.rpm
rpm -e foo
foo, not the name of the original package file, foo-1.0-1.fc17.x86_64. If you attempt to uninstall a package using the rpm -e command and the original full file name, you will receive a package name error.
rpm -e ghostscript
error: Failed dependencies:
libgs.so.8()(64bit) is needed by (installed) libspectre-0.2.2-3.fc17.x86_64
libgs.so.8()(64bit) is needed by (installed) foomatic-4.0.3-1.fc17.x86_64
libijs-0.35.so()(64bit) is needed by (installed) gutenprint-5.2.4-5.fc17.x86_64
ghostscript is needed by (installed) printer-filters-1.1-4.fc17.noarch<library_name>.so.<number> ~]# rpm -q --whatprovides "libgs.so.8()(64bit)"
ghostscript-8.70-1.fc17.x86_64rpm to remove a package that gives us a Failed dependencies error (using the --nodeps option), this is not recommended, and may cause harm to other installed applications. Installing or removing packages with rpm --nodeps can cause applications to misbehave and/or crash, and can cause serious package management problems or, possibly, system failure. For these reasons, it is best to heed such warnings; the package manager—whether RPM, Yum or PackageKit—shows us these warnings and suggests possible fixes because accounting for dependencies is critical. The Yum package manager can perform dependency resolution and fetch dependencies from online repositories, making it safer, easier and smarter than forcing rpm to carry out actions without regard to resolving dependencies.
rpm -Fvh foo-2.0-1.fc17.x86_64.rpm
*.rpm glob:
rpm -Fvh *.rpm
/var/lib/rpm/, and is used to query what packages are installed, what versions each package is, and to calculate any changes to any files in the package since installation, among other use cases.
-q option. The rpm -q package name command displays the package name, version, and release number of the installed package <package_name>. For example, using rpm -q tree to query installed package tree might generate the following output:
tree-1.5.2.2-4.fc17.x86_64
man rpm for details) to further refine or qualify your query:
-a — queries all currently installed packages.
-f <file_name> — queries the RPM database for which package owns <file_name> rpm -qf /bin/ls instead of rpm -qf ls).
-p <package_file> — queries the uninstalled package <package_file> -i displays package information including name, description, release, size, build date, install date, vendor, and other miscellaneous information.
-l displays the list of files that the package contains.
-s displays the state of all the files in the package.
-d displays a list of files marked as documentation (man pages, info pages, READMEs, etc.) in the package.
-c displays a list of files marked as configuration files. These are the files you edit after installation to adapt and customize the package to your system (for example, sendmail.cf, passwd, inittab, etc.).
-v to the command to display the lists in a familiar ls -l format.
rpm -V verifies a package. You can use any of the Verify Options listed for querying to specify the packages you wish to verify. A simple use of verifying is rpm -V tree, which verifies that all the files in the tree package are as they were when they were originally installed. For example:
rpm -Vf /usr/bin/tree
/usr/bin/tree is the absolute path to the file used to query a package.
rpm -Va
rpm -Vp tree-1.5.2.2-4.fc17.x86_64.rpm
c" denotes a configuration file) and then the file name. Each of the eight characters denotes the result of a comparison of one attribute of the file to the value of that attribute recorded in the RPM database. A single period (.) means the test passed. The following characters denote specific discrepancies:
5 — MD5 checksum
S — file size
L — symbolic link
T — file modification time
D — device
U — user
G — group
M — mode (includes permissions and file type)
? — unreadable file (file permission errors, for example)
<rpm_file> is the file name of the RPM package):
rpm -K --nosignature <rpm_file>
<rpm_file>: rsa sha1 (md5) pgp md5 OK-K на -Kvv.
x files as well.
/etc/pki/rpm-gpg/. Чтобы проверить пакет Проекта Fedora, сначала импортируйте верный ключ для архитектуры вашего процессора:
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-fedora-x86_64
rpm -qa gpg-pubkey*
gpg-pubkey-57bbccba-4a6f97af
rpm -qi с учетом вывода предыдущей команды:
rpm -qi gpg-pubkey-57bbccba-4a6f97af
<rpm_file> with the file name of the RPM package):
rpm -K <rpm_file>
rsa sha1 (md5) pgp md5 OK. This means that the signature of the package has been verified, that it is not corrupt, and is therefore safe to install and use.
rpm -Va
rpm -qf /usr/bin/ghostscript
ghostscript-8.70-1.fc17.x86_64
/usr/bin/paste. You would like to verify the package that owns that program, but you do not know which package owns paste. Enter the following command,
rpm -Vf /usr/bin/paste
rpm -qdf /usr/bin/free
/usr/share/doc/procps-3.2.8/BUGS /usr/share/doc/procps-3.2.8/FAQ /usr/share/doc/procps-3.2.8/NEWS /usr/share/doc/procps-3.2.8/TODO /usr/share/man/man1/free.1.gz /usr/share/man/man1/pgrep.1.gz /usr/share/man/man1/pkill.1.gz /usr/share/man/man1/pmap.1.gz /usr/share/man/man1/ps.1.gz /usr/share/man/man1/pwdx.1.gz /usr/share/man/man1/skill.1.gz /usr/share/man/man1/slabtop.1.gz /usr/share/man/man1/snice.1.gz /usr/share/man/man1/tload.1.gz /usr/share/man/man1/top.1.gz /usr/share/man/man1/uptime.1.gz /usr/share/man/man1/w.1.gz /usr/share/man/man1/watch.1.gz /usr/share/man/man5/sysctl.conf.5.gz /usr/share/man/man8/sysctl.8.gz /usr/share/man/man8/vmstat.8.gz
rpm -qip crontabs-1.10-31.fc17.noarch.rpm
Name : crontabs Relocations: (not relocatable) Size : 2486 License: Public Domain and GPLv2 Signature : RSA/SHA1, Tue 11 Aug 2009 01:11:19 PM CEST, Key ID 9d1cc34857bbccba Packager : Fedora Project Summary : Root crontab files used to schedule the execution of programs Description : The crontabs package contains root crontab files and directories. You will need to install cron daemon to run the jobs from the crontabs. The cron daemon such as cronie or fcron checks the crontab files to see when particular commands are scheduled to be executed. If commands are scheduled, it executes them. Crontabs handles a basic system function, so it should be installed on your system.
crontabs RPM package installs. You would enter the following:
rpm -qlp crontabs-1.10-31.fc17.noarch.rpm
/etc/cron.daily /etc/cron.hourly /etc/cron.monthly /etc/cron.weekly /etc/crontab /usr/bin/run-parts /usr/share/man/man4/crontabs.4.gz
rpm --help — This command displays a quick reference of RPM parameters.
man rpm — The RPM man page gives more detail about RPM parameters than the rpm --help command.
Xorg binary) listens for connections from X client applications via a network or local loopback interface. The server communicates with the hardware, such as the video card, monitor, keyboard, and mouse. X client applications exist in the user space, creating a graphical user interface (GUI) for the user and passing user requests to the X server.
evdev, that supports all input devices that the kernel knows about, including most mice and keyboards.
/usr/ directory. The /etc/X11/ directory contains configuration files for X client and server applications. This includes configuration files for the X server itself, the X display managers, and many other base components.
/etc/fonts/fonts.conf. For more information on configuring and adding fonts, refer to Раздел C.4, «Fonts».
metacity kwin compiz compiz package.
mwm mwm) is a basic, stand-alone window manager. Since it is designed to be stand-alone, it should not be used in conjunction with GNOME or KDE. To run this window manager, you need to install the openmotif package.
twm twm), which provides the most basic tool set among the available window managers, can be used either as a stand-alone or with a desktop environment. To run this window manager, you need to install the xorg-x11-twm package.
/usr/bin/Xorg; a symbolic link X pointing to this file is also provided. Associated configuration files are stored in the /etc/X11/ and /usr/share/X11/ directories.
xorg.conf.d directory contain preconfigured settings from vendors and from distribution, and these files should not be edited by hand. Configuration in the xorg.conf file, on the other hand, is done completely by hand but is not necessary in most scenarios.
/etc/X11/xorg.conf, that was necessary in previous releases, is not supplied with the current release of the X Window System. It can still be useful to create the file manually to configure new hardware, to set up an environment with multiple video cards, or for debugging purposes.
/usr/lib/xorg/modules/ (or /usr/lib64/xorg/modules/) directory contains X server modules that can be loaded dynamically at runtime. By default, only some modules in /usr/lib/xorg/modules/ are automatically loaded by the X server.
mouse, kbd, or vmmouse driver configured in the xorg.conf file are, by default, ignored by the X server. Refer to Раздел C.3.3.3, «The ServerFlags section» for further details. Additional configuration is provided in the /etc/X11/xorg.conf.d/ directory and it can override or augment any configuration that has been obtained through HAL.
Section "section-name" line, where "section-name" is the title for the section, and ends with an EndSection line. Each section contains lines that include option names and one or more option values. Some of these are sometimes enclosed in double quotes (").
/etc/X11/xorg.conf file accept a boolean switch which turns the feature on or off. The acceptable values are:
1, on, true, or yes — Turns the option on.
0, off, false, or no — Turns the option off.
#) are not read by the X server and are used for human-readable comments.
# This file is autogenerated by system-setup-keyboard. Any # modifications will be lost. Section "InputClass" Identifier "system-setup-keyboard" MatchIsKeyboard "on" Option "XkbModel" "pc105" Option "XkbLayout" "cz,us" # Option "XkbVariant" "(null)" Option "XkbOptions" "terminate:ctrl_alt_bksp,grp:shifts_toggle,grp_led:scroll" EndSection
xorg.conf.d Directory/usr/share/X11/xorg.conf.d/ provides separate configuration files from vendors or third-party packages; changes to files in this directory may be overwritten by settings specified in the /etc/X11/xorg.conf file. The /etc/X11/xorg.conf.d/ directory stores user-specific configuration.
.conf in configuration directories are parsed by the X server upon startup and are treated like part of the traditional xorg.conf configuration file. These files may contain one or more sections; for a description of the options in a section and the general layout of the configuration file, refer to Раздел C.3.3, «The xorg.conf File» or to the xorg.conf(5) man page. The X server essentially treats the collection of configuration files as one big file with entries from xorg.conf at the end. Users are encouraged to put custom configuration into /etc/xorg.conf and leave the directory for configuration snippets provided by the distribution.
xorg.conf File/etc/X11/xorg.conf file was used to store initial setup for X. When a change occurred with the monitor, video card or other device managed by the X server, the file needed to be edited manually. In Fedora, there is rarely a need to manually create and edit the /etc/X11/xorg.conf file. Nevertheless, it is still useful to understand various sections and optional parameters available, especially when troubleshooting or setting up unusual hardware configuration.
/etc/X11/xorg.conf file. More detailed information about the X server configuration file can be found in the xorg.conf(5) man page. This section is mostly intended for advanced users as most configuration options described below are not needed in typical configuration scenarios.
InputClass sectionInputClass is a new type of configuration section that does not apply to a single device but rather to a class of devices, including hot-plugged devices. An InputClass section's scope is limited by the matches specified; in order to apply to an input device, all matches must apply to the device as seen in the example below:
Section "InputClass" Identifier "touchpad catchall" MatchIsTouchpad "on" Driver "synaptics" EndSection
xorg.conf file or an xorg.conf.d directory, any touchpad present in the system is assigned the synaptics driver.
xorg.conf.dxorg.conf.d directory, the Driver setting in the example above overwrites previously set driver options. The more generic the class, the earlier it should be listed.
InputClass section:
MatchIsPointer, MatchIsKeyboard, MatchIsTouchpad, MatchIsTouchscreen, MatchIsJoystick — boolean options to specify a type of a device.
MatchProduct "product_name" — this option matches if the product_name substring occurs in the product name of the device.
MatchVendor "vendor_name" — this option matches if the vendor_name substring occurs in the vendor name of the device.
MatchDevicePath "/path/to/device" — this option matches any device if its device path corresponds to the patterns given in the "/path/to/device" template, for example /dev/input/event*. Refer to the fnmatch(3) man page for further details.
MatchTag "tag_pattern" — this option matches if at least one tag assigned by the HAL configuration back end matches the tag_pattern pattern.
InputClass sections. These sections are optional and are used to configure a class of input devices as they are automatically added. An input device can match more than one InputClass section. When arranging these sections, it is recommended to put generic matches above specific ones because each input class can override settings from a previous one if an overlap occurs.
InputDevice sectionInputDevice section configures one input device for the X server. Previously, systems typically had at least one InputDevice section for the keyboard, and most mouse settings were automatically detected.
InputDevice configuration is needed for most setups, and the xorg-x11-drv-* input driver packages provide the automatic configuration through HAL. The default driver for both keyboards and mice is evdev.
InputDevice section for a keyboard:
Section "InputDevice" Identifier "Keyboard0" Driver "kbd" Option "XkbModel" "pc105" Option "XkbLayout" "us" EndSection
InputDevice section:
Identifier — Specifies a unique name for this InputDevice section. This is a required entry.
Driver — Specifies the name of the device driver X must load for the device. If the AutoAddDevices option is enabled (which is the default setting), any input device section with Driver "mouse" or Driver "kbd" will be ignored. This is necessary due to conflicts between the legacy mouse and keyboard drivers and the new evdev generic driver. Instead, the server will use the information from the back end for any input devices. Any custom input device configuration in the xorg.conf should be moved to the back end. In most cases, the back end will be HAL and the configuration location will be the /etc/X11/xorg.conf.d directory.
Option — Specifies necessary options pertaining to the device.
xorg.conf file:
Protocol — Specifies the protocol used by the mouse, such as IMPS/2.
Device — Specifies the location of the physical device.
Emulate3Buttons — Specifies whether to allow a two-button mouse to act like a three-button mouse when both mouse buttons are pressed simultaneously.
xorg.conf(5) man page for a complete list of valid options for this section.
ServerFlags sectionServerFlags section contains miscellaneous global X server settings. Any settings in this section may be overridden by options placed in the ServerLayout section (refer to Раздел C.3.3.4, «ServerLayout» for details).
ServerFlags section occupies a single line and begins with the term Option followed by an option enclosed in double quotation marks (").
ServerFlags section:
Section "ServerFlags" Option "DontZap" "true" EndSection
"DontZap" "boolean" — When the value of <boolean> is set to true, this setting prevents the use of the Ctrl+Alt+Backspace key combination to immediately terminate the X server.
setxkbmap -option "terminate:ctrl_alt_bksp""DontZoom" "boolean" — When the value of <boolean> is set to true, this setting prevents cycling through configured video resolutions using the Ctrl+Alt+Keypad-Plus and Ctrl+Alt+Keypad-Minus key combinations.
"AutoAddDevices" "boolean" — When the value of <boolean> is set to false, the server will not hot plug input devices and instead rely solely on devices configured in the xorg.conf file. Refer to Раздел C.3.3.2, «The InputDevice section» for more information concerning input devices. This option is enabled by default and HAL (hardware abstraction layer) is used as a back end for device discovery.
ServerLayoutServerLayout section binds together the input and output devices controlled by the X server. At a minimum, this section must specify one input device and one output device. By default, a monitor (output device) and a keyboard (input device) are specified.
ServerLayout section:
Section "ServerLayout" Identifier "Default Layout" Screen 0 "Screen0" 0 0 InputDevice "Mouse0" "CorePointer" InputDevice "Keyboard0" "CoreKeyboard" EndSection
ServerLayout section:
Identifier — Specifies a unique name for this ServerLayout section.
Screen — Specifies the name of a Screen section to be used with the X server. More than one Screen option may be present.
Screen entry:
Screen 0 "Screen0" 0 0
Screen entry (0) indicates that the first monitor connector, or head on the video card, uses the configuration specified in the Screen section with the identifier "Screen0".
Screen section with the identifier "Screen0" can be found in Раздел C.3.3.8, «The Screen section».
Screen entry with a different number and a different Screen section identifier is necessary.
"Screen0" give the absolute X and Y coordinates for the upper left corner of the screen (0 0 by default).
InputDevice — Specifies the name of an InputDevice section to be used with the X server.
InputDevice entries: one for the default mouse and one for the default keyboard. The options CorePointer and CoreKeyboard indicate that these are the primary mouse and keyboard. If the AutoAddDevices option is enabled, this entry needs not to be specified in the ServerLayout section. If the AutoAddDevices option is disabled, both mouse and keyboard are auto-detected with the default values.
Option "option-name" — An optional entry which specifies extra parameters for the section. Any options listed here override those listed in the ServerFlags section.
<option-name> with a valid option listed for this section in the xorg.conf(5) man page.
ServerLayout section in the /etc/X11/xorg.conf file. By default, the server only reads the first one it encounters, however. If there is an alternative ServerLayout section, it can be specified as a command line argument when starting an X session; as in the Xorg -layout <layoutname> command.
Files sectionFiles section sets paths for services vital to the X server, such as the font path. This is an optional section, as these paths are normally detected automatically. This section can be used to override automatically detected values.
Files section:
Section "Files" RgbPath "/usr/share/X11/rgb.txt" FontPath "unix/:7100" EndSection
Files section:
ModulePath — An optional parameter which specifies alternate directories which store X server modules.
Monitor sectionMonitor section configures one type of monitor used by the system. This is an optional entry as most monitors are now detected automatically.
Monitor section for a monitor:
Section "Monitor" Identifier "Monitor0" VendorName "Monitor Vendor" ModelName "DDC Probed Monitor - ViewSonic G773-2" DisplaySize 320 240 HorizSync 30.0 - 70.0 VertRefresh 50.0 - 180.0 EndSection
Monitor section:
Identifier — Specifies a unique name for this Monitor section. This is a required entry.
VendorName — An optional parameter which specifies the vendor of the monitor.
ModelName — An optional parameter which specifies the monitor's model name.
DisplaySize — An optional parameter which specifies, in millimeters, the physical size of the monitor's picture area.
HorizSync — Specifies the range of horizontal sync frequencies compatible with the monitor, in kHz. These values help the X server determine the validity of built-in or specified Modeline entries for the monitor.
VertRefresh — Specifies the range of vertical refresh frequencies supported by the monitor, in kHz. These values help the X server determine the validity of built-in or specified Modeline entries for the monitor.
Modeline — An optional parameter which specifies additional video modes for the monitor at particular resolutions, with certain horizontal sync and vertical refresh resolutions. Refer to the xorg.conf(5) man page for a more detailed explanation of Modeline entries.
Option "option-name" — An optional entry which specifies extra parameters for the section. Replace <option-name> with a valid option listed for this section in the xorg.conf(5) man page.
Device sectionDevice section configures one video card on the system. While one Device section is the minimum, additional instances may occur for each video card installed on the machine.
Device section for a video card:
Section "Device" Identifier "Videocard0" Driver "mga" VendorName "Videocard vendor" BoardName "Matrox Millennium G200" VideoRam 8192 Option "dpms" EndSection
Device section:
Identifier — Specifies a unique name for this Device section. This is a required entry.
Driver — Specifies which driver the X server must load to utilize the video card. A list of drivers can be found in /usr/share/hwdata/videodrivers, which is installed with the hwdata package.
VendorName — An optional parameter which specifies the vendor of the video card.
BoardName — An optional parameter which specifies the name of the video card.
VideoRam — An optional parameter which specifies the amount of RAM available on the video card, in kilobytes. This setting is only necessary for video cards the X server cannot probe to detect the amount of video RAM.
BusID — An entry which specifies the bus location of the video card. On systems with only one video card a BusID entry is optional and may not even be present in the default /etc/X11/xorg.conf file. On systems with more than one video card, however, a BusID entry is required.
Screen — An optional entry which specifies which monitor connector or head on the video card the Device section configures. This option is only useful for video cards with multiple heads.
Device sections must exist and each of these sections must have a different Screen value.
Screen entry must be an integer. The first head on the video card has a value of 0. The value for each additional head increments this value by one.
Option "option-name" — An optional entry which specifies extra parameters for the section. Replace <option-name> with a valid option listed for this section in the xorg.conf(5) man page.
"dpms" (for Display Power Management Signaling, a VESA standard), which activates the Service Star energy compliance setting for the monitor.
Screen sectionScreen section binds one video card (or video card head) to one monitor by referencing the Device section and the Monitor section for each. While one Screen section is the minimum, additional instances may occur for each video card and monitor combination present on the machine.
Screen section:
Section "Screen"
Identifier "Screen0"
Device "Videocard0"
Monitor "Monitor0"
DefaultDepth 16
SubSection "Display"
Depth 24
Modes "1280x1024" "1280x960" "1152x864" "1024x768" "800x600" "640x480"
EndSubSection
SubSection "Display"
Depth 16
Modes "1152x864" "1024x768" "800x600" "640x480"
EndSubSection
EndSectionScreen section:
Identifier — Specifies a unique name for this Screen section. This is a required entry.
Device — Specifies the unique name of a Device section. This is a required entry.
Monitor — Specifies the unique name of a Monitor section. This is only required if a specific Monitor section is defined in the xorg.conf file. Normally, monitors are detected automatically.
DefaultDepth — Specifies the default color depth in bits. In the previous example, 16 (which provides thousands of colors) is the default. Only one DefaultDepth entry is permitted, although this can be overridden with the Xorg command line option -depth <n>, where <n>SubSection "Display" — Specifies the screen modes available at a particular color depth. The Screen section can have multiple Display subsections, which are entirely optional since screen modes are detected automatically.
Option "option-name" — An optional entry which specifies extra parameters for the section. Replace <option-name> with a valid option listed for this section in the xorg.conf(5) man page.
DRI sectionDRI section specifies parameters for the Direct Rendering Infrastructure (DRI). DRI is an interface which allows 3D software applications to take advantage of 3D hardware acceleration capabilities built into most modern video hardware. In addition, DRI can improve 2D performance via hardware acceleration, if supported by the video card driver.
xorg.conf file will override the default values.
DRI section:
Section "DRI" Group 0 Mode 0666 EndSection
Qt 3 or GTK+ 2 graphical toolkits, or their newer versions.
/etc/fonts/fonts.conf configuration file, which should not be edited by hand.
fonts group installed. This can be done by selecting the group in the installer, and also by running the yum groupinstall fonts command after installation.
.fonts/ directory in the user's home directory.
/usr/share/fonts/ directory. It is a good idea to create a new subdirectory, such as local/ or similar, to help distinguish between user-installed and default fonts.
fc-cache command as root to update the font information cache:
fc-cache <path-to-font-directory><path-to-font-directory> with the directory containing the new fonts (either /usr/share/fonts/local/ or /home/<user>/.fonts/).
fonts:/// into the Nautilus address bar, and dragging the new font files there.
startx. The startx command is a front-end to the xinit command, which launches the X server (Xorg) and connects X client applications to it. Because the user is already logged into the system at runlevel 3, startx does not launch a display manager or authenticate users. Refer to Раздел C.5.2, «Runlevel 5» for more information about display managers.
startx command is executed, it searches for the .xinitrc file in the user's home directory to define the desktop environment and possibly other X client applications to run. If no .xinitrc file is present, it uses the system default /etc/X11/xinit/xinitrc file instead.
xinitrc script then searches for user-defined files and default system files, including .Xresources, .Xmodmap, and .Xkbmap in the user's home directory, and Xresources, Xmodmap, and Xkbmap in the /etc/X11/ directory. The Xmodmap and Xkbmap files, if they exist, are used by the xmodmap utility to configure the keyboard. The Xresources file is read to assign specific preference values to applications.
xinitrc script executes all scripts located in the /etc/X11/xinit/xinitrc.d/ directory. One important script in this directory is xinput.sh, which configures settings such as the default language.
xinitrc script attempts to execute .Xclients in the user's home directory and turns to /etc/X11/xinit/Xclients if it cannot be found. The purpose of the Xclients file is to start the desktop environment or, possibly, just a basic window manager. The .Xclients script in the user's home directory starts the user-specified desktop environment in the .Xclients-default file. If .Xclients does not exist in the user's home directory, the standard /etc/X11/xinit/Xclients script attempts to start another desktop environment, trying GNOME first, then KDE, followed by twm.
GDM (GNOME Display Manager) — The default display manager for Fedora. GNOME allows the user to configure language settings, shutdown, restart or log in to the system.
KDM — KDE's display manager which allows the user to shutdown, restart or log in to the system.
xdm (X Window Display Manager) — A very basic display manager which only lets the user log in to the system.
/etc/X11/prefdm script determines the preferred display manager by referencing the /etc/sysconfig/desktop file. A list of options for this file is available in this file:
/usr/share/doc/initscripts-<version-number>/sysconfig.txt<version-number> is the version number of the initscripts package.
/etc/X11/xdm/Xsetup_0 file to set up the login screen. Once the user logs into the system, the /etc/X11/xdm/GiveConsole script runs to assign ownership of the console to the user. Then, the /etc/X11/xdm/Xsession script runs to accomplish many of the tasks normally performed by the xinitrc script when starting X from runlevel 3, including setting system and user resources, as well as running the scripts in the /etc/X11/xinit/xinitrc.d/ directory.
GNOME or KDE display managers by selecting it from the menu item accessed by selecting → → → . If the desktop environment is not specified in the display manager, the /etc/X11/xdm/Xsession script checks the .xsession and .Xclients files in the user's home directory to decide which desktop environment to load. As a last resort, the /etc/X11/xinit/Xclients file is used to select a desktop environment or window manager to use in the same way as runlevel 3.
:0) and logs out, the /etc/X11/xdm/TakeConsole script runs and reassigns ownership of the console to the root user. The original display manager, which continues running after the user logged in, takes control by spawning a new display manager. This restarts the X server, displays a new login window, and starts the entire process over again.
/usr/share/doc/gdm-<version-number>/README , where <version-number> is the version number for the gdm package installed, or the xdm man page.
/usr/share/X11/doc/ — contains detailed documentation on the X Window System architecture, as well as how to get additional information about the Xorg project as a new user.
/usr/share/doc/gdm-<version-number>/README — contains information on how display managers control user authentication.
man xorg.conf — Contains information about the xorg.conf configuration files, including the meaning and syntax for the different sections within the files.
man Xorg — Describes the Xorg display server.
/etc/sysconfig/ directory, their function, and their contents. The information in this appendix is not intended to be complete, as many of these files have a variety of options that are only used in very specific or rare circumstances.
/etc/sysconfig/ directory depends on the programs you have installed on your machine. To find the name of the package the configuration file belongs to, type the following at a shell prompt:
~]$ yum provides /etc/sysconfig/filename
/etc/sysconfig/ directory.
/etc/sysconfig/arpwatch file is used to pass arguments to the arpwatch daemon at boot time. By default, it contains the following option:
OPTIONS=value arpwatch daemon. For example:
OPTIONS="-u arpwatch -e root -s 'root (Arpwatch)'"
/etc/sysconfig/authconfig file sets the authorization to be used on the host. By default, it contains the following options:
USEMKHOMEDIR=boolean yes) or disable (no) creating a home directory for a user on the first login. For example:
USEMKHOMEDIR=no
USEPAMACCESS=boolean yes) or disable (no) the PAM authentication. For example:
USEPAMACCESS=no
USESSSDAUTH=boolean yes) or disable (no) the SSSD authentication. For example:
USESSSDAUTH=no
USESHADOW=boolean yes) or disable (no) shadow passwords. For example:
USESHADOW=yes
USEWINBIND=boolean yes) or disable (no) using Winbind for user account configuration. For example:
USEWINBIND=no
USEDB=boolean yes) or disable (no) the FAS authentication. For example:
USEDB=no
USEFPRINTD=boolean yes) or disable (no) the fingerprint authentication. For example:
USEFPRINTD=yes
FORCESMARTCARD=boolean yes) or disable (no) enforcing the smart card authentication. For example:
FORCESMARTCARD=no
PASSWDALGORITHM=value value can be bigcrypt, descrypt, md5, sha256, or sha512. For example:
PASSWDALGORITHM=sha512
USELDAPAUTH=boolean yes) or disable (no) the LDAP authentication. For example:
USELDAPAUTH=no
USELOCAUTHORIZE=boolean yes) or disable (no) the local authorization for local users. For example:
USELOCAUTHORIZE=yes
USECRACKLIB=boolean yes) or disable (no) using the CrackLib. For example:
USECRACKLIB=yes
USEWINBINDAUTH=boolean yes) or disable (no) the Winbind authentication. For example:
USEWINBINDAUTH=no
USESMARTCARD=boolean yes) or disable (no) the smart card authentication. For example:
USESMARTCARD=no
USELDAP=boolean yes) or disable (no) using LDAP for user account configuration. For example:
USELDAP=no
USENIS=boolean yes) or disable (no) using NIS for user account configuration. For example:
USENIS=no
USEKERBEROS=boolean yes) or disable (no) the Kerberos authentication. For example:
USEKERBEROS=no
USESYSNETAUTH=boolean yes) or disable (no) authenticating system accounts with network services. For example:
USESYSNETAUTH=no
USESMBAUTH=boolean yes) or disable (no) the SMB authentication. For example:
USESMBAUTH=no
USESSSD=boolean yes) or disable (no) using SSSD for obtaining user information. For example:
USESSSD=no
USEHESIOD=boolean yes) or disable (no) using the Hesoid name service. For example:
USEHESIOD=no
/etc/sysconfig/autofs file defines custom options for the automatic mounting of devices. This file controls the operation of the automount daemons, which automatically mount file systems when you use them and unmount them after a period of inactivity. File systems can include network file systems, CD-ROM drives, diskettes, and other media.
MASTER_MAP_NAME=value MASTER_MAP_NAME="auto.master"
TIMEOUT=value TIMEOUT=300
NEGATIVE_TIMEOUT=value NEGATIVE_TIMEOUT=60
MOUNT_WAIT=value mount. For example:
MOUNT_WAIT=-1
UMOUNT_WAIT=value umount. For example:
UMOUNT_WAIT=12
BROWSE_MODE=boolean yes) or disable (no) browsing the maps. For example:
BROWSE_MODE="no"
MOUNT_NFS_DEFAULT_PROTOCOL=value mount.nfs. For example:
MOUNT_NFS_DEFAULT_PROTOCOL=4
APPEND_OPTIONS=boolean yes) or disable (no) appending the global options instead of replacing them. For example:
APPEND_OPTIONS="yes"
LOGGING=value value has to be either none, verbose, or debug. For example:
LOGGING="none"
LDAP_URI=value protocol://server LDAP_URI="ldaps://ldap.example.com/"
LDAP_TIMEOUT=value LDAP_TIMEOUT=-1
LDAP_NETWORK_TIMEOUT=value LDAP_NETWORK_TIMEOUT=8
SEARCH_BASE=value SEARCH_BASE=""
AUTH_CONF_FILE=value AUTH_CONF_FILE="/etc/autofs_ldap_auth.conf"
MAP_HASH_TABLE_SIZE=value MAP_HASH_TABLE_SIZE=1024
USE_MISC_DEVICE=boolean yes) or disable (no) using the autofs miscellaneous device. For example:
USE_MISC_DEVICE="yes"
OPTIONS=value OPTIONS=""
/etc/sysconfig/clock file controls the interpretation of values read from the system hardware clock. It is used by the Date and Time configuration tool, and should not be edited by hand. By default, it contains the following option:
ZONE=value /usr/share/zoneinfo that /etc/localtime is a copy of. For example:
ZONE="Europe/Prague"
/etc/sysconfig/dhcpd file is used to pass arguments to the dhcpd daemon at boot time. By default, it contains the following options:
DHCPDARGS=value dhcpd daemon. For example:
DHCPDARGS=
/etc/sysconfig/firstboot file defines whether to run the firstboot utility. By default, it contains the following option:
RUN_FIRSTBOOT=boolean YES) or disable (NO) running the firstboot program. For example:
RUN_FIRSTBOOT=NO
init program calls the /etc/rc.d/init.d/firstboot script, which looks for the /etc/sysconfig/firstboot file. If this file does not contain the RUN_FIRSTBOOT=NO option, the firstboot program is run, guiding a user through the initial configuration of the system.
firstboot program the next time the system boots, change the value of RUN_FIRSTBOOT option to YES, and type the following at a shell prompt as root:
~]# systemctl enable firstboot.service
/etc/sysconfig/i18n configuration file defines the default language, any supported languages, and the default system font. By default, it contains the following options:
LANG=value LANG="en_US.UTF-8"
SUPPORTED=value SUPPORTED="en_US.UTF-8:en_US:en"
SYSFONT=value SYSFONT="latarcyrheb-sun16"
/etc/sysconfig/init file controls how the system appears and functions during the boot process. By default, it contains the following options:
BOOTUP=value color (the standard color boot display), verbose (an old style display which provides more information), or anything else for the new style display, but without ANSI formatting. For example:
BOOTUP=color
RES_COL=value RES_COL=60
MOVE_TO_COL=value RES_COL (see above). For example:
MOVE_TO_COL="echo -en \\033[${RES_COL}G"SETCOLOR_SUCCESS=value SETCOLOR_SUCCESS="echo -en \\033[0;32m"
SETCOLOR_FAILURE=value SETCOLOR_FAILURE="echo -en \\033[0;31m"
SETCOLOR_WARNING=value SETCOLOR_WARNING="echo -en \\033[0;33m"
SETCOLOR_NORMAL=value SETCOLOR_NORMAL="echo -en \\033[0;39m"
LOGLEVEL=value value has to be in the range from 1 (kernel panics only) to 8 (everything, including the debugging information). For example:
LOGLEVEL=3
PROMPT=boolean yes) or disable (no) the hotkey interactive startup. For example:
PROMPT=yes
AUTOSWAP=boolean yes) or disable (no) probing for devices with swap signatures. For example:
AUTOSWAP=no
ACTIVE_CONSOLES=value ACTIVE_CONSOLES=/dev/tty[1-6]
SINGLE=value value has to be either /sbin/sulogin (a user will be prompted for a password to log in), or /sbin/sushell (the user will be logged in directly). For example:
SINGLE=/sbin/sushell
/etc/sysconfig/ip6tables-config file stores information used by the kernel to set up IPv6 packet filtering at boot time or whenever the ip6tables service is started. Note that you should not modify it unless you are familiar with ip6tables rules. By default, it contains the following options:
IP6TABLES_MODULES=value IP6TABLES_MODULES="ip_nat_ftp ip_nat_irc"
IP6TABLES_MODULES_UNLOAD=boolean yes) or disable (no) module unloading when the firewall is stopped or restarted. For example:
IP6TABLES_MODULES_UNLOAD="yes"
IP6TABLES_SAVE_ON_STOP=boolean yes) or disable (no) saving the current firewall rules when the firewall is stopped. For example:
IP6TABLES_SAVE_ON_STOP="no"
IP6TABLES_SAVE_ON_RESTART=boolean yes) or disable (no) saving the current firewall rules when the firewall is restarted. For example:
IP6TABLES_SAVE_ON_RESTART="no"
IP6TABLES_SAVE_COUNTER=boolean yes) or disable (no) saving the rule and chain counters. For example:
IP6TABLES_SAVE_COUNTER="no"
IP6TABLES_STATUS_NUMERIC=boolean yes) or disable (no) printing IP addresses and port numbers in a numeric format in the status output. For example:
IP6TABLES_STATUS_NUMERIC="yes"
IP6TABLES_STATUS_VERBOSE=boolean yes) or disable (no) printing information about the number of packets and bytes in the status output. For example:
IP6TABLES_STATUS_VERBOSE="no"
IP6TABLES_STATUS_LINENUMBERS=boolean yes) or disable (no) printing line numbers in the status output. For example:
IP6TABLES_STATUS_LINENUMBERS="yes"
ip6tables command. Once created, type the following at a shell prompt:
~]# service ip6tables save
/etc/sysconfig/ip6tables. Once this file exists, any firewall rules saved in it persist through a system reboot or a service restart.
/etc/sysconfig/keyboard file controls the behavior of the keyboard. By default, it contains the following options:
KEYTABLE=value /lib/kbd/keymaps/i386/ directory, and branch into different keyboard layouts from there, all labeled value.kmap.gzKEYTABLE setting is used. For example:
KEYTABLE="us"
MODEL=value MODEL="pc105+inet"
LAYOUT=value LAYOUT="us"
KEYBOARDTYPE=value pc (a PS/2 keyboard), or sun (a Sun keyboard). For example:
KEYBOARDTYPE="pc"
/etc/sysconfig/ldap file holds the basic configuration for the LDAP server. By default, it contains the following options:
SLAPD_OPTIONS=value slapd daemon. For example:
SLAPD_OPTIONS="-4"
SLURPD_OPTIONS=value slurpd daemon. For example:
SLURPD_OPTIONS=""
SLAPD_LDAP=boolean yes) or disable (no) using the LDAP over TCP (that is, ldap:///). For example:
SLAPD_LDAP="yes"
SLAPD_LDAPI=boolean yes) or disable (no) using the LDAP over IPC (that is, ldapi:///). For example:
SLAPD_LDAPI="no"
SLAPD_LDAPS=boolean yes) or disable (no) using the LDAP over TLS (that is, ldaps:///). For example:
SLAPD_LDAPS="no"
SLAPD_URLS=value SLAPD_URLS="ldapi:///var/lib/ldap_root/ldapi ldapi:/// ldaps:///"
SLAPD_SHUTDOWN_TIMEOUT=value slapd to shut down. For example:
SLAPD_SHUTDOWN_TIMEOUT=3
SLAPD_ULIMIT_SETTINGS=value ulimit before the slapd daemon is started. For example:
SLAPD_ULIMIT_SETTINGS=""
/etc/sysconfig/named file is used to pass arguments to the named daemon at boot time. By default, it contains the following options:
ROOTDIR=value named daemon runs. The value has to be a full directory path. For example:
ROOTDIR="/var/named/chroot"
info chroot at a shell prompt for more information).
OPTIONS=value named. For example:
OPTIONS="-6"
-t option. Instead, use ROOTDIR as described above.
KEYTAB_FILE=value KEYTAB_FILE="/etc/named.keytab"
/etc/sysconfig/network file is used to specify information about the desired network configuration. By default, it contains the following options:
NETWORKING=boolean yes) or disable (no) the networking. For example:
NETWORKING=yes
HOSTNAME=value HOSTNAME=penguin.example.com
GATEWAY=value GATEWAY=192.168.1.0
/etc/sysconfig/ntpd file is used to pass arguments to the ntpd daemon at boot time. By default, it contains the following option:
OPTIONS=value ntpd. For example:
OPTIONS="-u ntp:ntp -p /var/run/ntpd.pid -g"
ntpd daemon.
/etc/sysconfig/quagga file holds the basic configuration for Quagga daemons. By default, it contains the following options:
QCONFDIR=value QCONFDIR="/etc/quagga"
BGPD_OPTS=value bgpd daemon. For example:
BGPD_OPTS="-A 127.0.0.1 -f ${QCONFDIR}/bgpd.conf"OSPF6D_OPTS=value ospf6d daemon. For example:
OSPF6D_OPTS="-A ::1 -f ${QCONFDIR}/ospf6d.conf"OSPFD_OPTS=value ospfd daemon. For example:
OSPFD_OPTS="-A 127.0.0.1 -f ${QCONFDIR}/ospfd.conf"RIPD_OPTS=value ripd daemon. For example:
RIPD_OPTS="-A 127.0.0.1 -f ${QCONFDIR}/ripd.conf"RIPNGD_OPTS=value ripngd daemon. For example:
RIPNGD_OPTS="-A ::1 -f ${QCONFDIR}/ripngd.conf"ZEBRA_OPTS=value zebra daemon. For example:
ZEBRA_OPTS="-A 127.0.0.1 -f ${QCONFDIR}/zebra.conf"ISISD_OPTS=value isisd daemon. For example:
ISISD_OPTS="-A ::1 -f ${QCONFDIR}/isisd.conf"WATCH_OPTS=value watchquagga daemon. For example:
WATCH_OPTS="-Az -b_ -r/sbin/service_%s_restart -s/sbin/service_%s_start -k/sbin/service_%s_stop"
WATCH_DAEMONS=value WATCH_DAEMONS="zebra bgpd ospfd ospf6d ripd ripngd"
/etc/sysconfig/radvd file is used to pass arguments to the radvd daemon at boot time. By default, it contains the following option:
OPTIONS=value radvd daemon. For example:
OPTIONS="-u radvd"
/etc/sysconfig/samba file is used to pass arguments to the Samba daemons at boot time. By default, it contains the following options:
SMBDOPTIONS=value smbd. For example:
SMBDOPTIONS="-D"
NMBDOPTIONS=value nmbd. For example:
NMBDOPTIONS="-D"
WINBINDOPTIONS=value winbindd. For example:
WINBINDOPTIONS=""
/etc/sysconfig/selinux file contains the basic configuration options for SELinux. It is a symbolic link to /etc/selinux/config, and by default, it contains the following options:
SELINUX=value value can be either enforcing (the security policy is always enforced), permissive (instead of enforcing the policy, appropriate warnings are displayed), or disabled (no policy is used). For example:
SELINUX=enforcing
SELINUXTYPE=value value can be either targeted (the targeted processes are protected), or mls (the Multi Level Security protection). For example:
SELINUXTYPE=targeted
/etc/sysconfig/sendmail is used to set the default values for the Sendmail application. By default, it contains the following values:
DAEMON=boolean yes) or disable (no) running sendmail as a daemon. For example:
DAEMON=yes
QUEUE=value QUEUE=1h
/etc/sysconfig/spamassassin file is used to pass arguments to the spamd daemon (a daemonized version of Spamassassin) at boot time. By default, it contains the following option:
SPAMDOPTIONS=value spamd daemon. For example:
SPAMDOPTIONS="-d -c -m5 -H"
/etc/sysconfig/squid file is used to pass arguments to the squid daemon at boot time. By default, it contains the following options:
SQUID_OPTS=value squid daemon. For example:
SQUID_OPTS=""
SQUID_SHUTDOWN_TIMEOUT=value squid daemon to shut down. For example:
SQUID_SHUTDOWN_TIMEOUT=100
SQUID_CONF=value SQUID_CONF="/etc/squid/squid.conf"
/etc/sysconfig/system-config-users file is the configuration file for the User Manager utility, and should not be edited by hand. By default, it contains the following options:
FILTER=boolean true) or disable (false) filtering of system users. For example:
FILTER=true
ASSIGN_HIGHEST_UID=boolean true) or disable (false) assigning the highest available UID to newly added users. For example:
ASSIGN_HIGHEST_UID=true
ASSIGN_HIGHEST_GID=boolean true) or disable (false) assigning the highest available GID to newly added groups. For example:
ASSIGN_HIGHEST_GID=true
PREFER_SAME_UID_GID=boolean true) or disable (false) using the same UID and GID for newly added users when possible. For example:
PREFER_SAME_UID_GID=true
/etc/sysconfig/vncservers file configures the way the Virtual Network Computing (VNC) server starts up. By default, it contains the following options:
VNCSERVERS=value display:username VNCSERVERS="2:myusername"
VNCSERVERARGS[display]=value display. For example:
VNCSERVERARGS[2]="-geometry 800x600 -nolisten tcp -localhost"
/etc/sysconfig/xinetd file is used to pass arguments to the xinetd daemon at boot time. By default, it contains the following options:
EXTRAOPTIONS=value xinetd. For example:
EXTRAOPTIONS=""
XINETD_LANG=value xinetd. Note that to remove locale information from the xinetd environment, you can use an empty string ("") or none. For example:
XINETD_LANG="en_US"
xinetd services.
/etc/sysconfig/.
/etc/sysconfig/cbq/ /etc/sysconfig/networking/ /etc/sysconfig/network-scripts/ ifcfg-eth0 for the eth0 Ethernet interface.
ifup and ifdown.
ifup-isdn and ifdown-isdn.
/etc/sysconfig/network-scripts/ directory, refer to Глава 7, Сетевые интерфейсы.
/proc/ directory (also called the proc file system) contains a hierarchy of special files which represent the current state of the kernel, allowing applications and users to peer into the kernel's view of the system.
/proc/ directory contains a wealth of information detailing system hardware and any running processes. In addition, some of the files within /proc/ can be manipulated by users and applications to communicate configuration changes to the kernel.
/proc/ide/ and /proc/pci/ directories obsolete. The /proc/ide/ file system is now superseded by files in sysfs; to retrieve information on PCI devices, use lspci instead. For more information on sysfs or lspci, refer to their respective man pages.
/proc/ directory contains another type of file called a virtual file. As such, /proc/ is often referred to as a virtual file system.
/proc/interrupts, /proc/meminfo, /proc/mounts, and /proc/partitions provide an up-to-the-moment glimpse of the system's hardware. Others, like the /proc/filesystems file and the /proc/sys/ directory provide system configuration information and interfaces.
WAS:: For organizational purposes, files containing information on a similar topic are grouped into virtual directories and sub-directories. For instance, /proc/ide/ contains information for all physical IDE devices. Likewise, process directories contain information about each running process on the system.
/proc/ files operate similarly to text files, storing useful system and hardware data in human-readable text format. As such, you can use cat, more, or less to view them. For example, to display information about the system's CPU, run cat /proc/cpuinfo. This will return output similar to the following:
processor : 0 vendor_id : AuthenticAMD cpu family : 5 model : 9 model name : AMD-K6(tm) 3D+ Processor stepping : 1 cpu MHz : 400.919 cache size : 256 KB fdiv_bug : no hlt_bug : no f00f_bug : no coma_bug : no fpu : yes fpu_exception : yes cpuid level : 1 wp : yes flags : fpu vme de pse tsc msr mce cx8 pge mmx syscall 3dnow k6_mtrr bogomips : 799.53
/proc/ contain information that is not human-readable. To retrieve information from such files, use tools such as lspci, apm, free, and top.
/proc/ directory are readable only by the root user.
/proc/ directory are read-only. However, some can be used to adjust settings in the kernel. This is especially true for files in the /proc/sys/ subdirectory.
echo value > /proc/file
echo www.example.com > /proc/sys/kernel/hostname
cat /proc/sys/net/ipv4/ip_forward returns either a 0 (off or false) or a 1 (on or true). A 0 indicates that the kernel is not forwarding network packets. To turn packet forwarding on, run echo 1 > /proc/sys/net/ipv4/ip_forward.
/proc/sys/ subdirectory is /sbin/sysctl. For more information on this command, refer to Раздел E.4, «Using the sysctl Command»
/proc/sys/ subdirectory, refer to Раздел E.3.9, « /proc/sys/ ».
proc File System/proc/ directory.
DMA row references the first 16 MB on a system, the HighMem row references all memory greater than 4 GB on a system, and the Normal row references all memory in between.
/proc/buddyinfo:
Node 0, zone DMA 90 6 2 1 1 ... Node 0, zone Normal 1650 310 5 0 0 ... Node 0, zone HighMem 2 0 0 1 1 ...
/proc/cmdline file looks like the following:
ro root=/dev/VolGroup00/LogVol00 rhgb quiet 3
(ro)), located on the first logical volume (LogVol00) of the first volume group (/dev/VolGroup00). LogVol00 is the equivalent of a disk partition in a non-LVM system (Logical Volume Management), just as /dev/VolGroup00 is similar in concept to /dev/hda1, but much more extensible.
rhgb signals that the rhgb package has been installed, and graphical booting is supported, assuming /etc/inittab shows a default runlevel set to id:5:initdefault:.
quiet indicates all verbose kernel messages are suppressed at boot time.
/proc/cpuinfo:
processor : 0 vendor_id : GenuineIntel cpu family : 15 model : 2 model name : Intel(R) Xeon(TM) CPU 2.40GHz stepping : 7 cpu MHz : 2392.371 cache size : 512 KB physical id : 0 siblings : 2 runqueue : 0 fdiv_bug : no hlt_bug : no f00f_bug : no coma_bug : no fpu : yes fpu_exception : yes cpuid level : 2 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm bogomips : 4771.02
processor — Provides each processor with an identifying number. On systems that have one processor, only a 0 is present.
cpu family — Authoritatively identifies the type of processor in the system. For an Intel-based system, place the number in front of "86" to determine the value. This is particularly helpful for those attempting to identify the architecture of an older system such as a 586, 486, or 386. Because some RPM packages are compiled for each of these particular architectures, this value also helps users determine which packages to install.
model name — Displays the common name of the processor, including its project name.
cpu MHz — Shows the precise speed in megahertz for the processor to the thousandths decimal place.
cache size — Displays the amount of level 2 memory cache available to the processor.
siblings — Displays the number of sibling CPUs on the same physical CPU for architectures which use hyper-threading.
flags — Defines a number of different qualities about the processor, such as the presence of a floating point unit (FPU) and the ability to process MMX instructions.
/proc/crypto file looks like the following:
name : sha1 module : kernel type : digest blocksize : 64 digestsize : 20 name : md5 module : md5 type : digest blocksize : 64 digestsize : 16
Character devices: 1 mem 4 /dev/vc/0 4 tty 4 ttyS 5 /dev/tty 5 /dev/console 5 /dev/ptmx 7 vcs 10 misc 13 input 29 fb 36 netlink 128 ptm 136 pts 180 usb Block devices: 1 ramdisk 3 ide0 9 md 22 ide1 253 device-mapper 254 mdp
/proc/devices includes the major number and name of the device, and is broken into two major sections: Character devices and Block devices.
/usr/share/doc/kernel-doc-<kernel_version>/Documentation/devices.txt/proc/dma files looks like the following:
4: cascade
0-0 Linux [kernel]
PER_LINUX execution domain, different personalities can be implemented as dynamically loadable modules.
/proc/fb for systems which contain frame buffer devices looks similar to the following:
0 VESA VGA
/proc/filesystems file looks similar to the following:
nodev sysfs nodev rootfs nodev bdev nodev proc nodev sockfs nodev binfmt_misc nodev usbfs nodev usbdevfs nodev futexfs nodev tmpfs nodev pipefs nodev eventpollfs nodev devpts ext2 nodev ramfs nodev hugetlbfs iso9660 nodev mqueue ext3 nodev rpc_pipefs nodev autofs
nodev are not mounted on a device. The second column lists the names of the file systems supported.
mount command cycles through the file systems listed here when one is not specified as an argument.
/proc/interrupts looks similar to the following:
CPU0 0: 80448940 XT-PIC timer 1: 174412 XT-PIC keyboard 2: 0 XT-PIC cascade 8: 1 XT-PIC rtc 10: 410964 XT-PIC eth0 12: 60330 XT-PIC PS/2 Mouse 14: 1314121 XT-PIC ide0 15: 5195422 XT-PIC ide1 NMI: 0 ERR: 0
CPU0 CPU1 0: 1366814704 0 XT-PIC timer 1: 128 340 IO-APIC-edge keyboard 2: 0 0 XT-PIC cascade 8: 0 1 IO-APIC-edge rtc 12: 5323 5793 IO-APIC-edge PS/2 Mouse 13: 1 0 XT-PIC fpu 16: 11184294 15940594 IO-APIC-level Intel EtherExpress Pro 10/100 Ethernet 20: 8450043 11120093 IO-APIC-level megaraid 30: 10432 10722 IO-APIC-level aic7xxx 31: 23 22 IO-APIC-level aic7xxx NMI: 0 ERR: 0
XT-PIC — This is the old AT computer interrupts.
IO-APIC-edge — The voltage signal on this interrupt transitions from low to high, creating an edge, where the interrupt occurs and is only signaled once. This kind of interrupt, as well as the IO-APIC-level interrupt, are only seen on systems with processors from the 586 family and higher.
IO-APIC-level — Generates interrupts when its voltage signal is high until the signal is low again.
00000000-0009fbff : System RAM 0009fc00-0009ffff : reserved 000a0000-000bffff : Video RAM area 000c0000-000c7fff : Video ROM 000f0000-000fffff : System ROM 00100000-07ffffff : System RAM 00100000-00291ba8 : Kernel code 00291ba9-002e09cb : Kernel data e0000000-e3ffffff : VIA Technologies, Inc. VT82C597 [Apollo VP3] e4000000-e7ffffff : PCI Bus #01 e4000000-e4003fff : Matrox Graphics, Inc. MGA G200 AGP e5000000-e57fffff : Matrox Graphics, Inc. MGA G200 AGP e8000000-e8ffffff : PCI Bus #01 e8000000-e8ffffff : Matrox Graphics, Inc. MGA G200 AGP ea000000-ea00007f : Digital Equipment Corporation DECchip 21140 [FasterNet] ea000000-ea00007f : tulip ffff0000-ffffffff : reserved
/proc/ioports provides a list of currently registered port regions used for input or output communication with a device. This file can be quite long. The following is a partial listing:
0000-001f : dma1 0020-003f : pic1 0040-005f : timer 0060-006f : keyboard 0070-007f : rtc 0080-008f : dma page reg 00a0-00bf : pic2 00c0-00df : dma2 00f0-00ff : fpu 0170-0177 : ide1 01f0-01f7 : ide0 02f8-02ff : serial(auto) 0376-0376 : ide1 03c0-03df : vga+ 03f6-03f6 : ide0 03f8-03ff : serial(auto) 0cf8-0cff : PCI conf1 d000-dfff : PCI Bus #01 e000-e00f : VIA Technologies, Inc. Bus Master IDE e000-e007 : ide0 e008-e00f : ide1 e800-e87f : Digital Equipment Corporation DECchip 21140 [FasterNet] e800-e87f : tulip
/proc/ files, kcore displays a size. This value is given in bytes and is equal to the size of the physical memory (RAM) used plus 4 KB.
gdb, and is not human readable.
/proc/kcore virtual file. The contents of the file scramble text output on the terminal. If this file is accidentally viewed, press Ctrl+C to stop the process and then type reset to bring back the command line prompt.
/sbin/klogd or /bin/dmesg.
uptime and other commands. A sample /proc/loadavg file looks similar to the following:
0.20 0.18 0.12 1/80 11206
/proc/locks file for a lightly loaded system looks similar to the following:
1: POSIX ADVISORY WRITE 3568 fd:00:2531452 0 EOF 2: FLOCK ADVISORY WRITE 3517 fd:00:2531448 0 EOF 3: POSIX ADVISORY WRITE 3452 fd:00:2531442 0 EOF 4: POSIX ADVISORY WRITE 3443 fd:00:2531440 0 EOF 5: POSIX ADVISORY WRITE 3326 fd:00:2531430 0 EOF 6: POSIX ADVISORY WRITE 3175 fd:00:2531425 0 EOF 7: POSIX ADVISORY WRITE 3056 fd:00:2548663 0 EOF
FLOCK signifying the older-style UNIX file locks from a flock system call and POSIX representing the newer POSIX locks from the lockf system call.
ADVISORY or MANDATORY. ADVISORY means that the lock does not prevent other people from accessing the data; it only prevents other attempts to lock it. MANDATORY means that no other access to the data is permitted while the lock is held. The fourth column reveals whether the lock is allowing the holder READ or WRITE access to the file. The fifth column shows the ID of the process holding the lock. The sixth column shows the ID of the file being locked, in the format of MAJOR-DEVICE:MINOR-DEVICE:INODE-NUMBER /proc/mdstat looks similar to the following:
Personalities : read_ahead not set unused devices: <none>
md device is present. In that case, view /proc/mdstat to find the current status of mdX RAID devices.
/proc/mdstat file below shows a system with its md0 configured as a RAID 1 device, while it is currently re-syncing the disks:
Personalities : [linear] [raid1] read_ahead 1024 sectors md0: active raid1 sda2[1] sdb2[0] 9940 blocks [2/2] [UU] resync=1% finish=12.3min algorithm 2 [3/3] [UUU] unused devices: <none>
/proc/ directory, as it reports a large amount of valuable information about the systems RAM usage.
/proc/meminfo virtual file is from a system with 256 MB of RAM and 512 MB of swap space:
MemTotal: 255908 kB MemFree: 69936 kB Buffers: 15812 kB Cached: 115124 kB SwapCached: 0 kB Active: 92700 kB Inactive: 63792 kB HighTotal: 0 kB HighFree: 0 kB LowTotal: 255908 kB LowFree: 69936 kB SwapTotal: 524280 kB SwapFree: 524280 kB Dirty: 4 kB Writeback: 0 kB Mapped: 42236 kB Slab: 25912 kB Committed_AS: 118680 kB PageTables: 1236 kB VmallocTotal: 3874808 kB VmallocUsed: 1416 kB VmallocChunk: 3872908 kB HugePages_Total: 0 HugePages_Free: 0 Hugepagesize: 4096 kB
free, top, and ps commands. In fact, the output of the free command is similar in appearance to the contents and structure of /proc/meminfo. But by looking directly at /proc/meminfo, more details are revealed:
MemTotal — Total amount of physical RAM, in kilobytes.
MemFree — The amount of physical RAM, in kilobytes, left unused by the system.
Buffers — The amount of physical RAM, in kilobytes, used for file buffers.
Cached — The amount of physical RAM, in kilobytes, used as cache memory.
SwapCached — The amount of swap, in kilobytes, used as cache memory.
Active — The total amount of buffer or page cache memory, in kilobytes, that is in active use. This is memory that has been recently used and is usually not reclaimed for other purposes.
Inactive — The total amount of buffer or page cache memory, in kilobytes, that are free and available. This is memory that has not been recently used and can be reclaimed for other purposes.
HighTotal and HighFree — The total and free amount of memory, in kilobytes, that is not directly mapped into kernel space. The HighTotal value can vary based on the type of kernel used.
LowTotal and LowFree — The total and free amount of memory, in kilobytes, that is directly mapped into kernel space. The LowTotal value can vary based on the type of kernel used.
SwapTotal — The total amount of swap available, in kilobytes.
SwapFree — The total amount of swap free, in kilobytes.
Dirty — The total amount of memory, in kilobytes, waiting to be written back to the disk.
Writeback — The total amount of memory, in kilobytes, actively being written back to the disk.
Mapped — The total amount of memory, in kilobytes, which have been used to map devices, files, or libraries using the mmap command.
Slab — The total amount of memory, in kilobytes, used by the kernel to cache data structures for its own use.
Committed_AS — The total amount of memory, in kilobytes, estimated to complete the workload. This value represents the worst case scenario value, and also includes swap memory.
PageTables — The total amount of memory, in kilobytes, dedicated to the lowest page table level.
VMallocTotal — The total amount of memory, in kilobytes, of total allocated virtual address space.
VMallocUsed — The total amount of memory, in kilobytes, of used virtual address space.
VMallocChunk — The largest contiguous block of memory, in kilobytes, of available virtual address space.
HugePages_Total — The total number of hugepages for the system. The number is derived by dividing Hugepagesize by the megabytes set aside for hugepages specified in /proc/sys/vm/hugetlb_pool. This statistic only appears on the x86, Itanium, and AMD64 architectures.
HugePages_Free — The total number of hugepages available for the system. This statistic only appears on the x86, Itanium, and AMD64 architectures.
Hugepagesize — The size for each hugepages unit in kilobytes. By default, the value is 4096 KB on uniprocessor kernels for 32 bit architectures. For SMP, hugemem kernels, and AMD64, the default is 2048 KB. For Itanium architectures, the default is 262144 KB. This statistic only appears on the x86, Itanium, and AMD64 architectures.
63 device-mapper 175 agpgart 135 rtc 134 apm_bios
/proc/modules file output:
/sbin/lsmod command.
nfs 170109 0 - Live 0x129b0000 lockd 51593 1 nfs, Live 0x128b0000 nls_utf8 1729 0 - Live 0x12830000 vfat 12097 0 - Live 0x12823000 fat 38881 1 vfat, Live 0x1287b000 autofs4 20293 2 - Live 0x1284f000 sunrpc 140453 3 nfs,lockd, Live 0x12954000 3c59x 33257 0 - Live 0x12871000 uhci_hcd 28377 0 - Live 0x12869000 md5 3777 1 - Live 0x1282c000 ipv6 211845 16 - Live 0x128de000 ext3 92585 2 - Live 0x12886000 jbd 65625 1 ext3, Live 0x12857000 dm_mod 46677 3 - Live 0x12833000
Live, Loading, or Unloading are the only possible values.
oprofile.
rootfs / rootfs rw 0 0 /proc /proc proc rw,nodiratime 0 0 none /dev ramfs rw 0 0 /dev/mapper/VolGroup00-LogVol00 / ext3 rw 0 0 none /dev ramfs rw 0 0 /proc /proc proc rw,nodiratime 0 0 /sys /sys sysfs rw 0 0 none /dev/pts devpts rw 0 0 usbdevfs /proc/bus/usb usbdevfs rw 0 0 /dev/hda1 /boot ext3 rw 0 0 none /dev/shm tmpfs rw 0 0 none /proc/sys/fs/binfmt_misc binfmt_misc rw 0 0 sunrpc /var/lib/nfs/rpc_pipefs rpc_pipefs rw 0 0
/etc/mtab, except that /proc/mounts is more up-to-date.
ro) or read-write (rw). The fifth and sixth columns are dummy values designed to match the format used in /etc/mtab.
/proc/mtrr file may look similar to the following:
reg00: base=0x00000000 ( 0MB), size= 256MB: write-back, count=1 reg01: base=0xe8000000 (3712MB), size= 32MB: write-combining, count=1
/proc/mtrr file can increase performance more than 150%.
/usr/share/doc/kernel-doc-<kernel_version>/Documentation/<arch>/mtrr.txt
major minor #blocks name 3 0 19531250 hda 3 1 104391 hda1 3 2 19422585 hda2 253 0 22708224 dm-0 253 1 524288 dm-1
major — The major number of the device with this partition. The major number in the /proc/partitions, (3), corresponds with the block device ide0, in /proc/devices.
minor — The minor number of the device with this partition. This serves to separate the partitions into different physical devices and relates to the number at the end of the name of the partition.
#blocks — Lists the number of physical disk blocks contained in a particular partition.
name — The name of the partition.
/proc/slabinfo file manually, the /usr/bin/slabtop program displays kernel slab cache information in real time. This program allows for custom configurations, including column sorting and screen refreshing.
/usr/bin/slabtop usually looks like the following example:
Active / Total Objects (% used) : 133629 / 147300 (90.7%) Active / Total Slabs (% used) : 11492 / 11493 (100.0%) Active / Total Caches (% used) : 77 / 121 (63.6%) Active / Total Size (% used) : 41739.83K / 44081.89K (94.7%) Minimum / Average / Maximum Object : 0.01K / 0.30K / 128.00K OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME 44814 43159 96% 0.62K 7469 6 29876K ext3_inode_cache 36900 34614 93% 0.05K 492 75 1968K buffer_head 35213 33124 94% 0.16K 1531 23 6124K dentry_cache 7364 6463 87% 0.27K 526 14 2104K radix_tree_node 2585 1781 68% 0.08K 55 47 220K vm_area_struct 2263 2116 93% 0.12K 73 31 292K size-128 1904 1125 59% 0.03K 16 119 64K size-32 1666 768 46% 0.03K 14 119 56K anon_vma 1512 1482 98% 0.44K 168 9 672K inode_cache 1464 1040 71% 0.06K 24 61 96K size-64 1320 820 62% 0.19K 66 20 264K filp 678 587 86% 0.02K 3 226 12K dm_io 678 587 86% 0.02K 3 226 12K dm_tio 576 574 99% 0.47K 72 8 288K proc_inode_cache 528 514 97% 0.50K 66 8 264K size-512 492 372 75% 0.09K 12 41 48K bio 465 314 67% 0.25K 31 15 124K size-256 452 331 73% 0.02K 2 226 8K biovec-1 420 420 100% 0.19K 21 20 84K skbuff_head_cache 305 256 83% 0.06K 5 61 20K biovec-4 290 4 1% 0.01K 1 290 4K revoke_table 264 264 100% 4.00K 264 1 1056K size-4096 260 256 98% 0.19K 13 20 52K biovec-16 260 256 98% 0.75K 52 5 208K biovec-64
/proc/slabinfo that are included into /usr/bin/slabtop include:
OBJS — The total number of objects (memory blocks), including those in use (allocated), and some spares not in use.
ACTIVE — The number of objects (memory blocks) that are in use (allocated).
USE — Percentage of total objects that are active. ((ACTIVE/OBJS)(100))
OBJ SIZE — The size of the objects.
SLABS — The total number of slabs.
OBJ/SLAB — The number of objects that fit into a slab.
CACHE SIZE — The cache size of the slab.
NAME — The name of the slab.
/usr/bin/slabtop program, refer to the slabtop man page.
/proc/stat, which can be quite long, usually begins like the following example:
cpu 259246 7001 60190 34250993 137517 772 0 cpu0 259246 7001 60190 34250993 137517 772 0 intr 354133732 347209999 2272 0 4 4 0 0 3 1 1249247 0 0 80143 0 422626 5169433 ctxt 12547729 btime 1093631447 processes 130523 procs_running 1 procs_blocked 0 preempt 5651840 cpu 209841 1554 21720 118519346 72939 154 27168 cpu0 42536 798 4841 14790880 14778 124 3117 cpu1 24184 569 3875 14794524 30209 29 3130 cpu2 28616 11 2182 14818198 4020 1 3493 cpu3 35350 6 2942 14811519 3045 0 3659 cpu4 18209 135 2263 14820076 12465 0 3373 cpu5 20795 35 1866 14825701 4508 0 3615 cpu6 21607 0 2201 14827053 2325 0 3334 cpu7 18544 0 1550 14831395 1589 0 3447 intr 15239682 14857833 6 0 6 6 0 5 0 1 0 0 0 29 0 2 0 0 0 0 0 0 0 94982 0 286812 ctxt 4209609 btime 1078711415 processes 21905 procs_running 1 procs_blocked 0
cpu — Measures the number of jiffies (1/100 of a second for x86 systems) that the system has been in user mode, user mode with low priority (nice), system mode, idle task, I/O wait, IRQ (hardirq), and softirq respectively. The IRQ (hardirq) is the direct response to a hardware event. The IRQ takes minimal work for queuing the "heavy" work up for the softirq to execute. The softirq runs at a lower priority than the IRQ and therefore may be interrupted more frequently. The total for all CPUs is given at the top, while each individual CPU is listed below with its own statistics. The following example is a 4-way Intel Pentium Xeon configuration with multi-threading enabled, therefore showing four physical processors and four virtual processors totaling eight processors.
page — The number of memory pages the system has written in and out to disk.
swap — The number of swap pages the system has brought in and out.
intr — The number of interrupts the system has experienced.
btime — The boot time, measured in the number of seconds since January 1, 1970, otherwise known as the epoch.
/proc/swaps may look similar to the following:
Filename Type Size Used Priority /dev/mapper/VolGroup00-LogVol01 partition 524280 0 -1
/proc/ directory, /proc/swap provides a snapshot of every swap file name, the type of swap space, the total size, and the amount of space in use (in kilobytes). The priority column is useful when multiple swap files are in use. The lower the priority, the more likely the swap file is to be used.
echo command to write to this file, a remote root user can execute most System Request Key commands remotely as if at the local terminal. To echo values to this file, the /proc/sys/kernel/sysrq must be set to a value other than 0. For more information about the System Request Key, refer to Раздел E.3.9.3, « /proc/sys/kernel/ ».
/proc/uptime is quite minimal:
350735.47 234388.90
gcc used to compile the kernel, and the time of kernel compilation. It also contains the kernel compiler's user name (in parentheses).
Linux version 2.6.8-1.523 (user@foo.redhat.com) (gcc version 3.4.1 20040714 \ (Red Hat Enterprise Linux 3.4.1-7)) #1 Mon Aug 16 13:27:03 EDT 2004
/proc/ directory.
/proc/ directory contains a number of directories with numerical names. A listing of them may be similar to the following:
dr-xr-xr-x 3 root root 0 Feb 13 01:28 1 dr-xr-xr-x 3 root root 0 Feb 13 01:28 1010 dr-xr-xr-x 3 xfs xfs 0 Feb 13 01:28 1087 dr-xr-xr-x 3 daemon daemon 0 Feb 13 01:28 1123 dr-xr-xr-x 3 root root 0 Feb 13 01:28 11307 dr-xr-xr-x 3 apache apache 0 Feb 13 01:28 13660 dr-xr-xr-x 3 rpc rpc 0 Feb 13 01:28 637 dr-xr-xr-x 3 rpcuser rpcuser 0 Feb 13 01:28 666
/proc/ process directory vanishes.
cmdline — Contains the command issued when starting the process.
cwd — A symbolic link to the current working directory for the process.
environ — A list of the environment variables for the process. The environment variable is given in all upper-case characters, and the value is in lower-case characters.
exe — A symbolic link to the executable of this process.
fd — A directory containing all of the file descriptors for a particular process. These are given in numbered links:
total 0 lrwx------ 1 root root 64 May 8 11:31 0 -> /dev/null lrwx------ 1 root root 64 May 8 11:31 1 -> /dev/null lrwx------ 1 root root 64 May 8 11:31 2 -> /dev/null lrwx------ 1 root root 64 May 8 11:31 3 -> /dev/ptmx lrwx------ 1 root root 64 May 8 11:31 4 -> socket:[7774817] lrwx------ 1 root root 64 May 8 11:31 5 -> /dev/ptmx lrwx------ 1 root root 64 May 8 11:31 6 -> socket:[7774829] lrwx------ 1 root root 64 May 8 11:31 7 -> /dev/ptmx
maps — A list of memory maps to the various executables and library files associated with this process. This file can be rather long, depending upon the complexity of the process, but sample output from the sshd process begins like the following:
08048000-08086000 r-xp 00000000 03:03 391479 /usr/sbin/sshd 08086000-08088000 rw-p 0003e000 03:03 391479 /usr/sbin/sshd 08088000-08095000 rwxp 00000000 00:00 0 40000000-40013000 r-xp 0000000 03:03 293205 /lib/ld-2.2.5.so 40013000-40014000 rw-p 00013000 03:03 293205 /lib/ld-2.2.5.so 40031000-40038000 r-xp 00000000 03:03 293282 /lib/libpam.so.0.75 40038000-40039000 rw-p 00006000 03:03 293282 /lib/libpam.so.0.75 40039000-4003a000 rw-p 00000000 00:00 0 4003a000-4003c000 r-xp 00000000 03:03 293218 /lib/libdl-2.2.5.so 4003c000-4003d000 rw-p 00001000 03:03 293218 /lib/libdl-2.2.5.so
mem — The memory held by the process. This file cannot be read by the user.
root — A link to the root directory of the process.
stat — The status of the process.
statm — The status of the memory in use by the process. Below is a sample /proc/statm file:
263 210 210 5 0 205 0
status — The status of the process in a more readable form than stat or statm. Sample output for sshd looks similar to the following:
Name: sshd State: S (sleeping) Tgid: 797 Pid: 797 PPid: 1 TracerPid: 0 Uid: 0 0 0 0 Gid: 0 0 0 0 FDSize: 32 Groups: VmSize: 3072 kB VmLck: 0 kB VmRSS: 840 kB VmData: 104 kB VmStk: 12 kB VmExe: 300 kB VmLib: 2528 kB SigPnd: 0000000000000000 SigBlk: 0000000000000000 SigIgn: 8000000000001000 SigCgt: 0000000000014005 CapInh: 0000000000000000 CapPrm: 00000000fffffeff CapEff: 00000000fffffeff
S (sleeping) or R (running)), user/group ID running the process, and detailed data regarding memory usage.
/proc/self/ directory is a link to the currently running process. This allows a process to look at itself without having to know its process ID.
/proc/self/ directory produces the same contents as listing the process directory for that process.
/proc/bus/ by the same name, such as /proc/bus/pci/.
/proc/bus/ vary depending on the devices connected to the system. However, each bus type has at least one directory. Within these bus directories are normally at least one subdirectory with a numerical name, such as 001, which contain binary files.
/proc/bus/usb/ subdirectory contains files that track the various devices on any USB buses, as well as the drivers required for them. The following is a sample listing of a /proc/bus/usb/ directory:
total 0 dr-xr-xr-x 1 root root 0 May 3 16:25 001 -r--r--r-- 1 root root 0 May 3 16:25 devices -r--r--r-- 1 root root 0 May 3 16:25 drivers
/proc/bus/usb/001/ directory contains all devices on the first USB bus and the devices file identifies the USB root hub on the motherboard.
/proc/bus/usb/devices file:
T: Bus=01 Lev=00 Prnt=00 Port=00 Cnt=00 Dev#= 1 Spd=12 MxCh= 2 B: Alloc= 0/900 us ( 0%), #Int= 0, #Iso= 0 D: Ver= 1.00 Cls=09(hub ) Sub=00 Prot=00 MxPS= 8 #Cfgs= 1 P: Vendor=0000 ProdID=0000 Rev= 0.00 S: Product=USB UHCI Root Hub S: SerialNumber=d400 C:* #Ifs= 1 Cfg#= 1 Atr=40 MxPwr= 0mA I: If#= 0 Alt= 0 #EPs= 1 Cls=09(hub ) Sub=00 Prot=00 Driver=hub E: Ad=81(I) Atr=03(Int.) MxPS= 8 Ivl=255ms
/proc/pci directory in favor of the /proc/bus/pci directory. Although you can get a list of all PCI devices present on the system using the command cat /proc/bus/pci/devices, the output is difficult to read and interpret.
~]# /sbin/lspci -vb
00:00.0 Host bridge: Intel Corporation 82X38/X48 Express DRAM Controller
Subsystem: Hewlett-Packard Company Device 1308
Flags: bus master, fast devsel, latency 0
Capabilities: [e0] Vendor Specific Information <?>
Kernel driver in use: x38_edac
Kernel modules: x38_edac
00:01.0 PCI bridge: Intel Corporation 82X38/X48 Express Host-Primary PCI Express Bridge (prog-if 00 [Normal decode])
Flags: bus master, fast devsel, latency 0
Bus: primary=00, secondary=01, subordinate=01, sec-latency=0
I/O behind bridge: 00001000-00001fff
Memory behind bridge: f0000000-f2ffffff
Capabilities: [88] Subsystem: Hewlett-Packard Company Device 1308
Capabilities: [80] Power Management version 3
Capabilities: [90] MSI: Enable+ Count=1/1 Maskable- 64bit-
Capabilities: [a0] Express Root Port (Slot+), MSI 00
Capabilities: [100] Virtual Channel <?>
Capabilities: [140] Root Complex Link <?>
Kernel driver in use: pcieport
Kernel modules: shpchp
00:1a.0 USB Controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #4 (rev 02) (prog-if 00 [UHCI])
Subsystem: Hewlett-Packard Company Device 1308
Flags: bus master, medium devsel, latency 0, IRQ 5
I/O ports at 2100
Capabilities: [50] PCI Advanced Features
Kernel driver in use: uhci_hcd
[output truncated]
rtc which provides output from the driver for the system's Real Time Clock (RTC), the device that keeps the time while the system is switched off. Sample output from /proc/driver/rtc looks like the following:
rtc_time : 16:21:00 rtc_date : 2004-08-31 rtc_epoch : 1900 alarm : 21:16:27 DST_enable : no BCD : yes 24hr : yes square_wave : no alarm_IRQ : no update_IRQ : no periodic_IRQ : no periodic_freq : 1024 batt_status : okay
/usr/share/doc/kernel-doc-<kernel_version>/Documentation/rtc.txt.
cat /proc/fs/nfsd/exports displays the file systems being shared and the permissions granted for those file systems. For more on file system sharing with NFS, refer to the Network File System (NFS) chapter of the Storage Administration Guide.
/proc/irq/prof_cpu_mask file is a bitmask that contains the default values for the smp_affinity file in the IRQ directory. The values in smp_affinity specify which CPUs handle that particular IRQ.
/proc/irq/ directory, refer to the following installed documentation:
/usr/share/doc/kernel-doc-kernel_version/Documentation/filesystems/proc.txt
/proc/net/ directory:
arp — Lists the kernel's ARP table. This file is particularly useful for connecting a hardware address to an IP address on a system.
atm/ directory — The files within this directory contain Asynchronous Transfer Mode (ATM) settings and statistics. This directory is primarily used with ATM networking and ADSL cards.
dev — Lists the various network devices configured on the system, complete with transmit and receive statistics. This file displays the number of bytes each interface has sent and received, the number of packets inbound and outbound, the number of errors seen, the number of packets dropped, and more.
dev_mcast — Lists Layer2 multicast groups on which each device is listening.
igmp — Lists the IP multicast addresses which this system joined.
ip_conntrack — Lists tracked network connections for machines that are forwarding IP connections.
ip_tables_names — Lists the types of iptables in use. This file is only present if iptables is active on the system and contains one or more of the following values: filter, mangle, or nat.
ip_mr_cache — Lists the multicast routing cache.
ip_mr_vif — Lists multicast virtual interfaces.
netstat — Contains a broad yet detailed collection of networking statistics, including TCP timeouts, SYN cookies sent and received, and much more.
psched — Lists global packet scheduler parameters.
raw — Lists raw device statistics.
route — Lists the kernel's routing table.
rt_cache — Contains the current routing cache.
snmp — List of Simple Network Management Protocol (SNMP) data for various networking protocols in use.
sockstat — Provides socket statistics.
tcp — Contains detailed TCP socket information.
tr_rif — Lists the token ring RIF routing table.
udp — Contains detailed UDP socket information.
unix — Lists UNIX domain sockets currently in use.
wireless — Lists wireless interface data.
/proc/scsi/scsi, which contains a list of every recognized SCSI device. From this listing, the type of device, as well as the model name, vendor, SCSI channel and ID data is available.
Attached devices: Host: scsi1 Channel: 00 Id: 05 Lun: 00 Vendor: NEC Model: CD-ROM DRIVE:466 Rev: 1.06 Type: CD-ROM ANSI SCSI revision: 02 Host: scsi1 Channel: 00 Id: 06 Lun: 00 Vendor: ARCHIVE Model: Python 04106-XXX Rev: 7350 Type: Sequential-Access ANSI SCSI revision: 02 Host: scsi2 Channel: 00 Id: 06 Lun: 00 Vendor: DELL Model: 1x6 U2W SCSI BP Rev: 5.35 Type: Processor ANSI SCSI revision: 02 Host: scsi2 Channel: 02 Id: 00 Lun: 00 Vendor: MegaRAID Model: LD0 RAID5 34556R Rev: 1.01 Type: Direct-Access ANSI SCSI revision: 02
/proc/scsi/, which contains files specific to each SCSI controller using that driver. From the previous example, aic7xxx/ and megaraid/ directories are present, since two drivers are in use. The files in each of the directories typically contain an I/O address range, IRQ information, and statistics for the SCSI controller using that driver. Each controller can report a different type and amount of information. The Adaptec AIC-7880 Ultra SCSI host adapter's file in this example system produces the following output:
Adaptec AIC7xxx driver version: 5.1.20/3.2.4
Compile Options:
TCQ Enabled By Default : Disabled
AIC7XXX_PROC_STATS : Enabled
AIC7XXX_RESET_DELAY : 5
Adapter Configuration:
SCSI Adapter: Adaptec AIC-7880 Ultra SCSI host adapter
Ultra Narrow Controller PCI MMAPed
I/O Base: 0xfcffe000
Adapter SEEPROM Config: SEEPROM found and used.
Adaptec SCSI BIOS: Enabled
IRQ: 30
SCBs: Active 0, Max Active 1, Allocated 15, HW 16, Page 255
Interrupts: 33726
BIOS Control Word: 0x18a6
Adapter Control Word: 0x1c5f
Extended Translation: Enabled
Disconnect Enable Flags: 0x00ff
Ultra Enable Flags: 0x0020
Tag Queue Enable Flags: 0x0000
Ordered Queue Tag Flags: 0x0000
Default Tag Queue Depth: 8
Tagged Queue By Device array for aic7xxx
host instance 1: {255,255,255,255,255,255,255,255,255,255,255,255,255,255,255,255}
Actual queue depth per device for aic7xxx host instance 1: {1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1}
Statistics:
(scsi1:0:5:0) Device using Narrow/Sync transfers at 20.0 MByte/sec, offset 15
Transinfo settings: current(12/15/0/0), goal(12/15/0/0), user(12/15/0/0)
Total transfers 0 (0 reads and 0 writes)
< 2K 2K+ 4K+ 8K+ 16K+ 32K+ 64K+ 128K+
Reads: 0 0 0 0 0 0 0 0
Writes: 0 0 0 0 0 0 0 0
(scsi1:0:6:0) Device using Narrow/Sync transfers at 10.0 MByte/sec, offset 15
Transinfo settings: current(25/15/0/0), goal(12/15/0/0), user(12/15/0/0)
Total transfers 132 (0 reads and 132 writes)
< 2K 2K+ 4K+ 8K+ 16K+ 32K+ 64K+ 128K+
Reads: 0 0 0 0 0 0 0 0
Writes: 0 0 0 1 131 0 0 0
/proc/sys/ directory is different from others in /proc/ because it not only provides information about the system but also allows the system administrator to immediately enable and disable kernel features.
/proc/sys/ directory. Changing the wrong setting may render the kernel unstable, requiring a system reboot.
/proc/sys/.
-l option at the shell prompt. If the file is writable, it may be used to configure the kernel. For example, a partial listing of /proc/sys/fs looks like the following:
-r--r--r-- 1 root root 0 May 10 16:14 dentry-state -rw-r--r-- 1 root root 0 May 10 16:14 dir-notify-enable -rw-r--r-- 1 root root 0 May 10 16:14 file-max -r--r--r-- 1 root root 0 May 10 16:14 file-nr
dir-notify-enable and file-max can be written to and, therefore, can be used to configure the kernel. The other files only provide feedback on current settings.
/proc/sys/ file is done by echoing the new value into the file. For example, to enable the System Request Key on a running kernel, type the command:
echo 1 > /proc/sys/kernel/sysrq
sysrq from 0 (off) to 1 (on).
/proc/sys/ configuration files contain more than one value. To correctly send new values to them, place a space character between each value passed with the echo command, such as is done in this example:
echo 4 2 45 > /proc/sys/kernel/acct
echo command disappear when the system is restarted. To make configuration changes take effect after the system is rebooted, refer to Раздел E.4, «Using the sysctl Command».
/proc/sys/ directory contains several subdirectories controlling different aspects of a running kernel.
cdrom/ and raid/. Customized kernels can have other directories, such as parport/, which provides the ability to share one parallel port between multiple device drivers.
cdrom/ directory contains a file called info, which reveals a number of important CD-ROM parameters:
CD-ROM information, Id: cdrom.c 3.20 2003/12/17 drive name: hdc drive speed: 48 drive # of slots: 1 Can close tray: 1 Can open tray: 1 Can lock tray: 1 Can change speed: 1 Can select disk: 0 Can read multisession: 1 Can read MCN: 1 Reports media changed: 1 Can play audio: 1 Can write CD-R: 0 Can write CD-RW: 0 Can read DVD: 0 Can write DVD-R: 0 Can write DVD-RAM: 0 Can read MRW: 0 Can write MRW: 0 Can write RAM: 0
/proc/sys/dev/cdrom, such as autoclose and checkmedia, can be used to control the system's CD-ROM. Use the echo command to enable or disable these features.
/proc/sys/dev/raid/ directory becomes available with at least two files in it: speed_limit_min and speed_limit_max. These settings determine the acceleration of RAID devices for I/O intensive tasks, such as resyncing the disks.
binfmt_misc/ directory is used to provide kernel support for miscellaneous binary formats.
/proc/sys/fs/ include:
dentry-state — Provides the status of the directory cache. The file looks similar to the following:
57411 52939 45 0 0 0
file-max — Lists the maximum number of file handles that the kernel allocates. Raising the value in this file can resolve errors caused by a lack of available file handles.
file-nr — Lists the number of allocated file handles, used file handles, and the maximum number of file handles.
overflowgid and overflowuid — Defines the fixed group ID and user ID, respectively, for use with file systems that only support 16-bit group and user IDs.
acct — Controls the suspension of process accounting based on the percentage of free space available on the file system containing the log. By default, the file looks like the following:
4 2 30
ctrl-alt-del — Controls whether Ctrl+Alt+Delete gracefully restarts the computer using init (0) or forces an immediate reboot without syncing the dirty buffers to disk (1).
domainname — Configures the system domain name, such as example.com.
exec-shield — Configures the Exec Shield feature of the kernel. Exec Shield provides protection against certain types of buffer overflow attacks.
0 — Disables Exec Shield.
1 — Enables Exec Shield. This is the default value.
hostname — Configures the system hostname, such as www.example.com.
hotplug — Configures the utility to be used when a configuration change is detected by the system. This is primarily used with USB and Cardbus PCI. The default value of /sbin/hotplug should not be changed unless testing a new program to fulfill this role.
modprobe — Sets the location of the program used to load kernel modules. The default value is /sbin/modprobe which means kmod calls it to load the module when a kernel thread calls kmod.
msgmax — Sets the maximum size of any message sent from one process to another and is set to 8192 bytes by default. Be careful when raising this value, as queued messages between processes are stored in non-swappable kernel memory. Any increase in msgmax would increase RAM requirements for the system.
msgmnb — Sets the maximum number of bytes in a single message queue. The default is 16384.
msgmni — Sets the maximum number of message queue identifiers. The default is 4008.
osrelease — Lists the Linux kernel release number. This file can only be altered by changing the kernel source and recompiling.
ostype — Displays the type of operating system. By default, this file is set to Linux, and this value can only be changed by changing the kernel source and recompiling.
overflowgid and overflowuid — Defines the fixed group ID and user ID, respectively, for use with system calls on architectures that only support 16-bit group and user IDs.
panic — Defines the number of seconds the kernel postpones rebooting when the system experiences a kernel panic. By default, the value is set to 0, which disables automatic rebooting after a panic.
printk — This file controls a variety of settings related to printing or logging error messages. Each error message reported by the kernel has a loglevel associated with it that defines the importance of the message. The loglevel values break down in this order:
0 — Kernel emergency. The system is unusable.
1 — Kernel alert. Action must be taken immediately.
2 — Condition of the kernel is considered critical.
3 — General kernel error condition.
4 — General kernel warning condition.
5 — Kernel notice of a normal but significant condition.
6 — Kernel informational message.
7 — Kernel debug-level messages.
printk file:
6 4 1 7
random/ directory — Lists a number of values related to generating random numbers for the kernel.
sem — Configures semaphore settings within the kernel. A semaphore is a System V IPC object that is used to control utilization of a particular process.
shmall — Sets the total amount of shared memory that can be used at one time on the system, in bytes. By default, this value is 2097152.
shmmax — Sets the largest shared memory segment size allowed by the kernel. By default, this value is 33554432. However, the kernel supports much larger values than this.
shmmni — Sets the maximum number of shared memory segments for the whole system. By default, this value is 4096.
sysrq — Activates the System Request Key, if this value is set to anything other than zero (0), the default.
system request code . Replace system request code with one of the following system request codes:
r — Disables raw mode for the keyboard and sets it to XLATE (a limited keyboard mode which does not recognize modifiers such as Alt, Ctrl, or Shift for all keys).
k — Kills all processes active in a virtual console. Also called Secure Access Key (SAK), it is often used to verify that the login prompt is spawned from init and not a trojan copy designed to capture usernames and passwords.
b — Reboots the kernel without first unmounting file systems or syncing disks attached to the system.
c — Crashes the system without first unmounting file systems or syncing disks attached to the system.
o — Shuts off the system.
s — Attempts to sync disks attached to the system.
u — Attempts to unmount and remount all file systems as read-only.
p — Outputs all flags and registers to the console.
t — Outputs a list of processes to the console.
m — Outputs memory statistics to the console.
0 through 9 — Sets the log level for the console.
e — Kills all processes except init using SIGTERM.
i — Kills all processes except init using SIGKILL.
l — Kills all processes using SIGKILL (including init). The system is unusable after issuing this System Request Key code.
h — Displays help text.
/usr/share/doc/kernel-doc-kernel_version/Documentation/sysrq.txt for more information about the System Request Key.
tainted — Indicates whether a non-GPL module is loaded.
0 — No non-GPL modules are loaded.
1 — At least one module without a GPL license (including modules with no license) is loaded.
2 — At least one module was force-loaded with the command insmod -f.
threads-max — Sets the maximum number of threads to be used by the kernel, with a default value of 2048.
version — Displays the date and time the kernel was last compiled. The first field in this file, such as #3, relates to the number of times a kernel was built from the source base.
ethernet/, ipv4/, ipx/, and ipv6/. By altering the files within these directories, system administrators are able to adjust the network configuration on a running system.
/proc/sys/net/ directories are discussed.
/proc/sys/net/core/ directory contains a variety of settings that control the interaction between the kernel and networking layers. The most important of these files are:
message_burst — Sets the amount of time in tenths of a second required to write a new warning message. This setting is used to mitigate Denial of Service (DoS) attacks. The default setting is 10.
message_cost — Sets a cost on every warning message. The higher the value of this file (default of 5), the more likely the warning message is ignored. This setting is used to mitigate DoS attacks.
message_burst and message_cost are designed to be modified based on the system's acceptable risk versus the need for comprehensive logging.
netdev_max_backlog — Sets the maximum number of packets allowed to queue when a particular interface receives packets faster than the kernel can process them. The default value for this file is 1000.
optmem_max — Configures the maximum ancillary buffer size allowed per socket.
rmem_default — Sets the receive socket buffer default size in bytes.
rmem_max — Sets the receive socket buffer maximum size in bytes.
wmem_default — Sets the send socket buffer default size in bytes.
wmem_max — Sets the send socket buffer maximum size in bytes.
/proc/sys/net/ipv4/ directory contains additional networking settings. Many of these settings, used in conjunction with one another, are useful in preventing attacks on the system or when using the system to act as a router.
/proc/sys/net/ipv4/ directory:
icmp_echo_ignore_all and icmp_echo_ignore_broadcasts — Allows the kernel to ignore ICMP ECHO packets from every host or only those originating from broadcast and multicast addresses, respectively. A value of 0 allows the kernel to respond, while a value of 1 ignores the packets.
ip_default_ttl — Sets the default Time To Live (TTL), which limits the number of hops a packet may make before reaching its destination. Increasing this value can diminish system performance.
ip_forward — Permits interfaces on the system to forward packets to one other. By default, this file is set to 0. Setting this file to 1 enables network packet forwarding.
ip_local_port_range — Specifies the range of ports to be used by TCP or UDP when a local port is needed. The first number is the lowest port to be used and the second number specifies the highest port. Any systems that expect to require more ports than the default 1024 to 4999 should use a range from 32768 to 61000.
tcp_syn_retries — Provides a limit on the number of times the system re-transmits a SYN packet when attempting to make a connection.
tcp_retries1 — Sets the number of permitted re-transmissions attempting to answer an incoming connection. Default of 3.
tcp_retries2 — Sets the number of permitted re-transmissions of TCP packets. Default of 15.
/usr/share/doc/kernel-doc-kernel_version/Documentation/networking/ip-sysctl.txt
/proc/sys/net/ipv4/ directory.
/proc/sys/net/ipv4/ directory and each covers a different aspect of the network stack. The /proc/sys/net/ipv4/conf/ directory allows each system interface to be configured in different ways, including the use of default settings for unconfigured devices (in the /proc/sys/net/ipv4/conf/default/ subdirectory) and settings that override all special configurations (in the /proc/sys/net/ipv4/conf/all/ subdirectory).
/proc/sys/net/ipv4/neigh/ directory contains settings for communicating with a host directly connected to the system (called a network neighbor) and also contains different settings for systems more than one hop away.
/proc/sys/net/ipv4/route/. Unlike conf/ and neigh/, the /proc/sys/net/ipv4/route/ directory contains specifications that apply to routing with any interfaces on the system. Many of these settings, such as max_size, max_delay, and min_delay, relate to controlling the size of the routing cache. To clear the routing cache, write any value to the flush file.
/usr/share/doc/kernel-doc-kernel_version/Documentation/filesystems/proc.txt
/proc/sys/vm/ directory:
block_dump — Configures block I/O debugging when enabled. All read/write and block dirtying operations done to files are logged accordingly. This can be useful if diagnosing disk spin up and spin downs for laptop battery conservation. All output when block_dump is enabled can be retrieved via dmesg. The default value is 0.
block_dump is enabled at the same time as kernel debugging, it is prudent to stop the klogd daemon, as it generates erroneous disk activity caused by block_dump.
dirty_background_ratio — Starts background writeback of dirty data at this percentage of total memory, via a pdflush daemon. The default value is 10.
dirty_expire_centisecs — Defines when dirty in-memory data is old enough to be eligible for writeout. Data which has been dirty in-memory for longer than this interval is written out next time a pdflush daemon wakes up. The default value is 3000, expressed in hundredths of a second.
dirty_ratio — Starts active writeback of dirty data at this percentage of total memory for the generator of dirty data, via pdflush. The default value is 20.
dirty_writeback_centisecs — Defines the interval between pdflush daemon wakeups, which periodically writes dirty in-memory data out to disk. The default value is 500, expressed in hundredths of a second.
laptop_mode — Minimizes the number of times that a hard disk needs to spin up by keeping the disk spun down for as long as possible, therefore conserving battery power on laptops. This increases efficiency by combining all future I/O processes together, reducing the frequency of spin ups. The default value is 0, but is automatically enabled in case a battery on a laptop is used.
/usr/share/doc/kernel-doc-kernel_version/Documentation/laptop-mode.txt
max_map_count — Configures the maximum number of memory map areas a process may have. In most cases, the default value of 65536 is appropriate.
min_free_kbytes — Forces the Linux VM (virtual memory manager) to keep a minimum number of kilobytes free. The VM uses this number to compute a pages_min value for each lowmem zone in the system. The default value is in respect to the total memory on the machine.
nr_hugepages — Indicates the current number of configured hugetlb pages in the kernel.
/usr/share/doc/kernel-doc-kernel_version/Documentation/vm/hugetlbpage.txt
nr_pdflush_threads — Indicates the number of pdflush daemons that are currently running. This file is read-only, and should not be changed by the user. Under heavy I/O loads, the default value of two is increased by the kernel.
overcommit_memory — Configures the conditions under which a large memory request is accepted or denied. The following three modes are available:
0 — The kernel performs heuristic memory over commit handling by estimating the amount of memory available and failing requests that are blatantly invalid. Unfortunately, since memory is allocated using a heuristic rather than a precise algorithm, this setting can sometimes allow available memory on the system to be overloaded. This is the default setting.
1 — The kernel performs no memory over commit handling. Under this setting, the potential for memory overload is increased, but so is performance for memory intensive tasks (such as those executed by some scientific software).
2 — The kernel fails requests for memory that add up to all of swap plus the percent of physical RAM specified in /proc/sys/vm/overcommit_ratio. This setting is best for those who desire less risk of memory overcommitment.
overcommit_ratio — Specifies the percentage of physical RAM considered when /proc/sys/vm/overcommit_memory is set to 2. The default value is 50.
page-cluster — Sets the number of pages read in a single attempt. The default value of 3, which actually relates to 16 pages, is appropriate for most systems.
swappiness — Determines how much a machine should swap. The higher the value, the more swapping occurs. The default value, as a percentage, is set to 60.
/usr/share/doc/kernel-doc-kernel_version/Documentation/, which contains additional information.
msg), semaphores (sem), and shared memory (shm).
drivers file is a list of the current tty devices in use, as in the following example:
serial /dev/cua 5 64-127 serial:callout serial /dev/ttyS 4 64-127 serial pty_slave /dev/pts 136 0-255 pty:slave pty_master /dev/ptm 128 0-255 pty:master pty_slave /dev/ttyp 3 0-255 pty:slave pty_master /dev/pty 2 0-255 pty:master /dev/vc/0 /dev/vc/0 4 0 system:vtmaster /dev/ptmx /dev/ptmx 5 2 system /dev/console /dev/console 5 1 system:console /dev/tty /dev/tty 5 0 system:/dev/tty unknown /dev/vc/%d 4 1-63 console
/proc/tty/driver/serial file lists the usage statistics and status of each of the serial tty lines.
PID/ /proc/sys/vm/panic_on_oom. When set to 1 the kernel will panic on OOM. A setting of 0 instructs the kernel to call a function named oom_killer on an OOM. Usually, oom_killer can kill rogue processes and the system will survive.
/proc/sys/vm/panic_on_oom.
# cat /proc/sys/vm/panic_on_oom 1 # echo 0 > /proc/sys/vm/panic_on_oom # cat /proc/sys/vm/panic_on_oom 0
oom_killer score. In /proc/PID/ there are two tools labeled oom_adj and oom_score. Valid scores for oom_adj are in the range -16 to +15. To see the current oom_killer score, view the oom_score for the process. oom_killer will kill processes with the highest scores first.
PID of 12465 to make it less likely that oom_killer will kill it.
# cat /proc/12465/oom_score 79872 # echo -5 > /proc/12465/oom_adj # cat /proc/12465/oom_score 78
oom_killer for that process. In the example below, oom_score returns a value of 0, indicating that this process would not be killed.
# cat /proc/12465/oom_score 78 # echo -17 > /proc/12465/oom_adj # cat /proc/12465/oom_score 0
badness() is used to determine the actual score for each process. This is done by adding up 'points' for each examined process. The process scoring is done in the following way:
CAP_SYS_ADMIN and CAP_SYS_RAWIO capabilities have their scores reduced.
oom_adj file.
oom_score value will most probably be a non-priviliged, recently started process that, along with its children, uses a large amount of memory, has been 'niced', and handles no raw I/O.
/sbin/sysctl command is used to view, set, and automate kernel settings in the /proc/sys/ directory.
/proc/sys/ directory, type the /sbin/sysctl -a command as root. This creates a large, comprehensive list, a small portion of which looks something like the following:
net.ipv4.route.min_delay = 2 kernel.sysrq = 0 kernel.sem = 250 32000 32 128
/proc/sys/net/ipv4/route/min_delay file is listed as net.ipv4.route.min_delay, with the directory slashes replaced by dots and the proc.sys portion assumed.
sysctl command can be used in place of echo to assign values to writable files in the /proc/sys/ directory. For example, instead of using the command
echo 1 > /proc/sys/kernel/sysrq
sysctl command as follows:
sysctl -w kernel.sysrq="1" kernel.sysrq = 1
/proc/sys/ is helpful during testing, this method does not work as well on a production system as special settings within /proc/sys/ are lost when the machine is rebooted. To preserve custom settings, add them to the /etc/sysctl.conf file.
systemd executes sysctl using the /etc/sysctl.conf configuration file to determine the values passed to the kernel. Any values added to /etc/sysctl.conf therefore take effect each time the system boots.
systemd determines the contents of several directories including /etc/sysctl.d/ and reads values from any file with the .conf extension. The /etc/sysctl.d/ directory can be used to organize values into different files, and also permits them to be disabled by changing the extension of the file. For a complete list of directories read by systemd, refer to the sysctl.d(5) manual page.
proc file system.
proc file system is installed on the system by default.
/usr/share/doc/kernel-doc-kernel_version/Documentation/filesystems/proc.txt — Contains assorted, but limited, information about all aspects of the /proc/ directory.
/usr/share/doc/kernel-doc-kernel_version/Documentation/sysrq.txt — An overview of System Request Key options.
/usr/share/doc/kernel-doc-kernel_version/Documentation/sysctl/ — A directory containing a variety of sysctl tips, including modifying values that concern the kernel (kernel.txt), accessing file systems (fs.txt), and virtual memory use (vm.txt).
/usr/share/doc/kernel-doc-kernel_version/Documentation/networking/ip-sysctl.txt — A detailed overview of IP networking options.
| История переиздания | |||
|---|---|---|---|
| Издание 1-1 | Thu Aug 9 2012 | ||
| |||
| Издание 1-0 | Tue May 29 2012 | ||
| |||