Глава 1. Введение в контрольные группы
Fedora 17 предоставляет механизм управления ресурсами системы — контрольные группы или cgroups(от англ. control groups). Механизм контрольных групп позволяет распределять системные ресурсы между определнными пользователем группами задач (процессов). Такими ресурсами могут быть, например, процессорное время, оперативная память, доступ к сети или их некоторая комбинация. Настроив контрольные группы, можно следить за потреблением ими ресурсов, запрещать доступ к некоторым ресурсам со стороны определенных контрольных групп и динамически менять распределение ресурсов в работающей системе. С помощью системной службы cgconfig можно обеспечить сохранение конфигурации контрольных групп между перезагрузками.
Используя контрольные группы, администратор получает возможность тонкого контроля над распределением, приоритизацией и управлением системными ресурсами. Для повышения общей эффективности ресурсы оборудования могут быть точно поделены между задачами и пользователями.
1.1. Организация контрольных групп
Подобно процессам, контрольные группы организованы иерархически, и дочерние группы наследуют некоторые атрибуты родительских. Однако между этими двумя моделями существуют различия.
Модель организации процессов Linux
Все процессы в Linux имеют одного общего предка — процесс init, который создается ядром во время загрузки системы и запускает другие процессы (которые в свою очередь запускают свои собственные дочерние процессы). Поскольку все процессы происходят от одного предка, то модель органицации процессов Linux представляет собой единую иерархическую структуру или дерево.
Кроме того, все процессы в Linux за исключением процесса init наследуют параметры среды (переменную PATH и пр.)[] и другие атрибуты родительского процесса (дескрипторы открытых файлов и т.п.).
Модель организации контрольных групп
Контрольные группы схожи с процессами в следующем:
Основное отличие заключается в том, что в системе одновременно может существовать множество независимых иерархий контрольных групп. Если модель организации процессов в Linux — это единое дерево, то модель организации контрольных групп — это одно или несколько отдельных, несвязанных деревьев задач (т.е. процессов).
Необходимость множества отдельных иерархий контрольных групп вызвана тем, что каждая иерархия подключается к одной или нескольким подсистемам. Подсистема[] представляет собой отдельный тип ресурса, например, процессорное время или оперативную память. В Fedora 17 существует 9 подсистем, перечисленных ниже по именам и функциям.
Подсистемы доступные в Fedora
blkio: ограничивает доступ к вводу-выводу на блочные устройства (диски, USB и т.п.).
cpu: с помощью планировщика процессов предоставляет задачам контрольных групп доступ к процессору.
cpuacct: генерирует отчеты об использовании процессорных ресурсов задачами, входящими в контрольную группу.
cpuset: выделяет определенные процессоры и узлы памяти задачам контрольной группы.
devices: разрешает или запрещает доступ к устройствам со стороны задач контрольной группы.
freezer: приостанавливает или возобновляет задачи контрольной группы.
memory: устанавливает органичения и генерирует отчеты об использовании памяти задачами контрольной группы.
net_cls: присваивает сетевым пакетам идентификатор класса (classid), который позволяет контроллеру трафика tc отличать пакеты, поступающие из заданной контрольной группы.
net_prio: предоставляет способ динамически устанавливать значение сетевого приоритета в пакетах, отправляемых через разные сетевые интерфейсы.
ns: подсистема пространства имен.
Возможно, вы уже сталкивались с термином контроллер ресурса или просто контроллер в литературе по cgroups — в справочных страницах или документации по ядру. Оба термина являются синонимами термина «подсистема» и возникли потому, что подсистема обычно планирует порядок использования ресурса или накладывает ограничения на контрольные группы той иерархии, к которой она подключена.
Понятие подсистемы (контроллера ресурсов) является достаточно общим — это нечто, что воздействует на группу задач, т.е. процессов.
1.2. Соотношение между подсистемами, иерархиями, контрольными группами и задачами
Напомним, что системные процессы в терминологии контрольных групп называются задачами.
Ниже приведены несколько простых правил, устанавливающих соотношения между подсистемами, иерархиями контрольных групп и задачами.
Правило 1
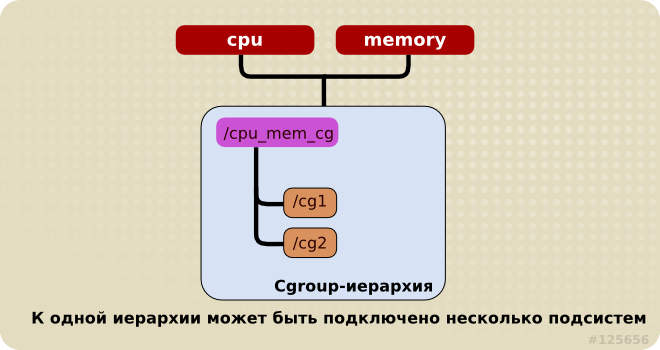
К одной иерархии может быть подключена одна или несколько подсистем.
Например, подсистемы cpu и memory (а также любое число других подсистем) могут быть подключены к одной иерархии, если каждая из них уже не подключена к какой-либо другой иерархии, к которой уже подключены другие подсистемы (см. правило 2).
Правило 2
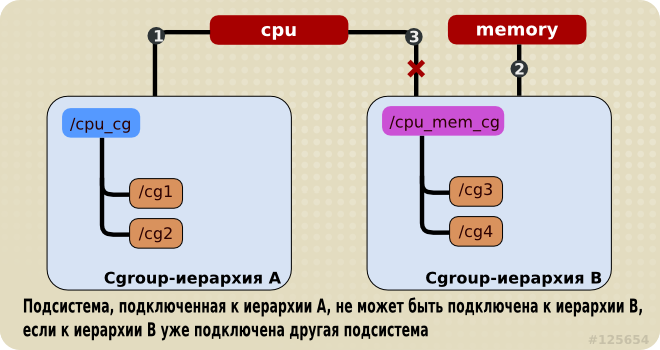
Любая подсистема (например, cpu) не может быть подключена к нескольким иерархиям, если хотя бы к одной из них уже подключена другая подсистема.
Таким образом, подсистема cpu не может быть подключена к двум иерархиям, если к одной из них уже подключена подсистема memory. Однако, одна и таже подсистема может быть подключена к двум иерархиям, если к обеим иерархиям подключена только эта подсистема.
Правило 3
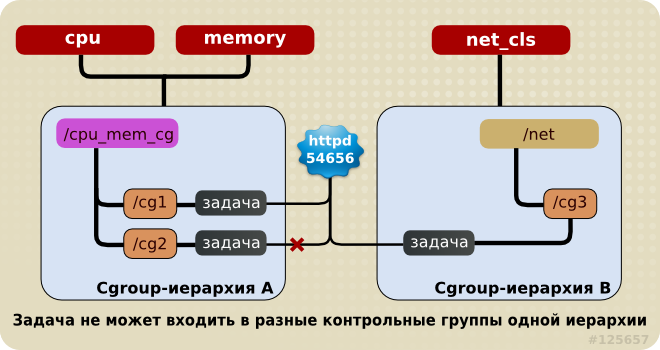
Каждый раз, когда в системе создается новая иерархия, все системные задачи вначале попадают в состав корневой контрольной группы данной иерархии. Каждая задача может принадлежать только одной группе в иерархии. Задача может принадлежать различным группам, если они расположены в разных иерархиях. Как только задача входит в состав новой группы из той же иерархии, она удаляется из исходной группы данной иерархии. Задача никогда не принадлежит двум контрольным группам одной иерархии.
Так, например, если подсистемы cpu и memory подключены к иерархии cpu_mem_cg, а подсистема net_cls подключена к иерархии net, то процесс httpd может принадлежать одной из контрольных групп в иерархии cpu_mem_cg и одной из контрольных групп в иерархии net.
Контрольная группа в иерархии cpu_mem_cg, к которой принадлежит процесс httpd, может ограничивать выделяемое ему процессорное время до половины того времени, которое выделяется другим процессам, а память — до 1024 МБ. Кроме того, контрольная группа в иерархии net, к которой тоже принадлежит процесс httpd, может ограничивать доступную ему скорость передачи данных до 30 МБ/с.
При создании первой иерархии все задачи системы принадлежат одной контрольной группе — корневой группе. В дальнейшем каждая задача всегда принадлежит хотя бы одной контрольной группе.
Правило 4
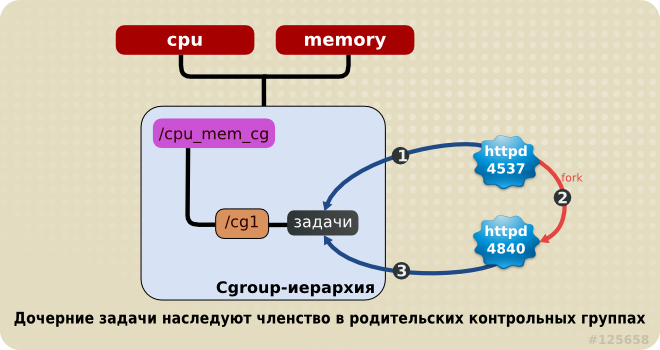
Если процесс Linux (задача cgroups) создает дочерний процесс (задачу), то дочерняя задача наследует членство во всех контрольных группах родительской задачи. Впоследствии дочерние задачи можно перенести в другие контрольные группы. Как только родительский процесс создал дочерний, они полностью независимы.
Рассмотрим, например, задачу httpd, принадлежащую контрольной группе half_cpu_1gb_max из иерархии cpu_mem_cg и контрольной группе trans_rate_30 из иерархии net. Когда процесс httpd порождает дочерний процесс, то он автоматически попадает в члены контрольных групп half_cpu_1gb_max и trans_rate_30. Дочерняя задача наследует членство в тех же самых контрольных группах, что и родительская задача.
Начиная с этого момента, родительская и дочерняя задача полностью независимы друг от друга: изменение членства в контрольных группах одной задачи не затрагивает другую. Изменения контрольных групп родительской задачи никоим образом не влияют на ее потомков. Таким образом, любая дочерняя задача первоначально наследует членство в контрольных группах родительской задачи, но впоследствии это членство может быть изменено или отменено.
1.3. Последствия для управления ресурсами
Так как задача может принадлежать лишь одной контрольной группе в иерархии, то каждая подсистема имеет возможность наложить на задачу лишь один набор ограничений или как-либо повлиять на задачу. Это логическое следствие, а не недостаток.
Несколько подсистем можно сгруппировать так, чтобы они влияли на все задачи в одной иерархии. Поскольку контрольные группы в данной иерархии имеют разный набор параметров, то эти задачи будут затронуты поразному.
Структура иерархии может меняться. Например, какая-то подсистема может быть отключена от одной иерархии с несколькими подсистемами и добавлена к новой, отдельной иерархии.
И наоборот, если необходимость в разделении подсистем по отдельным иерархиям отпала, то можно удалить одну иерархию и подключить ее подсистемы к другой.
Архитектура допускает простое использование механизма контрольных групп — например, установку нескольких параметров для отдельных задач в рамках одной иерархии, к которой подключены только подсистемы cpu и memory.
Архитектура также допускает создание очень точных настроек. Например, каждая задача (процесс) может быть членом всех иерархий, к каждой из которых подключена всего одна подсистема. Такая конфигурация предоставляет системному администратору полный контроль над всеми параметрами каждой отдельной задачи.
Глава 2. Работа с контрольными группами
Проще всего работать с контрольными группами с помощью утилит из пакета libcgroup-tools. В принципе, можно монтировать иерархии и устанавливать параметры контрольных групп в помощью обычных команд и утилит доступных в любой системе. Однако, использование утилит из пакет libcgroup-tools упрощает процесс и расширяет возможности. Поэтому в данном руководстве рассматриваются способы работы с использованием команд из libcgroup-tools. В большинстве случаев также приводятся эквивалентные команды оболочки, что должно помочь понять внутренний механизм работы. Тем не менее, мы рекомендуем использовать команды из пакета libcgroup-tools везде, где это возможно.
Перед началом работы с контрольными группами убедитесь, что на систему установлен пакет libcgroup-tools. Выполните следующую команду как пользователь root:
~]# yum install libcgroup-tools
Служба cgconfig устанавливатеся вместе с пакетом libcgroup-tools и рекомендуется для создания иерархий, подключения подсистем и управления контрольными группами.
В Fedora 17 служба cgconfig запускается по умолчанию. При загрузке системы или при перезапуске службы с помощью команды systemctl restart cgconfig.service она считывает файл /etc/cgconfig.conf, что позволяет ей воссоздавать конфигурацию контрольных групп, описанную в этом файле. В зависимости от содержания конфигурационного файла служба cgconfig может создавать иерархии, монтировать требуемые файловые системы, создавать контрольные группы и устанавливать параметры подсистем для каждой из них.
По умолчанию файл /etc/cgconfig.conf, поставляемый с пакетом libcgroup-tools, приводит к созданию и монтированию отдельных иерархий для каждой из подсистем, а затем к подключению каждой подсистемы к соответствующей иерархии.
При остановке службы cgconfig (с помощью команды systemctl stop cgconfig.service ) она отмонтирует все смонтированные ею иерархии.
2.1.1. Файл /etc/cgconfig.conf
Файл /etc/cgconfig.conf содержит два основных типа записей — mount и group. Записи mount указывают, какие иерархии должны быть созданы и смонтированы в качестве виртуальных файловых систем, и какие подсистемы должны быть к ним подключены. Используется следующая синтаксическая структура:
mount {
<подсистема> = <путь>;
…
}
Пример 2.1. Создание записи mount
Пример создания иерархии для подсистемы cpuset:
mount {
cpuset = /cgroup/red;
}
Та же конфигурация с помощью обычных команд:
~]# mkdir /cgroup/red
~]# mount -t cgroup -o cpuset red /cgroup/red
Записи типа group содержат определения контрольных групп и параметры подсистем. Они имеют следующую синтаксическую структуру:
group <имя> {
[<права>]
<подсистема> {
<параметр> = <значение>;
…
}
…
}
Секция права не является обязательной. Для указания прав доступа используется следующий синтаксис:
perm {
task {
uid = <пользователь>;
gid = <группа>;
}
admin {
uid = <администратор>;
gid = <административная группа>;
}
}
Пример 2.2. Создание записи group
Приведенный ниже пример показывает создание контрольной группы для SQL-демонов, задачи в которую могут добавлять пользователи из группы sqladmin, а изменять параметры подсистем может пользователь root.
group daemons/sql {
perm {
task {
uid = root;
gid = sqladmin;
} admin {
uid = root;
gid = root;
}
} cpu {
cpu.shares = 100;
}
}
~]# mkdir -p /cgroup/cpu/daemons/sql
~]# chown root:root /cgroup/cpu/daemons/sql/*
~]# chown root:sqladmin /cgroup/cpu/daemons/sql/tasks
~]# echo 100 > /cgroup/cpu/daemons/sql/cpu.shares
Необходимо перезапустить службу
cgconfig, чтобы изменения, внесенные в файл
/etc/cgconfig.conf, вступили в силу:
~]# systemctl restart cgconfig.service
При установке пакета libcgroup-tools создается файл /etc/cgconfig.conf. Знаки # в начале строки обозначают комментарии, которые игнорируются службой cgconfig.
2.2. Создание иерархии и подключение подсистем
Приведенные ниже инструкции, относящиеся к созданию новой иерархии и подключению к ней подсистем, подразумевают, что контрольные группы еще не настроены. В этом случае выполнение инструкций не повлияет на работу системы. Однако, изменение параметров контрольной группы может немедленно отразиться на входящих в нее задачах.
Если в системе уже настроены контрольные группы (вручную или с помощью службы cgconfig), то приведенные здесь команды могут не сработать. В этом случае вначале нужно отмонтировать существующие иерархии, что может повлиять на работу системы. Не рекомендуется экспериментировать с настройками на рабочих системах.
Для создания иерархии и подключения к ней подсистем добавьте записи в секцию mount в файле /etc/cgconfig.conf (в режиме root). Записи в секции mount имеют следующий формат:
подсистема = /cgroup/иерархия;
При следующем записке служба cgconfig создаст иерархию и подключит к ней подсистемы.
Приведенный ниже пример показывает создание иерархии cpu_and_mem и подключение к ней подсистем cpu, cpuset, cpuacct и memory.
mount {
cpuset = /cgroup/cpu_and_mem;
cpu = /cgroup/cpu_and_mem;
cpuacct = /cgroup/cpu_and_mem;
memory = /cgroup/cpu_and_mem;
}Альтернативный метод
Для создания иерархий и подключения подсистем можно использовать обычные команды и утилиты.
В режиме root создайте каталог с именем иерархии, который будет служить ее точкой монтирования:
~]# mkdir /cgroup/имя_иерархии
Например:
~]# mkdir /cgroup/cpu_and_mem
Затем, используя команду mount, смонтируйте иерархию и одновременно подключите к ней одну или несколько подсистем. Например:
~]# mount -t cgroup -o подсистемы имя_иерархии /cgroup/имя_иерархии
Пример 2.3. Подключение подсистем с помощью команды mount
В следующем примере в качестве точки монтирования новой иерархии будет использоваться уже существующий каталог /cgroup/cpu_and_mem. К иерархии cpu_and_mem будут подключены подсистемы cpu, cpuset и memory, а сама иерархия будет смонтирована в /cgroup/cpu_and_mem:
~]# mount -t cgroup -o cpu,cpuset,memory cpu_and_mem /cgroup/cpu_and_mem
Список всех доступных подсистем и их текущих точек монтирования (т.е. точек монтирования иерархий, к которым подключены соответствующие подсистемы) можно получить с помощью команды lssubsys[]:
~]# lssubsys -am
cpu,cpuset,memory /cgroup/cpu_and_mem
net_cls
ns
cpuacct
devices
freezer
blkio
Вывод команды показывает, что:
подсистемы cpu, cpuset и memory подключены к иерархии смонтированной в /cgroup/cpu_and_mem, и
подсистемы net_cls, ns, cpuacct, devices, freezer и blkio пока не подключены ни к какой иерархии, о чем свидетельствует отсутствие соответствующих точек монтирования.
2.3. Подключение и отключение подсистем от существующей иерархии
Альтернативный метод
Для того, чтобы добавить неподключенную подсистему к существующей иерархии, надо перемонтировать ее. В список опций команды mount нужно добавить опцию remount и название подсистемы.
Пример 2.4. Перемонтирование иерархии для добавления подсистемы
Вывод команды lssubsys показывает, что к иерархии cpu_and_mem подключены подсистемы cpu, cpuset и memory:
~]# lssubsys -am
cpu,cpuset,memory /cgroup/cpu_and_mem
net_cls
ns
cpuacct
devices
freezer
blkio
Перемонтируем иерархию cpu_and_mem с опцией remount и добавим cpuacct в список подсистем:
~]# mount -t cgroup -o remount,cpu,cpuset,cpuacct,memory cpu_and_mem /cgroup/cpu_and_mem
Вывод команды lssubsys теперь показывает, что подсистема cpuacct подключена к иерархии cpu_and_mem:
~]# lssubsys -am
cpu,cpuacct,cpuset,memory /cgroup/cpu_and_mem
net_cls
ns
devices
freezer
blkio
Аналогичным образом можно отключить подсистему от иерархии. Для этого нужно перемонтировать иерархию, опустив название подсистемы из списка параметров после опции -o. Например, отключить подсистему cpuacct можно так:
~]# mount -t cgroup -o remount,cpu,cpuset,memory cpu_and_mem /cgroup/cpu_and_mem
2.4. Отмонтирование иерархии
Для отмонтирования иерархии контрольных групп используется команда umount:
~]# umount /cgroup/имя_иерархии
Например:
~]# umount /cgroup/cpu_and_mem
Пустая иерархия (т.е. иерархия, содержащая только корневую контрольную группу) деактивируется после отмонтирования. Если же она содержит другие группы, то она остается активной на уровне ядра даже после отмонтирования на уровне файловой системы.
Перед отмонтированием иерархии надо либо убедиться, что все дочернии контрольные группы удалены, либо использовать команду
cgclear, которая способна деактивировать даже непустую иерархию (см.
Раздел 2.12, «Удаление контрольных групп»).
2.5. Создание контрольных групп
Для создания контрольных групп используется команда cgcreate. Синтаксис команды:
cgcreate -t uid:gid -a uid:gid -g подсистемы:путь
где
-t (необязательный) — определяет пользователя (uid) и группу (gid), которым будет принадлежать псевдофайл tasks создаваемой контрольной группы. Этот пользователь сможет добавлять задачи в контрольную группу.
Удалить задачу из контрольный группы можно только переместив ее в другую группу. При этом пользователь должен обладать правами записи в ту группу, куда перемещается задача, а правда записи в исходную группу не требуются.
-a (необязательный) — определяет пользователя (uid) и группу (gid), которым будут принадлежать все остальные псевдофайлы контрольной группы кроме псевдофайла tasks. Этот пользователь может изменять уровень доступа к системным ресурсам со стороны задач данной контрольной группы.
-g — определяет одну или несколько иерархий, в которых должна быть создана контрольная группа. Иерархии задаются как параметр подсистемы, в виде разделенного запятыми списка подсистем. Если входящие в список подсистемы подключены к разным иерархиям, то контрольная группа создается в каждой из них. Список завершается двоеточием, после которого следует путь к группе относительно вершины иерархии, причем точка монтирования иерархии не указывается.
Например, контрольная группа в каталоге
/cgroup/cpu_and_mem/lab1/ обозначается просто как
lab1. Путь к ней определяется однозначно, так как для заданной подсистемы существует только одна иерархия. Группа контролируется всеми подсистемами в иерархиях, где она создана, даже если некоторые подсистемы не перечислены явно в команде
cgcreate (см.
Пример 2.5, «Использование cgcreate»).
Поскольку все контрольные группы в иерархии имеют одни и те же контроллеры, то дочерние группы имеют те же контроллеры, что и родительские группы.
Пример 2.5. Использование cgcreate
Представим, что подсистемы cpu и memory вместе подключены к иерархии cpu_and_mem, а подсистема net_cls — к иерархии net. Выполним команду:
~]# cgcreate -g cpu,net_cls:/test-subgroup
Команда cgcreate создаст две группы с именем test-subgroup — одну в иерархии cpu_and_mem, а другую в иерархии net. Группа test-subgroup в иерархии cpu_and_mem будет контролироваться подсистемой memory, хотя она и не указана в команде cgcreate.
Альтернативный метод
Для создания дочерней контрольной группы можно использовать команду mkdir:
~]# mkdir /cgroup/иерархия/имя/новая_группа
Например:
~]# mkdir /cgroup/cpuset/lab1/group1
2.6. Удаление контрольных групп
Для удаления контрольных групп служит команда cgdelete. По синтаксису она похожа на команду cgcreate:
cgdelete подсистемы:путь
где
Например:
~]# cgdelete cpu,net_cls:/test-subgroup
Команда cgdelete с опцией -r осуществляет рекурсивное удаление всех подгрупп.
При удалении контрольной группы ее задачи перемещаются в родительскую группу.
2.7. Настройка параметров
Пользователь с правами модификации контрольной группы может менять параметры подсистем с помощью команды cgset. Например, если существует группа /cgroup/cpuset/group1, то чтобы разрешить ей доступ к заданым процессорам, следует выполнить команду:
cpuset]# cgset -r cpuset.cpus=0-1 group1
Команда cgset имеет следующий синтаксис:
cgset -r параметр=значение путь_к_контрольной_группе
где
параметр — устанавливаемый параметр, которому соответствует файл в каталоге контрольной группы;
значение — присваемое параметру значение;
путь — путь к контрольной группе от корня иерархии. Например, команда установки параметра в корневой группе (если существует файл /cgroup/cpuacct/) будет выглядеть так:
cpuacct]# cgset -r cpuacct.usage=0 /
Поскольку знак . указывает положение относительно корня иерархии (т.е. соответствует корневой группе), то команда может выглядеть так:
cpuacct]# cgset -r cpuacct.usage=0 .
Предпочтительнее использовать синтаксис со знаком /.
Только небольшое число параметров может быть установлено в корневой группе (например, приведенный выше параметр cpuacct.usage). Это объясняется тем, что корневой группе принадлежат все ресурсы, поэтому изменение настроек на этом уровне ограничит все существующие процессы, что нецелесообразно.
Следующая команда устанавливает параметр в контрольной группе group1, которая является подгруппой корневой группы:
cpuacct]# cgset -r cpuacct.usage=0 group1
Добавление знака косой черты после названия группы (cpuacct.usage=0 group1/) необязательно.
Значения параметров, которые можно устанавливать с помощью команды cgset, зависят от значений параметров на верхних уровнях иерархии. Например, если группе group1 доступен только процессор 0, то подгруппе group1/subgroup1 нельзя разрешить использовать процессоры 0 и 1 или только процессор 1.
С помощью команды cgset можно копировать параметры из одной контрольной группы в другую. Например:
~]# cgset --copy-from group1/ group2/
Синтаксис команды копирования:
cgset --copy-from откуда куда
где
откуда — путь к исходной контрольной группе, чьи параметры должны быть скопированы, указанный относительно корневой группы иерархии;
куда — путь к контрольной группе, куда должны быть скопированы параметры, указанный относительно корневой группы иерархии.
Прежде чем приступать к копированию, необходимо убедиться, что все обязательные параметры подсистем установлены. В противном случае, команда копирования не сработает (см.
Обязательные параметры).
Альтернативный метод
Установить параметры контрольной группы можно напрямую, указав значения параметров как вывод команды echo и перенаправив его в псевдофайл соответствующей подсистемы. Ниже приведен пример установки значения 0-1 в псевдофайле cpuset.cpus контрольной группы group1:
~]# echo 0-1 > /cgroup/cpuset/group1/cpuset.cpus
При установке таких значений задачам этой контрольной группы будет разрешено использовать только процессоры 0 и 1.
2.8. Перенос процесса в контрольную группу
Процесс можно перенести в контрольную группу командой cgclassify:
~]# cgclassify -g cpu,memory:group1 1701
Синтаксис команды cgclassify:
cgclassify -g подсистемы:путь процессы
где
подсистемы — разделенный запятыми список подсистем или символ *, означающий, что процессы следует запустить во всех иерархиях, связанных со всеми доступными подсистемами. Если в нескольких иерархиях существуют контрольные группы с тем же именем, то при использовании опции -g процессы будут помещены во все эти группы. Следует убедиться, что указанная контрольная группа существует во всех иерархиях, чьи подсистемы перечислены в команде;
путь — путь к контрольной группе внутри иерархии;
процессы — разделенный пробелами список идентификаторов процессов.
Кроме этого, если перед списком параметров процессы добавить опцию --sticky, то все дочерние процессы будут оставаться в той же контрольной группе. Если эта опция не используется, но при этом работает служба cgred, то дочерние процессы будут перераспределены в контрольные группы в соответствии с правилами, указанными в файле /etc/cgrules.conf. Родительский процесс, тем не менее, будет оставаться в первоначально указанной контрольной группе.
С помощью команды cgclassify можно сразу переместить несколько процессов. Например, следующая команда переместит процессы 1701 и 1138 в контрольную группу group1/:
~]# cgclassify -g cpu,memory:group1 1701 1138
Отметим, что список идентификаторов процессов разделяется пробелами, и что указанные группы должны находиться в разных иерархиях.
Альтернативный метод
Чтобы напрямую переместить процесс в контрольную группу, нужно записать его идентификатор в файл tasks этой группы. Например, чтобы переместить процесс 1701 в контрольную группу /cgroup/lab1/group1/:
~]# echo 1701 > /cgroup/lab1/group1/tasks
Служба cgred, запускающая демон cgrulesengd, отвечает за перемещение задач в контрольные группы в соответствии с параметрами, заданными в файле /etc/cgrules.conf. Записи в файле /etc/cgrules.conf имеют одну из двух форм:
Например:
maria devices /usergroup/staff
Эта запись показывает, что все процессы, принадлежащие пользователю maria, имеют доступ к подсистеме devices в соответствии с параметрами, установленными в контрольной группе /usergroup/staff. Чтобы сопоставить отдельные команды контрольным группам, нужно указать их после имени пользователя:
maria:ftp devices /usergroup/staff/ftp
Теперь, если пользователь maria запускает команду ftp, то соответствующий процесс будет автоматически помещен в контрольную группу /usergroup/staff/ftp в иерархии, содержащей подсистему devices. Стоит отметить, что перенос процесса осуществляется только после выполнения заданного условия. Поэтому, процесс ftp какое-то короткое время может исполняться в не той группе. Более того, если процесс быстро порождает потомков, пока он еще находится не в той группе, то нет гарантии, что потомки будут корректно перемещены.
Записи в файле /etc/cgrules.conf могут включать следующие дополнительные обозначения:
@ перед именем пользователя обозначает не отдельного пользователя, а группу. Например, значение @admins включает всех пользователей в группе admins.
* обозначает "все". Так, знак * в поле подсистема обозначает все подсистемы.
% копирует элемент из предыдущей строки. Например:
@adminstaff devices /admingroup
@labstaff % %
2.9. Запуск процесса в контрольной группе
Некоторые подсистемы имеют обязательные параметры, которые должны быть установлены до того, как задачу можно будет переместить в контрольную группу, использующую любую из этих подсистем. Например, прежде, чем перемещать задачу в контрольную группу, использующую подсистему cpuset, необходимо определить значения cpuset.cpus и cpuset.mems.
Приведенные в этой секции примеры показывают правильный синтаксис команд, но будут работать только при условии, что заданы обязательные параметры используемых контроллеров. Если контроллеры еще не настроены, то приведенные примеры работать не будут.
Для запуска процессов в контрольной группе используется команда cgexec. Ниже приведен пример запуска браузера lynx в пределах группы group1, на которую накладываются ограничения подсистемой cpu:
~]# cgexec -g cpu:group1 lynx http://www.redhat.com
Команда cgexec имеет следующий синтаксис:
cgexec -g подсистемы:путь команда аргументы
где
подсистемы — разделенный запятыми список подсистем или символ
*, означающий, что процесс следует запустить во всех иерархиях, связанных со всеми доступными подсистемами. Так же, как и в случае команды
cgset (см.
Раздел 2.7, «Настройка параметров»), если в нескольких иерархиях существуют контрольные группы с тем же именем, то при использовании опции
-g процесс будет помещен в каждую из них. Следует убедиться, что указанная контрольная группа существуют во всех иерархиях, чьи подсистемы перечислены в команде;
путь — путь к контрольной группе от вершины иерархии;
команда — команда, которая должна быть запущена;
аргументы — любые аргументы команды.
Кроме этого, если перед параметром процессы добавить опцию --sticky, то все дочерние процессы будут оставаться в той же контрольной группе. Если эта опция не используется, но при этом работает служба cgred, то дочерние процессы будут перераспределены в контрольные группы в соответствии с правилами, указанными в файле /etc/cgrules.conf. Родительский процесс, тем не менее, будет оставаться в той контрольной группе, где он был изначально запущен.
Альтернативный метод
Новый процесс наследует контрольную группу родительского процесса. Поэтому, чтобы запустить процесс в выбранной контрольной группе, вначале можно перенести в эту группу процесс интерпретатора команд (см.
Раздел 2.8, «Перенос процесса в контрольную группу») и уже затем запустить процесс из под интерпретатора. Например:
~]# echo $$ > /cgroup/lab1/group1/tasks
lynx
Отметим, что даже после окончания работы lynx интерпретатор команд остается в контрольной группе group1. Поэтому еще лучше следующий способ:
~]# sh -c "echo \$$ > /cgroup/lab1/group1/tasks && lynx"
2.9.1. Запуск службы в контрольной группе
Можно сконфигурировать некоторые службы так, чтобы они запускались в контрольной группе. Службы, которые пока не перешли на использование конфигурационных файлов systemd, должны удовлетворять следующим условиям:
Чтобы сделать так, что удовлетворяющая условиям служба запускалась в контрольной группе, надо добавить запись CGROUP_DAEMON="подсистема:группа" в ее конфигурационный файл в каталоге /etc/sysconfig. Параметр подсистема — это подсистема, подключенная к какой-либо иерархии, а параметр группа — это контрольная группа в этой иерархии. Например:
CGROUP_DAEMON="cpuset:daemons/sql"
2.9.2. Поведение процесса в корневой контрольной группе
Некоторые параметры подсистем blkio и cpu иначе влияют на процессы (задачи), работающие в корневой контрольной группе, нежели на процессы в подгруппах. Рассмотрим следующий пример:
Две подгруппы созданы под одной корневой группой: /rootgroup/red/ и /rootgroup/blue/
В каждой подгруппе и в корневой группе определен параметр cpu.shares, и ему присвоено значение 1.
Если при таких условиях поместить по одному процессу в каждую группу (т.е. иметь по одной задаче в /rootgroup/tasks, /rootgroup/red/tasks и /rootgroup/blue/tasks), то каждый процесс будет потреблять по 33.33% времени центрального процессора:
Процесс в /rootgroup/: 33.33%
Процесс в /rootgroup/blue/: 33.33%
Процесс в /rootgroup/red/: 33.33%
Если в подгруппы blue и red поместить другие процессы, то они будут делить между собой те 33.33% времени центрального процессора, которые были выделены каждой подгруппе.
Однако, если поместить несколько процессов в корневую группу, то ресурсы центрального процессора будут делиться по процессами, а не по группам. Например, если в корневой группе /rootgroup/ находится три процесса, а в подгруппах /rootgroup/red/ и /rootgroup/blue/ — по одному, и параметр cpu.shares имеет значение 1 во всех группах, то ресурсы процессора поделятся следующим образом:
Процессы в /rootgroup/: 20% + 20% + 20%
Процессы в /rootgroup/blue/: 20%
Процессы в /rootgroup/red/: 20%
Поэтому при использовании подсистем blkio и cpu рекомендуется переместить все процессы из корневой группы в подгруппы, где потребление ресурсов можно регулировать с помощью весовых коэффициентов или процентных долей (например, cpu.shares или blkio.weight). Перемещение всех задач из корневой группы в одну из подгрупп, можно выполнить так:
rootgroup]# cat tasks >> red/tasks
rootgroup]# echo > tasks
2.10. Создание файла /etc/cgconfig.conf
Конфигурация для файла
/etc/cgconfig.conf может быть сгенерирована из текущей конфигурации контрольных групп с использованием утилиты
cgsnapshot. Эта утилита фиксирует текущее состояние всех подсистем и контрольных групп и возвращает результат в таком виде, который можно использовать в файле
/etc/cgconfig.conf.
Пример 2.6, «Использование утилиты cgsnapshot» показывает пример использования утилиты
cgsnapshot.
Пример 2.6. Использование утилиты cgsnapshot
Создадим конфигурацию контрольных групп с помощью следующих команд:
~]# mkdir /cgroup/cpu
~]# mount -t cgroup -o cpu cpu /cgroup/cpu
~]# mkdir /cgroup/cpu/lab1
~]# mkdir /cgroup/cpu/lab2
~]# echo 2 > /cgroup/cpu/lab1/cpu.shares
~]# echo 3 > /cgroup/cpu/lab2/cpu.shares
~]# echo 5000000 > /cgroup/cpu/lab1/cpu.rt_period_us
~]# echo 4000000 > /cgroup/cpu/lab1/cpu.rt_runtime_us
~]# mkdir /cgroup/cpuacct
~]# mount -t cgroup -o cpuacct cpuacct /cgroup/cpuacct
Приведенные выше команды подключают две подсистемы и создают две контрольных группы для подсистемы cpu со специфическими значениями для некоторых ее параметров. Выполнив команду cgsnapshot (с опцией -s и пустым файлом /etc/cgsnapshot_blacklist.conf[]), получим следующий вывод:
~]$ cgsnapshot -s
# Configuration file generated by cgsnapshot
mount {
cpu = /cgroup/cpu;
cpuacct = /cgroup/cpuacct;
}
group lab2 {
cpu {
cpu.rt_period_us="1000000";
cpu.rt_runtime_us="0";
cpu.shares="3";
}
}
group lab1 {
cpu {
cpu.rt_period_us="5000000";
cpu.rt_runtime_us="4000000";
cpu.shares="2";
}
}
По умолчанию утилита cgsnapshot направляет результат в стандартный вывод. Используя опцию -f, можно перенаправить вывод в файл. Например:
~]$ cgsnapshot -f ~/test/cgconfig_test.conf
При использовании опции -f вывод утилиты cgsnapshot перезаписывает содержимое указанного файла. Поэтому, не рекомендуется направлять вывод прямо в файл /etc/cgconfig.conf.
Утилита cgsnapshot может создавать конфигурационные файлы для отдельных подсистем. Если указать имя подсистемы в качестве параметра команды, то вывод будет содержать только конфигурационные параметры данной подсистемы:
~]$ cgsnapshot cpuacct
# Configuration file generated by cgsnapshot
mount {
cpuacct = /cgroup/cpuacct;
}
2.10.1. Занасение параметров в черный список
Утилита cgsnapshot позволяет заносить параметры в черный список. Если параметр занесен в черный список, то он не попадает в вывод, генерируемый утилитой cgsnapshot. По умолчанию каждый параметр проверяется на наличие в черном списке в файле /etc/cgsnapshot_blacklist.conf. Если параметр не указан в черном списке, то проверяется белый список. Чтобы указать другой черный список, используется опция -b. Например:
~]$ cgsnapshot -b ~/test/my_blacklist.conf
2.10.2. Занесение параметров в белый список
Дополнительно утилита cgsnapshot позволяет заносить параметры в белый список. Если параметр занесен в белый список, то он появляется в выводе, генерируемом утилитой cgsnapshot. Если параметра нет ни в черном, ни в белом списках, то появляется предупреждение:
~]$ cgsnapshot -f ~/test/cgconfig_test.conf
WARNING: variable cpu.rt_period_us is neither blacklisted nor whitelisted
WARNING: variable cpu.rt_runtime_us is neither blacklisted nor whitelisted
По умолчанию файл с белым списком отсутствует. Для указания файла с белым списком используется опция -w. Например:
~]$ cgsnapshot -w ~/test/my_whitelist.conf
Указание опции -t заставляет утилиту cgsnapshot генерировать конфигурацию с параметрами только из белого списка.
2.12. Удаление контрольных групп
Команда cgclear удаляет все контрольные группы во всех иерархиях. Если структура иерархий не сохранена в конфигурационном файле, то восстановить ее будет непросто.
Команда cgclear служит для очистки всей файловой системы контрольных групп.
Все задачи контрольных групп перемещаются в корневой узел иерархии, все контрольные группы удаляются, файловая система контрольных групп отмонтируется, и, таким образом, удаляются все смонтированные ранее иерархии. Наконец, сам каталог, куда была смонтирована файловая система контрольных групп, тоже удаляется.
Если контрольные группы создаются с помощью команды mount (а не с помощью службы cgconfig), то об этом остаются записи в файле /etc/mtab (в таблице смонтированных файловых систем). Факт монтирования также отражается в файле /proc/mounts. Однако, при удалении контрольных групп с помощью команды cgclear, а также при использовании других команд cgconfig, задействуется прямой интерфейс с ядром, который вносит изменения в файл /proc/mounts, но не изменяет файл /etc/mtab. Поэтому, после удаления контрольных групп командой cgclear, отмонтированные контрольные группы могут быть все еще видны в файле /etc/mtab и, следовательно, будут показываться командой mount. Для получения точного списка всех смонтированных контрольных групп нужно использовать данные из файла /proc/mounts.
2.13. Дополнительные ресурсы
Информацию о командах управления контрольными группами можно найти на справочных страницах, включенных в пакет libcgroup-tools. В приведенном ниже списке указаны номера секций, к которым относятся справочные страницы.
Справочные страницы libcgroup-tools
man 1 cgclassify — команда cgclassify осуществляет перемещение задач между контрольными группами.
man 1 cgclear — команда cgclear удаляет все контрольные группы в иерархии.
man 5 cgconfig.conf — конфигурация контрольных групп определяется в файле cgconfig.conf.
man 8 cgconfigparser — команда cgconfigparser осуществляет разбор файла cgconfig.conf и монтирует иерархии.
man 1 cgcreate — команда cgcreate создает в иерархиях новые контрольные группы.
man 1 cgdelete — команда cgdelete удаляет указанные контрольные группы.
man 1 cgexec — команда cgexec запускает задачи в указанных контрольных группах.
man 1 cgget — команда cgget показывает значения параметров контрольных групп.
man 1 cgsnapshot — команда cgsnapshot генерирует конфигурационный файл на основании текущего состояния подсистем.
man 5 cgred.conf — файл cgred.conf содержит конфигурацию для службы cgred.
man 5 cgrules.conf — файл cgrules.conf содержит правила, определяющие принадлежность задач к некоторым контрольным группам.
man 8 cgrulesengd — служба cgrulesengd распределяет задачи по контрольным группам.
man 1 cgset — команда cgset устанавливает значения параметров контрольных групп.
man 1 lscgroup — команда lscgroup показывает список контрольных групп в иерархии.
man 1 lssubsys — команда lssubsys показывает список иерархий, к которым подключены указанные подсистемы.
Глава 3. Подсистемы и параметры настройки
Подсистемы — это модули ядра с поддержкой механизма контрольных групп. Обычно они являются контроллерами ресурсов, то есть распределяют ресурсы между контрольными группами. Однако, подсистемы могут быть разработаны и для выполнения других функций. Например, в тех случаях, когда желательно влиять на поведение ядра и обращаться с какими-то группами процессов особым образом.
Прикладной программный интерфейс (API, Application Programming Interface) для разработки новых подсистем описан в файле
cgroups.txt в документации по ядру операционной системы. Этот файл поставляется в составе пакета
kernel-doc и находится в каталоге
/usr/share/doc/kernel-doc-kernel-version/Documentation/cgroups/. Последняя версия документации по контрольным группам доступна по адресу
http://www.kernel.org/doc/Documentation/cgroups/cgroups.txt. Следует учитывать, что возможности, описанные в последней версии документации, могут отличаться от возможностей контрольных групп, поддерживаемых установленным в системе ядром.
Объекты состояния, содержащие параметры подсистем контрольной группы, представлены в виде псевдофайлов в виртуальной файловой системе контрольных групп. Проводить операции с псевдофайлами можно с помощью команд оболочки или эквивалентных системных вызовов. Например, cpuset.cpus — это псевдофайл, в котором указываются номера процессоров доступных контрольной группе. Если /cgroup/cpuset/webserver — это контрольная группа для web-сервера, то можно выполнить следующую команду:
~]# echo 0,2 > /cgroup/cpuset/webserver/cpuset.cpus
Значение 0,2, записанное в псевдофайл cpuset.cpus, разрешит всем процессам, чьи идентификаторы перечислены в /cgroup/cpuset/webserver/tasks, использовать только процессоры 0 и 2.
Подсистема блочного ввода-вывода (blkio) управляет доступом задач контрольных групп к вводу-выводу на блочные устройства. Запись значений в некоторые из ее псевдофайлов ограничивает доступ или скорость доступа к устройствам, а чтение этих псевдофайлов предоставляет информацию об операциях ввода-вывода.
Подсистема blkio предоставляет два способа для управления доступом к вводу-выводу:
Распределение ресурсов пропорционально весу — этот способ, реализованный в CFQ-планировщике
[] ввода-вывода, позволяет назначать контрольным группам весовые коэффициенты. Таким образом, за каждой контрольной группой резервируется какой-то процент от всех операций ввода-вывода пропорциональный весовому коэффициенту группы (см.
Раздел 3.1.1, «Опции для распределении ресурсов пропорционально весу»).
Торможение ввода-вывода (установка верхнего предела) — этот способ устанавливает верхний предел числа опареций ввода-вывода, выполняемых некоторым устройством. Это означает, что подсистема
blkio ограничивает количество операций
read и
write, направляемых на исполнение драйверу устройства за единицу времени (см.
Раздел 3.1.2, «Опции для торможения ввода-вывода»).
В настоящее время подсистема blkio не работает для операций записи с буферизацией. Главным образом она ориентирована на прямой ввод-вывод, хотя и работает для буферизованных операций чтения.
3.1.1. Опции для распределении ресурсов пропорционально весу
- blkio.weight
Определяет относительную долю (вес в диапазоне от 100 до 1000), используемую по умолчанию при планировании доступа контрольной группы к блочным устройствам ввода-вывода. Значение для отдельных устройств может быть переопределено параметром blkio.weight_device. Пример присвоения значения 500 в качестве веса контрольной группы при доступе к блочным устройствам:
echo 500 > blkio.weight
- blkio.weight_device
Определяет относительную долю (
вес в диапазоне от
100 до
1000), используемую при планировании доступа к вводу-выводу на указанное блочное устройство со стороны контрольной группы. Этот параметр имеет приоритет над параметром
blkio.weight. Значения параметра задаются в следующем формате:
старший_номер:
младший_номер вес. Номера типов устройств представлены в
списке устройств Linux —
http://www.kernel.org/doc/Documentation/devices.txt. Например, чтобы присвоить контрольной группе вес
500 при доступе к устройству
/dev/sda, надо выполнить:
echo 8:0 500 > blkio.weight_device
В списке устройств значение 8:0 соответствует /dev/sda.
- blkio.time
Возвращает продолжительность времени, в течение которого контрольная группа пользовалась доступом к вводу-выводу перечисленных устройств. Каждая запись содержит три поля: старший_номер, младший_номер и время. Номера типов устройств определены в списке устройств Linux, а время указывается в миллисекундах.
- blkio.sectors
Возвращает число секторов, переданных контрольной группой через перечисленные устройства. Каждая запись состоит из трех полей: старший_номер, младший_номер и число_секторов. Номера типов устройств определены в списке устройств Linux, а число_секторов — это число записанных и прочитанных секторов диска.
- blkio.io_serviced
На основании данных CFQ-планировщика возвращает число операций ввода-вывода, выполненных контрольной группой на перечисленных устройствах. Каждая запись состоит из четырех полей: старший_номер, младший_номер, тип_операции и число. Номера типов устройств определены в списке устройств Linux, тип_операции — это один из типов: Read — чтение, Write — запись, Sync — операции синхронного ввода-вывода, Async — операции асинхронного ввода-вывода, Total — все операции, число — число операций, соответствующего типа.
- blkio.io_service_bytes
На основании данных CFQ-планировщика возвращает число байт, переданных контрольной группой через перечисленные устройства. Каждая запись состоит из четырех полей: старший_номер, младший_номер, тип_операции и число_байт. Номера типов устройств определены в списке устройств Linux, тип_операции — это один из типов: Read — чтение, Write — запись, Sync — операции синхронного ввода-вывода, Async — операции асинхронного ввода-вывода, Total — все операции, число_байт — число переданных байтов, соответствующего типа.
- blkio.io_service_time
На основании данных CFQ-планировщика возвращает для каждого устройства продолжительность времени, затраченного на выполнение операций ввода-вывода, инициированных котрольной группой, начиная с момента диспетчиризации запроса до его завершения. Каждая запись состоит из четырех полей: старший_номер, младший_номер, тип_операции и время. Номера типов устройств определены в списке устройств Linux, тип_операции — это один из типов: Read — чтение, Write — запись, Sync — операции синхронного ввода-вывода, Async — операции асинхронного ввода-вывода, Total — все операции, время — продолжительность времени в наносекундах. Время указывается в наносекундах, а не в более крупных единицах, так как это позволяет предоставлять полезную информацию даже для быстрых устройств, таких как SSD-диски.
- blkio.io_wait_time
Возвращает совокупное время, проведенное в очередях планировщика операциями ввода-вывода, которые были инициированы контрольной группой. При интерпретации результатов следует учитывать следующее:
Показываемое время может превышать время, проведенное контрольной группой в состоянии ожидания завершения операций ввода-вывода, так как возвращаемое значение представляет собой сумму времен ожидания всех операций ввода-вывода контрольной группы. Время ожидания самой контрольной группы представлено параметром blkio.group_wait_time.
Если драйвер устройства поддерживает очередь запросов ввода-вывода длинной queue_depth > 1, то возвращаемое значение времени включает в себя только время, затрачиваемое на диспетчеризацию запросов, и не включает время ожидания обслуживания устройством.
Каждая запись состоит из четырех полей: старший_номер, младший_номер, тип_операции и время. Номера типов устройств определены в списке устройств Linux, тип_операции — это один из типов: Read — чтение, Write — запись, Sync — операции синхронного ввода-вывода, Async — операции асинхронного ввода-вывода, Total — все операции, время — продолжительность времени в наносекундах. Время указывается в наносекундах, а не в более крупных единицах, так как это позволяет предоставлять полезную информацию даже для быстрых устройств, таких как SSD-диски.
- blkio.io_merged
Возвращает число выполненных слияний запросов ввода-вывода среди всех запросов, инициированных контрольной группой. Каждая запись состоит из четырех полей: старший_номер, младший_номер, тип_операции и число. Номера типов устройств определены в списке устройств Linux, тип_операции — это один из типов: Read — чтение, Write — запись, Sync — операции синхронного ввода-вывода, Async — операции асинхронного ввода-вывода, Total — все операции, число — число запросов ввода-вывода каждого типа, для которых было выполнено слияние.
- blkio.io_queued
Возвращает число запросов ввода-вывода, инициированных контрольной группой, которые были поставлены в очередь. Каждая запись состоит из четырех полей: старший_номер, младший_номер, тип_операции и число. Номера типов устройств определены в списке устройств Linux, тип_операции — это один из типов: Read — чтение, Write — запись, Sync — операции синхронного ввода-вывода, Async — операции асинхронного ввода-вывода, Total — все операции, число — число запросов ввода-вывода каждого типа, поставленных в очередь.
- blkio.avg_queue_size
Возвращает среднюю длину очереди запросов ввода-вывода контрольной группы за все время ее существования. Длина очереди замеряется каждый раз, когда система выделяет фрагмент времени на ее обработку. Данный параметр доступен только тогда, когда ядро системы скомпилировано с опцией CONFIG_DEBUG_BLK_CGROUP=y. В ядре, поставляемом с Fedora 17, эта опция не установлена.
- blkio.group_wait_time
Возвращает общее время (в наносекундах), в течение которого контрольная группа ожидает предоставления фрагмента времени на обработку одной из своих очередей. Значение обновляется каждый раз, когда система выделяет фрагмент времени на обработку очереди контрольной группы. Таким образом, во время считывания значения из псевдофайла, соответствующего данному параметру, в нем не отражается время ожидания для операций ввода-вывода, которые в данный момент находятся в очереди. Данный параметр доступен только тогда, когда ядро системы скомпилировано с опцией CONFIG_DEBUG_BLK_CGROUP=y. В ядре, поставляемом с Fedora 17, эта опция не установлена.
- blkio.empty_time
Возвращает общее время (в наносекундах), в течение которого контрольная группа не имеет запросов ввода-вывода в состоянии ожидания. Значение обновляется каждый раз, когда в очереди данной контрольной группы появляется запрос в состоянии ожидания. Таким образом, если во время считывания значения из псевдофайла, соответствующего данному параметру, контрольная группа не имеет запросов в состоянии ожидания, то в считанном значении не будет отражена текущая продолжительность времени нахождения контрольной группой в этом состоянии. Данный параметр доступен только тогда, когда ядро системы скомпилировано с опцией CONFIG_DEBUG_BLK_CGROUP=y. В ядре, поставляемом с Fedora 17, эта опция не установлена.
- blkio.idle_time
Возвращает общее время (в наносекундах), которое планировщик проводит в ожидании более подходящего запроса ввода-вывода по сравнению с уже имеющимися запросами от данной контрольной группы или других групп. Значение обновляется каждый раз, когда планировщик прекращает свое ожидание. Таким образом, если считывать псевдофайл пока планировщик находится в ожидании, то в считанном значении не будет отражена текущая продолжительность времени нахождения планировщиком в этом состоянии. Данный параметр доступен только тогда, когда ядро системы скомпилировано с опцией CONFIG_DEBUG_BLK_CGROUP=y. В ядре, поставляемом с Fedora 17, эта опция не установлена.
- blkio.dequeue
Возвращает число запросов ввода-вывода, инициированных контрольной группой, которые были удалены из очереди устройством. Каждая запись состоит из трех полей: старший_номер, младший_номер и число. Номера типов устройств определены в списке устройств Linux, а число — это число запросов ввода-вывода, удаленных из очереди. Данный параметр доступен только тогда, когда ядро системы скомпилировано с опцией CONFIG_DEBUG_BLK_CGROUP=y. В ядре, поставляемом с Fedora 17, эта опция не установлена.
3.1.2. Опции для торможения ввода-вывода
- blkio.throttle.read_bps_device
Определяет верхний предел числа операций чтения, которые устройство может выполнять. Темп операций чтения указывается в байтах в секунду. Каждая запись состоит из трех полей: старший_номер, младший_номер и число_байт_в_сек. Номера типов устройств определены в списке устройств Linux, а число_байт_в_сек — это верхний предел темпа выполнения операций чтения. Например, ограничить скорость чтения с устройства /dev/sda до 10МБ/с можно так:
~]# echo "8:0 10485760" > /cgroups/blkio/test/blkio.throttle.read_bps_device
- blkio.throttle.read_iops_device
Определяет верхний предел числа операций чтения, которые устройство может выполнять. Темп чтения указывается в числе операций в секунду. Каждая запись состоит из трех полей: старший_номер, младший_номер и число_операций_в_сек. Номера типов устройств определены в списке устройств Linux, а число_операций_в_сек — это верхний предел разрешенного темпа выполнения операций чтения. Например, ограничить скорость чтения с устройства /dev/sda до 10 операций в секунду можно так:
~]# echo "8:0 10" > /cgroups/blkio/test/blkio.throttle.read_iops_device
- blkio.throttle.write_bps_device
Определяет верхний предел числа операций записи, которые устройство может выполнять. Темп операций заприси указывается в байтах в секунду. Каждая запись состоит из трех полей: старший_номер, младший_номер и число_байт_в_сек. Номера типов устройств определены в списке устройств Linux, а число_байт_в_сек — это верхний предел темпа выполнения операций записи. Например, ограничить скорость записи на устройство /dev/sda до 10МБ/с можно так:
~]# echo "8:0 10485760" > /cgroups/blkio/test/blkio.throttle.write_bps_device
- blkio.throttle.write_iops_device
Определяет верхний предел числа операций записи, которые устройство может выполнять. Темп записи указывается в числе операций в секунду. Каждая запись состоит из трех полей: старший_номер, младший_номер и число_операций_в_сек. Номера типов устройств определены в списке устройств Linux, а число_операций_в_сек — это верхний предел разрешенного темпа выполнения операций записи. Например, ограничить скорость записи на устройство /dev/sda до 10 операций в секунду можно так:
~]# echo "8:0 10" > /cgroups/blkio/test/blkio.throttle.write_iops_device
- blkio.throttle.io_serviced
На основании данных, собираемых механизмом торможения, возвращает число операций ввода-вывода, инициированных контрольной группой и выполненных перечисленными устройствами. Каждая запись состоит из четырех полей: старший_номер, младший_номер, тип_операции и число. Номера типов устройств определены в списке устройств Linux, тип_операции — это один из типов: Read — чтение, Write — запись, Sync — операции синхронного ввода-вывода, Async — операции асинхронного ввода-вывода, Total — все операции, число — число выполненных операций ввода-вывода.
- blkio.throttle.io_service_bytes
Возвращает число байт, переданных контрольной группой через перечисленные устройства. Единственное отличие между blkio.io_service_bytes и blkio.throttle.io_service_bytes состоит в том, что последний параметр не обновляется каждый раз, когда CFQ-планировщик выполняет операции над очередью запросов ввода-вывода. Каждая запись состоит из четырех полей: старший_номер, младший_номер, тип_операции и число_байт. Номера типов устройств определены в списке устройств Linux, тип_операции — это один из типов: Read — чтение, Write — запись, Sync — операции синхронного ввода-вывода, Async — операции асинхронного ввода-вывода, Total — все операции, число_байт — число переданных байтов, соответствующего типа.
3.1.3. Общие конфигурационные опции
- blkio.reset_stats
Сбрасывает статистику, представленную в других псевдофайлах. Запись целого числа в этот файл приводит к сбросу статистики работы контрольной группы.
3.1.4. Пример использования
Пример 3.1. Распределение ресурсов подсистемой blkio пропорционально весовому коэффициенту
Подключим подсистему blkio:
~]# mount -t cgroup -o blkio blkio /cgroup/blkio/
Создадим две контрольных группы для подсистемы blkio:
~]# mkdir /cgroup/blkio/test1/
~]# mkdir /cgroup/blkio/test2/
Установим весовые коэффициенты подсистемы blkio в созданных контрольных группах:
~]# echo 1000 > /cgroup/blkio/test1/blkio.weight
~]# echo 500 > /cgroup/blkio/test2/blkio.weight
Создадим два файла:
~]# dd if=/dev/zero of=file_1 bs=1M count=4000
~]# dd if=/dev/zero of=file_2 bs=1M count=4000
Приведенные выше команды создают два файла (file_1 и file_2) размером 4 ГБ.
В каждой из тестовых контрольных групп выполним команды dd применительно к одному из больших файлов (каждая команда читает содержимое файла и выводит его в устройство /dev/null):
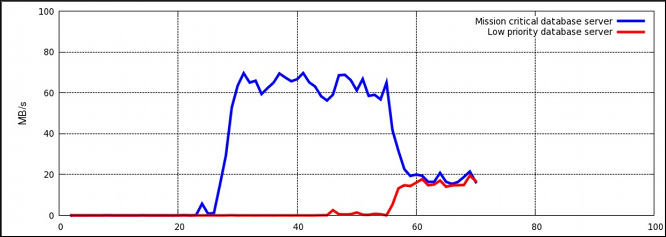
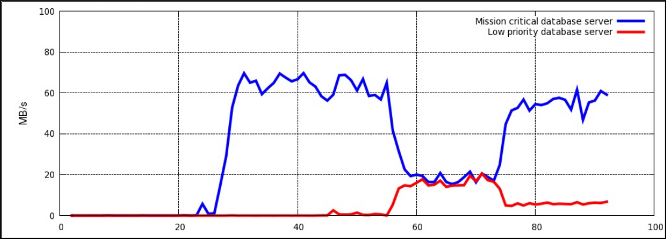
~]# cgexec -g blkio:test1 time dd if=file_1 of=/dev/null
~]# cgexec -g blkio:test2 time dd if=file_2 of=/dev/null
По окончании работы обе команды выводят время своего исполнения.
Скорость ввода-вывода двух процессов dd можно отслеживать с помощью утилиты iotop. Для ее установки надо выполнить в режиме root команду yum install iotop. Ниже приведен пример того, как может выглядеть вывод утилиты iotop во время работы процессов dd:
Total DISK READ: 83.16 M/s | Total DISK WRITE: 0.00 B/s
TIME TID PRIO USER DISK READ DISK WRITE SWAPIN IO COMMAND
15:18:04 15071 be/4 root 27.64 M/s 0.00 B/s 0.00 % 92.30 % dd if=file_2 of=/dev/null
15:18:04 15069 be/4 root 55.52 M/s 0.00 B/s 0.00 % 88.48 % dd if=file_1 of=/dev/null
~]# sync
~]# echo 3 > /proc/sys/vm/drop_caches
Кроме этого, можно включить режим изоляции групп, обеспечивающий более строгую изоляцию между группами за счет снижения пропускной способности ввода-вывода. Когда изоляция групп выключена, то справедливое распределение ресурсов обеспечивается только для рабочей нагрузки с последовательным доступом. По умолчанию режим изоляции групп включен, что обеспечивает справедливое распределение ресурсов при вводе-выводе со случайным доступом. Для включения режима изоляции групп следует выполнить команду
~]# echo 1 > /sys/block/<диск>/queue/iosched/group_isolation
где <диск> — это имя устройства, например, sda.
Подсистема cpu отвечает за управление доступом контрольных групп к процессорам. Планирование доступа осуществляется в зависимости от перечисленных ниже параметров, каждый из которых представлен в виде псевдофайла в файловой системе контрольных групп:
- cpu.shares
Целое число, определяющее относительную долю процессорного времени, предоставляемого задачам контрольной группы. Например, задачи в двух контрольных группах, для которых значение cpu.shares равно 1, будут получать равное время доступа к процессору, а задачи в контрольной группе, где параметр cpu.shares имеет значение 2, будут получать в два раза больше времени.
- cpu.rt_runtime_us
Значение этого параметра, заданное в микросекундах, определяет для задач контрольной группы, имеющих приоритет реального времени, максимальную продолжительность непрерывного использования ресурсов процессора. Установка этого параметра позволяет предотвратить монополизацию доступа к процессору со стороны задач одной контрольной группы. Если задачи контрольной группы должны иметь возможность получать доступ к процессору на 4 секунды каждые 5 секунд, то можно установить значение параметра cpu.rt_runtime_us равным 4000000, а параметра cpu.rt_period_us равным 5000000.
- cpu.rt_period_us
Значение этого параметра, заданное в микросекундах, определяет для задач контрольной группы, имеющих приоритет реального времени, то, с какой регулярностью ресурсы процессора будут перераспределяться в их пользу. Если задачи контрольной группы должны иметь возможность получать доступ к процессору на 4 секунды каждые 5 секунд, то можно установить значение параметра cpu.rt_runtime_us равным 4000000, а параметра cpu.rt_period_us равным 5000000.
Подсистема cpuacct создает очеты об использовании процессорных ресурсов задачами контрольной группы и дочерних подгрупп. Существует три типа отчетов:
- cpuacct.usage
Возвращает суммарное время (в наносекундах), в течение которого процессорные ресурсы были заняты обработкой задач контрольной группы (включая задачи на нижних уровнях иерархии).
Для того, чтобы сбросить счетчик cpuacct.usage, выполните следующую команду:
~]# echo 0 > /cgroups/cpuacct/cpuacct.usage
Эта команда также сбрасывает значение счетчика cpuacct.usage_percpu.
- cpuacct.stat
Возвращает суммарное процессорное время, проведенное задачами контрольной группы (включая задачи на низких уровнях иерархии) в пользовательском и системном режимах. Отчет предоставляется в виде двух строк:
user — процессорное время, потребленное задачами в пользовательском режиме.
system — процессорное время, потребленное задачами в системном режиме (режиме ядра).
Процессорное время указывается в единицах, определенных переменной USER_HZ.
- cpuacct.usage_percpu
Возвращает процессорное время (в наносекундах), потребленное задачами контрольной группы (включая задачи на нижних уровнях иерархии) на каждом процессоре.
Подсистема cpuset позволяет выделять контрольным группам процессоры и узлы памяти. Ниже перечислены параметры cpuset. Каждый параметр представлен в виде псевдофайла в виртуальной файловой системе контрольных групп.
У некоторых подсистем существуют обязательные параметры. Если такая подсистема подключена к контрольной группе, то ее обязательные параметры необходимо определить до того, как в контрольную группу можно будет переносить задачи. Так, например, прежде чем переносить задачи в контрольную группу, использующую подсистему cpuset, в ней надо определить параметры cpuset.cpus и cpuset.mems.
- cpuset.cpus (обязательный)
Определяет список процессоров, к которым имеют доступ задачи данной контрольной группы. Номера процессоров в списке разделяются запятой. Для обозначения диапазона используется дефис. Например, список
0-2,16
представляет процессоры 0, 1, 2 и 16.
- cpuset.mems (обязательный)
Определяет список узлов памяти, к которым разрешен доступ задачам данной контрольной группы. Номера узлов в списке разделяются запятой. Для обозначения диапазона используется дефис. Например, список
0-2,16
представляет узлы памяти 0, 1, 2 и 16.
- cpuset.memory_migrate
Содержит флаг (0 или 1), определяющий нужно ли переносить страницы памяти на другой узел при изменении значений в файле cpuset.mems. По умолчанию эта функциональность отключена (0) и страницы остаются на исходном узле, даже если узел не включен в обновленный список в файле cpuset.mems. Если же флаг установлен (1), то страницы будут перенесены на узлы памяти, перечисленные в новом списке из файла cpuset.mems. При этом по возможности будет поддерживаться их относительное размещение; так, например, при наличии свободного места страницы памяти со второго узла в исходном списке будут перенесены на второй узел в обновленном списке cpuset.mems.
- cpuset.cpu_exclusive
Содержит флаг (0 или 1), исключающий возможность включения процессоров, перечисленных в cpuset.cpus, в какие-либо иные cpuset-наборы, отличные от данного, а так же его предков или потомков. По умолчанию (значение 0) процессоры могут включаться в разные cpuset-наборы.
- cpuset.mem_exclusive
Содержит флаг (0 или 1), определяющий возможность включения узлов памяти, перечисленных в cpuset.mems, в какие-либо иные cpuset-наборы. По умолчанию (значение 0) узлы памяти могут входить в разные cpuset-наборы. Их резервирование для одного cpuset-набора (значение 1) функционально эквивалентно жесткому делению памяти с помощью установки флага в файле cpuset.mem_hardwall.
- cpuset.mem_hardwall
Содержит флаг (0 или 1), запрещающий ядру выделять страницы памяти или буфера данных где-либо, кроме узлов памяти данного cpuset-набора. По умолчанию (значение 0) страницы и буфера данных могут совместно использоваться процессами, принадлежащими разным пользователям. В режиме жесткого деления памяти (значение 1) все выделение памяти для задач производится отдельно.
- cpuset.memory_pressure
Этот файл доступен только для чтения и содержит среднее значение нагрузки на память, создаваемую процессами, работающими на данном наборе процессоров. Значение файла обновляется автоматически, если включен флаг cpuset.memory_pressure_enabled. В противном случае оно равно нулю.
- cpuset.memory_pressure_enabled
Содержит флаг (0 или 1), определяющий должна ли система вычислять нагрузку на память, создаваемую процессами данной контрольной группы. Значения рассчитываются умножением числа попыток высвобождения занятой памяти в секунду на 1000 и становятся доступными через файл cpuset.memory_pressure.
- cpuset.memory_spread_page
Содержит флаг (0 или 1), определяющий должно ли производиться равномерное распределение буферов файловой системы между всеми узлами памяти, выделенными данному cpuset-набору. По умолчанию (значение 0) равномерное распределение не выполняется, и буфера размещаются на том же узле памяти, где работает создающий их процесс.
- cpuset.memory_spread_slab
Содержит флаг (0 или 1), определяющий должно ли производиться равномерное распределение в пределах cpuset-набора slab-кэшей ядра для поддержки операций ввода-вывода файлов. По умолчанию (значение 0) равномерное распределение не выполняется, и slab-кэши размещаются на том же узле памяти, где работает создающий их процесс.
- cpuset.sched_load_balance
Содержит флаг (0 или 1), определяющий должна ли производиться балансировка нагрузки между процессорами, включенных в cpuset-набор. По умолчанию (значение 1) ядро равномерно распределяет нагрузку на все процессоры путем перемещения процессов на менее загруженные процессоры.
Отметим, что установка значения этого флага в контрольной группе не будет иметь никакого эффекта, если балансировка нагрузки включена в одной из ее родительских контрольных групп, так как в этом случае балансировка уже выполняется на более высоком уровне иерархии. Таким образом, чтобы отключить балансировку нагрузки в контрольной группе, необходимо отключить ее у всех предков данной контрольной группы. При этом следует оценить, нужна ли балансировка нагрузки в соседних контрольных группах на том же уровне иерархии.
- cpuset.sched_relax_domain_level
Содержит целое значение от -1 до небольшого положительного числа, определяющее число процессоров, между которыми будет распределяться нагрузка. Это значение не используется, если отключен флаг cpuset.sched_load_balance.
Точное определение воздействия этого числа зависит от архитектуры, но приведенные ниже значения являются достаточно типичными:
Значения параметра cpuset.sched_relax_domain_level
| Значение | Воздействие |
|---|
-1 | Использовать для балансировки нагрузки системное значение по умолчанию |
0 | Не выполнять немедленную балансировку нагрузки; делать это только периодически |
1 | Немедленно балансировать нагрузку между потоками одного процессорного ядра |
2 | Немедленно балансировать нагрузку между соседними ядрами процессора |
3 | Немедленно балансировать нагрузку между процессорами на одном узле или blade-модуле |
4 | Немедленно балансировать нагрузку между несколькими процессорами в системах с неоднородным доступом к памяти (NUMA) |
5 | Немедленно балансировать нагрузку между всеми процессорами в NUMA-системах |
Подсистема devices отвечает за предоставление доступа к устройствам со стороны задач контрольной группы.
- devices.allow
Задает устройства, к которым разрешен доступ задачам контрольной группы. Каждая запись состоит из четырех полей:
тип,
старший_номер,
младший_номер и
доступ. Значение полей
тип,
старший_номер и
младший_номер определены в
списке устройств Linux (см.
http://www.kernel.org/doc/Documentation/devices.txt).
- тип
Допустимые значения поля тип:
a — применяется ко всем устройствам, как к символьным, так и к блочным;
b — задает блочное устройство;
c — задает символьное устройство.
- старший_номер, младший_номер
Поля старший_номер и младший_номер однозначно идентифицируют устройства Linux. Их значения описаны в списке устройств Linux. Поля разделяются двоеточием. Например, старший номер 8 соответствует SCSI-дискам, а младший номер 1 соответствует первому разделу на первом SCSI-диске; следовательно, 8:1 однозначно определяет раздел, представленный в файловой системе как /dev/sda1.
Звездочка (знак «*») может использоваться для обозначения любого старшего или младшего номера устройства. Например, 9:* обозначает все RAID-устройства, а *:* — все устройства.
- доступ
Значение поля доступ задается последовательностью из одной или нескольких перечисленных ниже букв:
r — разрешает задачам осуществлять чтение из заданного устройства;
w — разрешает задачам осуществлять запись на заданное устройство;
m — разрешает задачам создавать файлы устройств, если они еще не существуют.
Например, если значение поля доступ задано как r, то задачи могут выполнять только чтение с заданного устройства, а если значение задано как rw, то задачи могут осуществлять чтение и запись.
- devices.deny
Задает устройства, к которым запрещен доступ задачам контрольной группы. Формат записей аналогичен devices.allow.
- devices.list
Возвращает список устройств, для которых были определены правила доступа со стороны задач контрольной группы.
Подсистема freezer отвечает за приостанавку и возобновление задач контрольной группы.
- freezer.state
Параметр имеет три возможных значения:
FROZEN — задачи контрольной группы приостановлены.
FREEZING — система находится в процессе приостановки задач контрольной группы.
THAWED — исполнение задач контрольной группы возобновлено.
Чтобы приостановить работу конкретного процесса, надо сделать следующее:
Переместите процесс в контрольную группу той иерархии, к которой подключена подсистема freezer.
Остановите работу этой группы, тем самым приостановив работу процесса, который в ней находится.
Нельзя перемещать процесс в уже остановленную ("замороженную") контрольную группу.
Стоит отметить, что значения FROZEN и THAWED могут быть записаны в параметр freezer.state, а значение FREEZING записывать нельзя, его можно только прочитать.
Подсистема memory позволяет накладывать ограничения и автоматически создает отчеты об использовании ресурсов памяти задачами контрольной группы.
- memory.stat
Возвращает большое число параметров использования памяти, описанных в следующей таблице:
Таблица 3.1. Значения, представленные в файле memory.stat
|
Значение
|
Описание
|
|---|
cache
|
размер кэша страниц (в байтах), включая tmpfs (shmem)
|
rss
|
размер кэша анонимной памяти и своппинга (в байтах), не включая tmpfs (shmem)
|
mapped_file
|
размер файлов, отображенных в память с помощью системного вызова mmap (в байтах), включая tmpfs (shmem
|
pgpgin
|
число страниц, скаченных в память
|
pgpgout
|
число страниц, откаченных из памяти
|
swap
|
размер использованной области своппинга (в байтах)
|
active_anon
|
размер кэша анонимной памяти и своппинга в активном LRU-списке[] (в байтах), включая tmpfs (shmem)
|
inactive_anon
|
размер кэша анонимной памяти и своппинга в неактивном LRU-списке (в байтах), включая tmpfs (shmem)
|
active_file
|
размер памяти (в байтах), находящейся в активном LRU-списке, для которой имеется копия данных в файлах
|
inactive_file
|
размер памяти (в байтах), находящейся в неактивном LRU-списке, для которой имеется копия данных в файлах
|
unevictable
|
размер памяти (в байтах), которая не может быть высвобождена
|
hierarchical_memory_limit
|
предельный размер памяти (в байтах), который может использоваться в иерархии, куда входит контрольная группа с подсистемой memory
|
hierarchical_memsw_limit
|
предельный размер памяти и области своппинга (в байтах), который может использоваться в иерархии, куда входит контрольная группа с подсистемой memory
|
Кроме этого, все параметры за исключением hierarchical_memory_limit и hierarchical_memsw_limit имеют аналоги с префиксом total_, которые возвращают данные не только о самой контрольной группе, но и о всех ее дочерних группах. Например, параметр swap возвращает данные о использовании области своппинга контрольной группой, а параметр total_swap — о суммарном использовании области своппинга контрольной группой и всеми ее дочерними группами.
При интерпретации значений, представленных в файле memory.stat, следует учитывать, что они соотносятся следующим образом:
active_anon + inactive_anon = (анонимная память) + (кэш файлов для tmpfs) + (кэш своппинга)
Следовательно, active_anon + inactive_anon ≠ rss, поскольку rss не включает в себя tmpfs.
active_file + inactive_file = cache - размер tmpfs
- memory.usage_in_bytes
Возвращает суммарный размер памяти (в байтах), занятый процессами контрольной группы.
- memory.memsw.usage_in_bytes
Возвращает суммарный размер памяти и области своппинга (в байтах), занятый процессами контрольной группы.
- memory.max_usage_in_bytes
Возвращает максимальный размер памяти (в байтах), использованный процессами контрольной группы.
- memory.memsw.max_usage_in_bytes
Возвращает максимальный размер памяти и области своппинга (в байтах), использованный процессами контрольной группы.
- memory.limit_in_bytes
Устанавливает ограничение на максимальный размер памяти, который может использоваться в режиме пользователя (включая кэш файлов). По умолчанию размер задается в байтах. Для указания более крупных единиц измерения можно использовать суффиксы — k или K для килобайтов, m или M для мегабайтов и g или G для гигабайтов.
Параметр memory.limit_in_bytes нельзя использовать для ограничения корневой контрольной группы. Только группы, стоящие на более низких ступенях иерархии, могут быть ограничены в потреблении ресурсов памяти.
Для отмены ограничений в файл memory.limit_in_bytes следует записать значение -1.
- memory.memsw.limit_in_bytes
Устанавливает ограничение на максимальный суммарный размер используемой памяти и области своппинга. По умолчанию размер задается в байтах. Для указания более крупных единиц измерения можно использовать суффиксы — k или K для килобайтов, m или M для мегабайтов и g или G для гигабайтов.
Параметр memory.memsw.limit_in_bytes нельзя использовать для ограничения корневой контрольной группы. Только группы, стоящие на более низких ступенях иерархии, могут быть ограничены в потреблении ресурсов памяти.
Для отмены ограничений в файл memory.memsw.limit_in_bytes следует записать значение -1.
Важно отметить, что параметр memory.limit_in_bytes должен быть установлен до того, как установлен параметрmemory.memsw.limit_in_bytes. Попытка установить параметры в обратном порядке приведет к ошибке. Это объясняется тем, что параметр memory.memsw.limit_in_bytes становится доступным только после того, как исчерпаны ресурсы памяти, ограниченные параметром memory.limit_in_bytes.
Рассмотрим следующий пример. Установки параметров memory.limit_in_bytes = 2G и memory.memsw.limit_in_bytes = 4G для некоторой контрольной группы позволят процессам этой группы занять 2 ГБ оперативной памяти и, после исчерпания этого предела, занять еще 2 ГБ в области своппинга. Параметр memory.memsw.limit_in_bytes ограничивает суммарный размер оперативной памяти и области своппинга. Потенциально процессы контрольной группы, в которой не установлено значение параметра memory.memsw.limit_in_bytes, могут занять всю имеющуюся область своппинга (после исчерпания лимита на оперативную память) и вызвать аварийную ситуацию нехватки памяти из-за отсутствия свободного пространства в области своппинга.
Порядок, в котором устанавливаются значения параметров memory.limit_in_bytes и memory.memsw.limit_in_bytes в файле /etc/cgconfig.conf, тоже важен. Ниже приведен пример правильной конфигурации:
memory {
memory.limit_in_bytes = 1G;
memory.memsw.limit_in_bytes = 1G;
}
- memory.failcnt
Счетчик случаев достижения предела потребления ресурсов памяти, установленного параметром memory.limit_in_bytes.
- memory.memsw.failcnt
Счетчик случаев достижения предела суммарного потребления ресурсов памяти и своппинга, установленного параметром memory.memsw.limit_in_bytes.
- memory.force_empty
При установке параметра в 0 освобождает память от всех страниц, использованных задачами контрольной группы. Этот интерфейс может использоваться только тогда, когда в контрольной группе нет задач. Если память не может быть освобождена, то по возможности она перемещается в родительскую контрольную группу. Перед удалением контрольной группы рекомендуется использовать параметр memory.force_empty, чтобы избежать перемещения в родительскую контрольную группу неиспользуемых страниц кэша памяти.
- memory.swappiness
Устанавливает коэффициент, используемый ядром системы для определения предпочтения своппинга памяти процессов, входящих в контрольную группу, перед высвобождением памяти из кэша страничной памяти. Этот параметр для контрольной группы работает точно так же, как параметр, установленный в файле /proc/sys/vm/swappiness для всей системыю. По умолчанию значение равно 60. Значения меньше 60 уменьшают тенденцию ядра откачивать память процессов в своппинг, значения больше 60 увеличивают тенденцию своппинга, а значения больше 100 разрешают ядру откачивать в своппинг страницы памяти, входящие в адресное пространство процессов, принадлежащих данной контрольной группе.
Отметим, что значение 0 не предоствращает откачку страниц памяти процессов в своппинг. Откачка может произойти при недостатке системной памяти, так как глобальная логика управления виртуальной памятью не учитывает контрольные группы. Чтобы полностью запретить откачку страниц, вместо механизма контрольных групп рекомендуется использовать сисменый вызов mlock().
Нельзя менять параметр memory.swappiness для следующих групп:
для корневой контрольной группы, которая использует значение из файла /proc/sys/vm/swappiness;
для контрольной группы, у которой есть дочернии группы.
- memory.use_hierarchy
Содержит флаг (значение 0 или 1), определяющий должен ли производиться сквозной учет потребления ресурсов памяти в иерархии контрольных групп. Если учет разрешен (значение 1), то подсистема memory высвобождает память дочерних процессов при превышении родительским процессом установленных пределов потребления памяти. По умолчанию (значение 0) высвобождение памяти в дочерних задачах не производится.
Подсистема net_cls присваивает сетевым пакетам идентификатор класса (classid), который позволяет контроллеру трафика tc отличать пакеты, поступающие из заданной контрольной группы. Контроллер трафика может быть настроен так, чтобы назначать разные приоритеты пакетам из разных контрольных групп.
- net_cls.classid
Псевдофайл net_cls.classid содержит число, идентифицирующее обработчик трафика. При чтении из файла net_cls.classid значение classid представляется в десятичном формате, в то время как при записи нужно использовать шестнадцатиричный формат. Например, число 0x100001 представляет собой идентификатор обработчика, который в формате пакета iproute2 обычно записывается как 10:1. При чтении из файла net_cls.classid это значение будет представлено как число 1048577.
Формат идентификатора обработчика трафика следующий: 0xAAAABBBB, где AAAA — старший номер в шестнадцатиричной системе, а BBBB — младший номер. Нули в начале можно опускать. Число 0x10001 — это тоже, что 0x00010001, и представляет собой идентификатор обработчика 1:1. Ниже приведен пример установки обработчика 10:1 в файл net_cls.classid:
~]# echo 0x100001 > /cgroup/net_cls/red/net_cls.classid
~]# cat /cgroup/net_cls/red/net_cls.classid
1048577
Справочная страница tc содержит информацию о том, как настроить контроллер трафика для использования идентификаторов обработчиков, присваиваемых сетевым пакетам подсистемой net_cls.
Подсистема net_prio позволяет для каждого сетевого интерфейса динамически назначать приоритет трафика, исходящего из приложений контрольной группы. Сетевой приоритет — это число, которое используется внутри системы и сетевыми устройствами. Сетевой приоритет позволяет поразному обрабатывать пакеты при их отсылке, постановке в очередь и отбрасывании. Сетевой приоритет может быть установлен командой tc, но это выходит за пределы данного руководства (см. справочные страницы по команде tc).
Обычно приложения устанавливают приоритет своего трафика с помощью опции сокета SO_PRIORITY. Однако очень часто в приложениях не предусмотрена возможность установки приоритета, или же приоритет трафика зависит от окружающей среды, где используется приложение, и не может быть определен заранее.
Используя подсистему net_prio, администратор может поместить процесс в контрольную группу, которая определяет приоритет исходящего трафика для заданного сетевого интерфейса.
Чтобы использовать подсистему net_prio, ядро операционной системы должно быть собрано со следующей опцией:
~]$ grep CONFIG_NETPRIO_CGROUP /boot/config-`uname -r`
CONFIG_NETPRIO_CGROUP=m
Модуль netprio_cgroup должен быть загружен. Это можно сделать так:
~]# modprobe netprio_cgroup
Чтобы убедиться, что модуль netprio_cgroup загружен, выполните следующую команду:
~]$ lsmod | grep netprio_cgroup
Как только разрешена работа подсистемы net_prio, это становится видно в списке из файла /proc/cgroups.
- net_prio.prioidx
Файл доступный только на чтение, в котором содержится число, используемое ядром для внутреннего представления данной контрольной группы.
- net_prio.ifpriomap
Содержит карту приоритетов, назначенных исходящему трафику, порождаемому процессами данной контрольной группы, и покидающему систему через перечисленные сетевые интерфейсы. Эта карта представляет собой список пар: <сетевой_интерфейс> <приоритет>
~]# cat /cgroups/net_prio/iscsi/net_prio.ifpriomap
eth0 5
eth1 4
eth2 6
Содержимое файла net_prio.ifpriomap можно менять с помощью команды echo. Например:
~]# echo "eth0 5" > /cgroups/net_prio/iscsi/net_prio.ifpriomap
Приведенная выше команда назначает приоритет 5 сетевому трафику, исходящему от процессов контрольной группы iscsi в иерархии net_prio и передаваемому через сетевой интерфейс eth0. Родительская контрольная группа также имеет доступный для записи файл net_prio.ifpriomap, который можно использовать для установки приоритета по умолчанию.
Подсистема ns предоставляет возможность группировать процессы в отдельные пространства имен. Процессы могут взаимодействовать друг с другом внутри пространства имен, но они изолированы от процессов, работающих в других пространствах имен. В тех случаях, когда пространства имен используются для реализации виртуализации на уровне операционной системы, они называются контейнерами.
3.11. Дополнительные ресурсы
Документация по подсистемам ядра
Перечисленные ниже файлы располагаются в каталоге /usr/share/doc/kernel-doc-<версия_ядра>/Documentation/cgroups/ (доступном после установки пакета kernel-doc).
Подсистема blkio — blkio-controller.txt
Подсистема cpuacct — cpuacct.txt
Подсистема cpuset — cpusets.txt
Подсистема devices — devices.txt
Подсистема freezer — freezer-subsystem.txt
Подсистема memory — memory.txt
Подсистема net_prio — net_prio.txt
Глава 4. Примеры использования
В этой главе приведены примеры использования возможностей контрольных групп.
4.1. Приоритизация ввода-вывода базы данных
Распределение ресурсов между базами данных с учетом их приоритета можно осуществить путем запуска каждого сервера баз данных в своей собственной виртуальной машине. Рассмотрим следующий пример. На системе работают две базы данных, каждая в своей вируальной машине KVM. Одна база данных имеет высокий приоритет, а другая низкий. Когда оба сервера баз данных работают одновременно, то у каждого из них падает скорость ввода-вывода, так как они поровну делят общую пропускную способность машины.
Рисунок 4.1, «Скорость ввода-вывода без явного распределения ресурсов» иллюстрирует этот случай — как только начинает работать сервер низкоприоритетной базы данных (в момент времени около 45), скорость ввода-вывода у обеих баз данных становится примерно одинаковой.
Чтобы обеспечить приоритет более важной базы данных, она может быть включена в контрольную группу с большим числом зарезервированных операций ввода-вывода, а низкоприоритетная база данных — в контрольную группу с небольшим числом зарезервированных операций. Приведенная ниже последовательность шагов показывает, как это можно сделать. Она должна быть выполнена на хост-системе.
Процедура 4.1. Приоритизация ввода-вывода
Подключите подсистему blkio к контрольной группе /cgroup/blkio/:
~]# mkdir /cgroup/blkio
~]# mount -t cgroup -o blkio blkio /cgroup/blkio
Создайте контрольные группы для задач с высоким и низким приоритетом:
~]# mkdir /cgroup/blkio/high_prio
~]# mkdir /cgroup/blkio/low_prio
Получите идентификаторы процессов виртуальных машин, в которых работают базы данных, и поместите их в соответствующие контрольные группы. В данном примере VM_high представляет собой имя виртуальной машины с высокоприоритетной базой данных, а VM_low — имя виртуальной машины с низкоприоритетной базой данных. Например:
~]# ps -eLf | grep qemu | grep VM_high | awk '{print $4}' | while read pid; do echo $pid >> /cgroups/blkio/high_prio/tasks; done
~]# ps -eLf | grep qemu | grep VM_low | awk '{print $4}' | while read pid; do echo $pid >> /cgroups/blkio/low_prio/tasks; done
Установите соотношение 10:1 между контрольными группами high_prio и low_prio. Процессы в этих группах (то есть процессы, соответствующие виртуальным машинам, которые были добавлены в контрольные группы на предыдущем шаге) сразу начнут использовать только отведенные им ресурсы.
~]# echo 1000 > /cgroup/blkio/high_prio/blkio.weight
~]# echo 100 > /cgroup/blkio/low_prio/blkio.weight
В нашем примере контрольная группа low_prio разрешает низкоприоритетной базе данных использовать только около 10% операций ввода-вывода, в то время как контрольная группа high_prio разрешает высокоприоритетной базе данных использовать до 90% операций ввода-вывода.
Рисунок 4.2, «Скорость ввода-вывода при явном распределении ресурсов» иллюстрирует результат ограничения низкоприоритетной базы данных и приоритизации более важной базы данных. Как только серверы баз данных помещены в соответствующие контрольные группы (в момент времени около 75), пропускная способность ввода-вывода делится между серверами в соотношении 10:1.
Потребление ресурсов низкоприоритетной базой данных может быть ограничено другим способом — путем торможения ввода-вывода на блочное устройство. Этот способ позволяет установить предельное число операций чтения и записи в единицу времени доступное базе данных. Подробная информация по подсистеме
blkio представлена в
Раздел 3.1, «Подсистема blkio».
4.2. Распределение вычислительных ресурсов и памяти между группами
Когда одна система совместно используется многими пользователями, бывает полезно иметь возможность веделять некоторым пользователям больше ресурсов, чем другим. Рассмотрим следующий пример: в гипотетической компании есть три подразделения — финансовый отдел, отдел продаж и инженерный отдел. Если во всех подразделениях выполняются задачи, требующие больших вычислительных ресурсов и много памяти, то поскольку инженеры используют систему и ее ресурсы для большего числа задач, чем специалисты других подразделений, было бы логично выделить им больше ресурсов.
Механизм контрольных групп предоставляет возможность ограничивать потребление ресурсов каждой группой пользователей. Предположим, что в системе заведены следующие пользователи:
~]$ grep home /etc/passwd
martin:x:1000:1000::/home/martin:/bin/bash
john:x:1001:1001::/home/john:/bin/bash
mark:x:1002:1002::/home/mark:/bin/bash
peter:x:1003:1003::/home/peter:/bin/bash
jenn:x:1004:1004::/home/jenn:/bin/bash
mike:x:1005:1005::/home/mike:/bin/bash
Эти пользователи были включены в следующие группы:
~]$ grep -e "100[678]" /etc/group
finance:x:1006:jenn,john
sales:x:1007:mark,martin
engineering:x:1008:peter,mike
Процедура 4.2. Распределение вычислительных ресурсов и памяти между группами пользователей
Определим конфигурацию подсистем и контрольных групп в файле /etc/cgconfig.conf следующим образом:
mount {
cpu = /cgroup/cpu_and_mem;
cpuacct = /cgroup/cpu_and_mem;
memory = /cgroup/cpu_and_mem;
}
group finance {
cpu {
cpu.shares="250";
}
cpuacct {
cpuacct.usage="0";
}
memory {
memory.limit_in_bytes="2G";
memory.memsw.limit_in_bytes="3G";
}
}
group sales {
cpu {
cpu.shares="250";
}
cpuacct {
cpuacct.usage="0";
}
memory {
memory.limit_in_bytes="4G";
memory.memsw.limit_in_bytes="6G";
}
}
group engineering {
cpu {
cpu.shares="500";
}
cpuacct {
cpuacct.usage="0";
}
memory {
memory.limit_in_bytes="8G";
memory.memsw.limit_in_bytes="16G";
}
}
Загрузка с данным конфигурационным файлом приводит к подключению подсистем
cpu,
cpuacct и
memory к одной контрольной группе —
cpu_and_mem (см.
Глава 3, Подсистемы и параметры настройки). Затем в
cpu_and_mem создается иерархия, состоящая из трех контрольных групп:
sales,
finance и
engineering. В каждой из этих групп устанавливаются свои параметры подсистем:
cpu — параметр cpu.shares определяет долю вычислительных ресурсов доступных процессам в каждой из контрольных групп. Установка значений параметра как 250, 250 и 500 для контрольных групп finance, sales и engineering означает, что процессы, запущенные в этих группах, могут потреблять вычислительные ресурсы в соотношении 1:1:2. Отметим, что когда в системе готов к работе только один процесс, то он потребляет столько вычислительных ресурсов, сколько ему требуется, вне зависимости от того, к какой контрольной группе он относится. Ограничения на потребление вычислительных ресурсов вступают в силу только тогда, когда несколько процессов конкурируют за ресурсы процессоров.
cpuacct — параметр cpuacct.usage="0" сбрасывает значения в файлах cpuacct.usage и cpuacct.usage_percpu. В них представлено процессорное время (в наносекундах), использованное процессами контрольной группы.
memory — параметр memory.limit_in_bytes задает ограничение на общий размер оперативной памяти доступной процессам, входящим в одну контрольную группу. В данном случае процессам, запущенным в группе finance, доступно 2 ГБ, процессам в sales — 4 ГБ, а процессам в engineering — 8 ГБ. Параметр memory.memsw.limit_in_bytes определяет общий размер оперативной памяти и области своппинга, который процессам разрешено использовать. Если какой-то процесс в контрольной группе finance достигнет 2 ГБ предел оперативной памяти, ему будет разрешено использовать еще 1 ГБ в области своппинга, то есть до общего установленного предела в 3 ГБ.
Для определения правил, используемых демоном cgrulesengd при перераспределении процессов по контрольным группам, в файле /etc/cgrules.conf нужно указать следующее:
#<user/group> <controller(s)> <cgroup>
@finance cpu,cpuacct,memory finance
@sales cpu,cpuacct,memory sales
@engineering cpu,cpuacct,memory engineering
Такая конфигурация создает правила, назначающие системной группе (например, @finance) контроллеры ресурсов, которые она может использовать (cpu, cpuacct, memory), и контрольную группу (finance), куда будут помещаться все процессы, запущенные пользователями, входящими в данную системную группу.
В нашем примере, когда демон cgrulesengd, запускаемый командой service cgred start, находит процесс пользователя, входящего в системную группу finance (например, процесс пользователя jenn), идентификатор этого процесса автоматически записывается в файл /cgroup/cpu_and_mem/finance/tasks, и процесс подвергается ограничениям, установленным для контрольной группы finance.
Для создания иерархии котрольных групп и установки их параметров запустите службу cgconfig:
~]# service cgconfig start
Starting cgconfig service: [ OK ]
Запустите службу cgred, чтобы демон cgrulesengd начал определять процессы, принадлежащие пользователями системных групп, сконфигурированных в файле /etc/cgrules.conf:
~]# service cgred start
Starting CGroup Rules Engine Daemon: [ OK ]
Отметим, что служба, которая запускает демон cgrulesengd, называется cgred.
Для того, чтобы приведенная выше конфигурация действовала после перезагрузки, нужно разрешить запуск служб cgconfig и cgred по умолчанию:
~]# chkconfig cgconfig on
~]# chkconfig cgred on
Чтобы проверить данную конфигурацию, нужно запустить процессы, интенсивно потребляющие вычислительные ресурсы или ресурсы оперативной памяти, и пронаблюдать результат, например, с помощью программы top. Для проверки управления вычислительными ресурсами из под каждого пользователя запустите команду dd следующим образом:
~]$ dd if=/dev/zero of=/dev/null bs=1024k
Эта команда читает из файла /dev/zero и пишет в файл /dev/null блоками по 1024 КБ. Программа top покажет примерно следующее:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8201 peter 20 0 103m 1676 556 R 24.9 0.2 0:04.18 dd
8202 mike 20 0 103m 1672 556 R 24.9 0.2 0:03.47 dd
8199 jenn 20 0 103m 1676 556 R 12.6 0.2 0:02.87 dd
8200 john 20 0 103m 1676 556 R 12.6 0.2 0:02.20 dd
8197 martin 20 0 103m 1672 556 R 12.6 0.2 0:05.56 dd
8198 mark 20 0 103m 1672 556 R 12.3 0.2 0:04.28 dd
⋮
Все процессы правильно размещены по контрольным группам и потребляют вычислительные ресурсы только в отведенных им пределах. Если остановить все процессы за исключением двух, принадлежащих группам finance и engineering, то освободившиеся ресурсы пропорционально распределяются между ними:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8202 mike 20 0 103m 1676 556 R 66.4 0.2 0:06.35 dd
8200 john 20 0 103m 1672 556 R 33.2 0.2 0:05.08 dd
⋮
Альтернативный способ
Поскольку демон
cgrulesengd перемещает процесс в контрольную группу только после того, как выполнились условия, определенные правилами в файле
/etc/cgrules.conf, в течение нескольких миллисекунд процесс может выполняться вне назначенной ему контрольной группы. Альтернативный способ перемещения процессов в контрольные группы связан с использованием PAM-модуля
pam_cgroup.so. Этот модуль перемещает процессы в имеющиеся контрольные группы в соответствии с правилами, определенными в файле
/etc/cgrules.conf. Последовательность шагов для конфигурации PAM-модуля
pam_cgroup.so описана в
Процедура 4.3, «Использование PAM-модуля для перемещения процессов в контрольные группы».
Процедура 4.3. Использование PAM-модуля для перемещения процессов в контрольные группы
Установите пакет libcgroup-pam:
~]# yum install libcgroup-pam
Убедитесь, что PAM-модуль установлен и доступен:
~]# ls /lib64/security/pam_cgroup.so
/lib64/security/pam_cgroup.so
Отметим, что на 32-битных системах этот модуль расположен в каталоге /lib/security/.
Добавьте следующую строку в файл /etc/pam.d/su, чтобы модуль pam_cgroup.so использовался каждый раз, когда выполняется команда su:
session optional pam_cgroup.so
Чтобы задействовать данную конфигурацию, все пользователи, которых касаются установки контрольных групп в файле /etc/cgrules.conf, должны выйти из системы.
При использовании PAM-модуля pam_cgroup.so служба cgred может быть отключена.